Chapter 23 Exercises of Regression and Other Stories
23.1 Overview
Data for examples and assignments in this and other chapters are at www.stat.columbia.edu/~gelman/regression/. See Appendix A for an introduction to R, the software you will use for computing.
23.1.1 From design to decision
Figure 1.9 displays the prototype for a paper “helicopter.” The goal of this assignment is to design a helicopter that takes as long as possible to reach the floor when dropped from a fixed height, for example 8 feet. The helicopters are restricted to have the general form shown in the sketch. No additional folds, creases, or perforations are allowed. The wing length and the wing width of the helicopter are the only two design parameters, that is, the only two aspects of the helicopter that can be changed. The body width and length must remain the same for all helicopters. A metal paper clip is attached to the bottom of the helicopter. Here are some comments from previous students who were given this assignment:
Rich creased the wings too much and the helicopters dropped like a rock, turned upside down, turned sideways, etc. Helis seem to react very positively to added length. Too much width seems to make the helis unstable. They flip-flop during flight. Andy proposes to use an index card to make a template for folding the base into thirds. After practicing, we decided to switch jobs. It worked better with Yee timing and John dropping. 3 – 2 – 1 – GO.
Your instructor will hand out 25 half-sheets of paper and 2 paper clips to each group of students. The body width will be one-third of the width of the sheets, so the wing width can be anywhere from \(\frac{1}{6}\) to \(\frac{1}{2}\) of the body width; see Figure 1.9a. The body length will be specified by the instructor. For example, if the sheets are U.S.-sized (\(8.5\times5.5\) inches) and the body length is set to 3 inches, then the wing width could be anywhere from 0.91 to 2.75 inches and the wing length could be anywhere from 0 to 5.5 inches. In this assignment you can experiment using your 25 half-sheets and 10 paper clips. You can make each half-sheet into only one helicopter. But you are allowed to design sequentially, setting the wing width and body length for each helicopter given the data you have already recorded. Take a few measurements using each helicopter, each time dropping it from the required height and timing how long it takes to land.
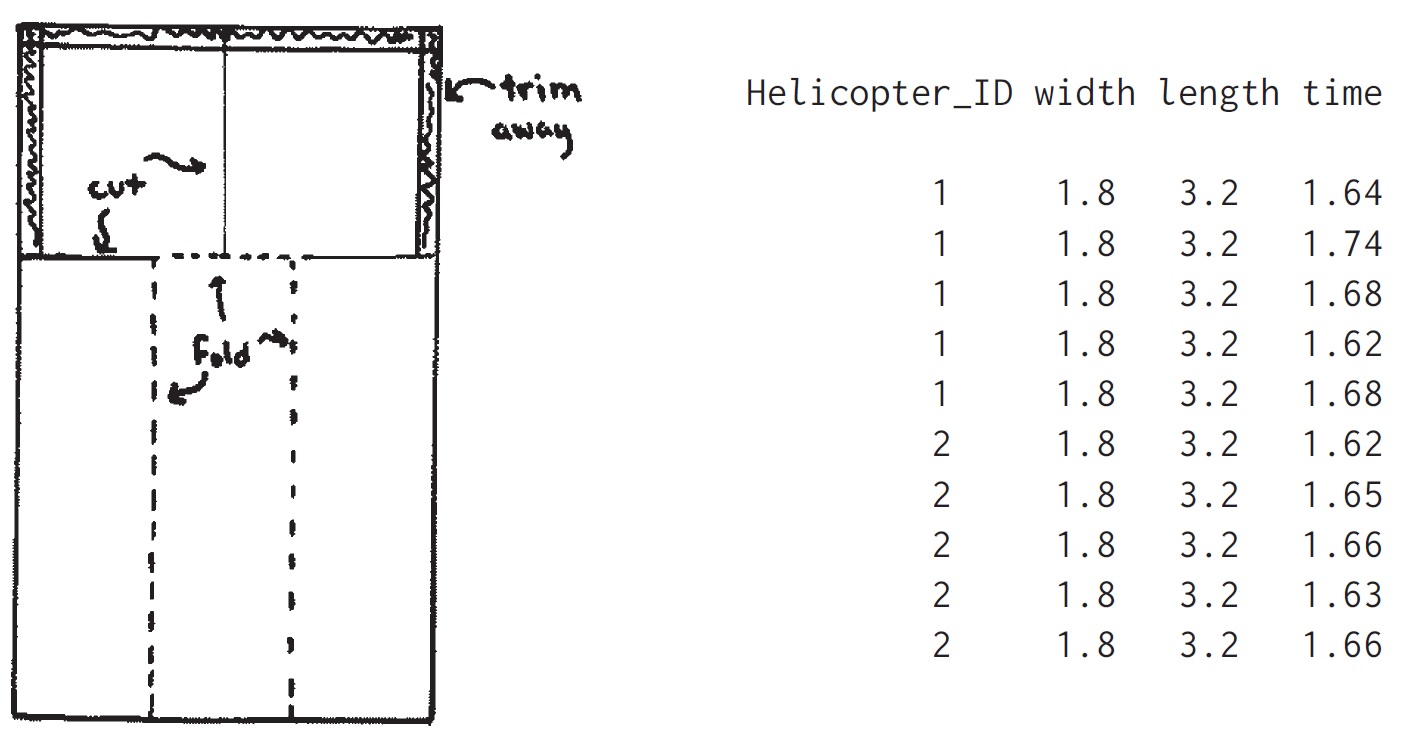
Figure 23.1: (a) Diagram for making a “helicopter” from half a sheet of paper and a paper clip. The long segments on the left and right are folded toward the middle, and the resulting long 3-ply strip is held together by a paper clip. One of the two segments at the top is folded forward and the other backward. The helicopter spins in the air when dropped. (b) Data file showing flight times, in seconds, for 5 flights each of two identical helicopters with wing width 1.8 inches and wing length 3.2 inches dropped from a height of approximately 8 feet. From Gelman and Nolan (2017).
library(tidyverse)
file_helicopters <- here::here("data/ros-master/Helicopters/data/helicopters.txt")
helicopters <-
file_helicopters %>%
read.table(header = TRUE) %>%
as_tibble(.name_repair = str_to_lower)23.1.1.1 (a)
Record the wing width and body length for each of your 25 helicopters along with your time measurements, all in a file in which each observation is in its own row, following the pattern of helicopters.txt in the folder Helicopters, also shown in Figure 1.9b.
# The wing length and the wing width of the helicopter are the only two design variables, that is, the only two measurements on the helicopter that can be changed. The body width and length must remain the same for all helicopters.
# wing width 4.6 centimeters and wing length 8.2 centimeters
helicopters %>% arrange(time_sec) %>% mutate(
wing_width = c(seq(0.91, 2.75, 0.1), 2.75),
wing_length = sample(0:5.5, 20, replace=TRUE),
body_length = 3) %>%
select(helicopter_id, time_sec, wing_width,
body_length, everything())-> helicopters## Error in select(., helicopter_id, time_sec, wing_width, body_length, everything()): unused arguments (helicopter_id, time_sec, wing_width, body_length, everything())23.1.1.2 (b)
Graph your data in a way that seems reasonable to you.
helicopters %>% mutate(
helicopter_id = as.factor(helicopter_id)) %>%
ggplot(aes(y = time_sec, x = wing_width,
group = helicopter_id,
color = helicopter_id,
fill = helicopter_id)) +
geom_point() + theme_bw() +
theme(legend.position = "bottom")## Error in FUN(X[[i]], ...): object 'wing_width' not found
23.1.1.3 (c)
Given your results, propose a design (wing width and length) that you think will maximize the helicopter’s expected time aloft. It is not necessary for you to fit a formal regression model here, but you should think about the general concerns of regression. The above description is adapted from Gelman and Nolan (2017, section 20.4). See Box, Hunter, and Hunter (2005) for a more advanced statistical treatment of this sort of problem.
##
## Call:
## lm(formula = time_sec ~ width_cm + length_cm + helicopter_id,
## data = helicopters)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.0560 -0.0285 -0.0005 0.0175 0.0750
##
## Coefficients: (2 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.68400 0.02713 62.080 <2e-16 ***
## width_cm NA NA NA NA
## length_cm NA NA NA NA
## helicopter_id -0.01900 0.01716 -1.107 0.283
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.03836 on 18 degrees of freedom
## Multiple R-squared: 0.06379, Adjusted R-squared: 0.01178
## F-statistic: 1.227 on 1 and 18 DF, p-value: 0.282723.1.2 Sketching a regression model and data
Figure 1.1b shows data corresponding to the fitted line y = 46.3 + 3.0x with residual standard deviation 3.9, and values of x ranging roughly from 0 to 4%.
23.1.2.1 (a)
Sketch hypothetical data with the same range of x but corresponding to the line \(y = 30 + 10x\) with residual standard deviation 3.9.
##
## Call:
## lm(formula = vote_est1 ~ growth_est1, data = q1.2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.2023 -5.7359 -0.8188 3.8556 22.5308
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48.4689 2.7733 17.477 6.63e-11 ***
## growth_est1 1.9846 0.6469 3.068 0.00835 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.81 on 14 degrees of freedom
## Multiple R-squared: 0.402, Adjusted R-squared: 0.3593
## F-statistic: 9.411 on 1 and 14 DF, p-value: 0.00835## Error in select(., growth_est1, growth_est2, vote_est1, vote_est2): unused arguments (growth_est1, growth_est2, vote_est1, vote_est2)23.1.2.2 (b)
Sketch hypothetical data with the same range of x but corresponding to the line \(y = 30 + 10x\) with residual standard deviation 10.
##
## Call:
## lm(formula = vote_est2 ~ growth_est2, data = q1.2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -25.834 -3.974 0.102 5.189 32.754
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 50.1440 3.7354 13.424 2.19e-09 ***
## growth_est2 0.3817 0.3549 1.075 0.3
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 14.76 on 14 degrees of freedom
## Multiple R-squared: 0.07631, Adjusted R-squared: 0.01034
## F-statistic: 1.157 on 1 and 14 DF, p-value: 0.3003## Error in select(., growth_est1, growth_est2, vote_est1, vote_est2): unused arguments (growth_est1, growth_est2, vote_est1, vote_est2)23.1.3 Goals of regression
Download some data on a topic of interest to you. Without graphing the data or performing any statistical analysis, discuss how you might use these data to do the following things:
23.1.3.1 (a) Fit a regression to estimate a relationship of interest.
With V-Dem dataset, I will fit the model, \(\text{EDI} \sim \beta X\), which \(X\) includes various covariates that can affect the levels of democracy, which existing studies have found.
23.1.3.2 (b) Use regression to adjust for differences between treatment and control groups.
23.1.3.3 (c) Use a regression to make predictions.
23.1.4 Problems of statistics
Give examples of applied statistics problems of interest to you in which there are challenges in:
23.1.4.1 (a) Generalizing from sample to population.
23.1.4.2 (b) Generalizing from treatment to control group.
23.1.4.3 (c) Generalizing from observed measurements to the underlying constructs of interest.
23.1.5 Goals of regression
Give examples of applied statistics problems of interest to you in which the goals are:
23.1.5.1 (a) Forecasting/classification.
23.1.5.2 (b) Exploring associations.
23.1.5.3 (c) Extrapolation.
23.1.5.4 (d) Causal inference.
23.2 Causal inference
Find a real-world example of interest with a treatment group, control group, a pre-treatment predictor, and a post-treatment predictor. Make a graph like Figure 1.8 using the data from this example.
23.3 Statistics as generalization
Find a published paper on a topic of interest where you feel there has been insufficient attention to:
23.3.0.1 (a) Generalizing from sample to population.
23.3.0.2 (b) Generalizing from treatment to control group.
23.3.0.3 (c) Generalizing from observed measurements to the underlying constructs of interest.
23.4 Statistics as generalization
Find a published paper on a topic of interest where you feel the following issues have been addressed well:
23.4.0.1 (a) Generalizing from sample to population.
23.4.0.2 (b) Generalizing from treatment to control group.
23.4.0.3 (c) Generalizing from observed measurements to the underlying constructs of interest.
23.5 A problem with linear models
Consider the helicopter design experiment in Exercise 1.1. Suppose you were to construct 25 helicopters, measure their falling times, fit a linear model predicting that outcome given wing width and body length: \[ \text{time} = \beta_0 + \beta_1 ∗ \text{width} + \beta_2 ∗ \text{length}+ \text{error}, \]
and then use the fitted model \(\text{time} = \beta_0 + \beta_1 ∗ \text{width} + \beta_2 ∗ \text{length}\) to estimate the values of wing width and body length that will maximize expected time aloft.
23.5.0.1 (a) Why will this approach fail?
23.5.0.2 (b) Suggest a better model to fit that would not have this problem.
23.5.1 Working through your own example
Download or collect some data on a topic of interest of to you. You can use this example to work though the concepts and methods covered in the book, so the example should be worth your time and should have some complexity. This assignment continues throughout the book as the final exercise of each chapter. For this first exercise, discuss your applied goals in studying this example and how the data can address these goals.
23.6 Some basic methods in mathematics and probability
23.6.1 Weighted averages
A survey is conducted in a certain city regarding support for increased property taxes to fund schools. In this survey, higher taxes are supported by 50% of respondents aged 18–29, 60% of respondents aged 30–44, 40% of respondents aged 45–64, and 30% of respondents aged 65 and up. Assume there is no nonresponse.Suppose the sample includes 200 respondents aged 18–29, 250 aged 30–44, 300 aged 45–64, and 250 aged 65+. Use the weighted average formula to compute the proportion of respondents in the sample who support higher taxes.
## # A tibble: 4 x 6
## age support n total weight supportweighted
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 18-29 0.5 200 1000 0.2 0.1
## 2 30-44 0.6 250 1000 0.25 0.15
## 3 45-64 0.4 300 1000 0.3 0.12
## 4 65 and up 0.3 250 1000 0.25 0.075## # A tibble: 1 x 1
## sum
## <dbl>
## 1 0.44523.6.2 Weighted averages
Continuing the previous exercise, suppose you would like to estimate the proportion of all adults in the population who support higher taxes, so you take a weighted average as in Section 3.1. Give a set of weights for the four age categories so that the estimated proportion who support higher taxes for all adults in the city is 40%.
## # A tibble: 1 x 1
## sum
## <dbl>
## 1 0.40523.6.3 Probability distributions
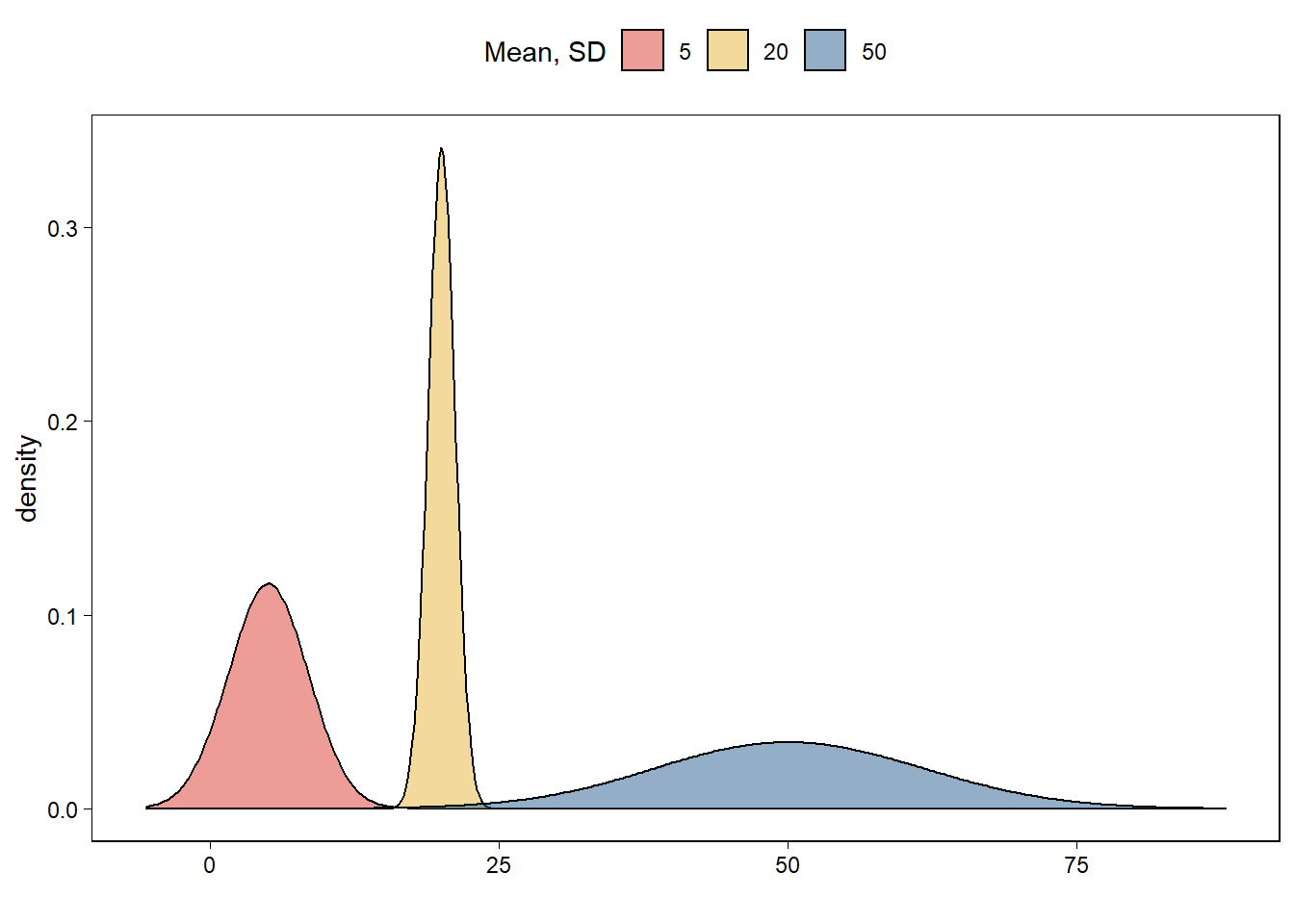
Using R, graph probability densities for the normal distribution, plotting several different curves corresponding to different choices of mean and standard deviation parameters.
23.6.4 Probability distributions
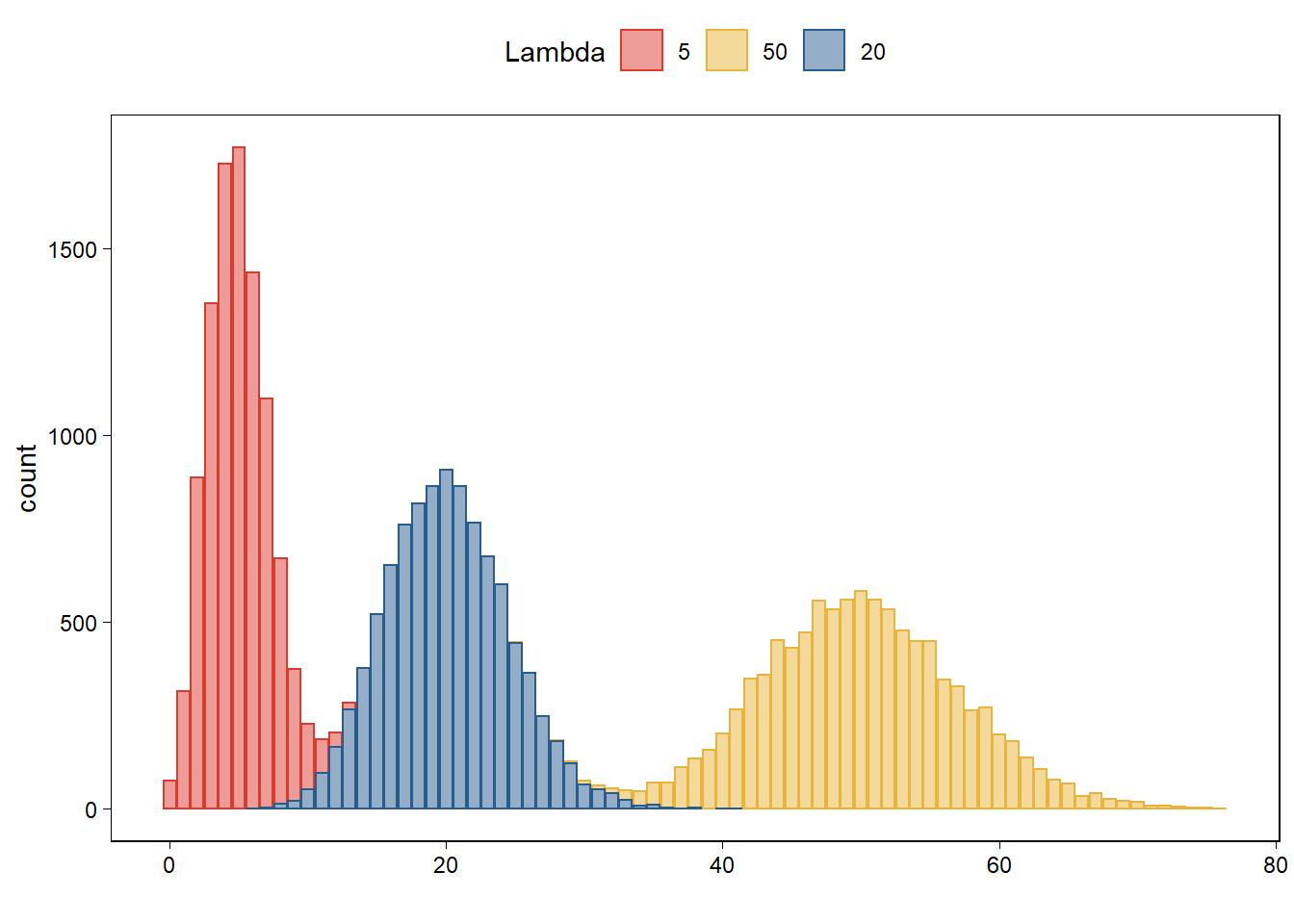
Using a bar plot in R, graph the Poisson distribution with parameter 3.5.
23.6.5 Probability distributions
Using a bar plot in R, graph the binomial distribution with n = 20 and p = 0.3.
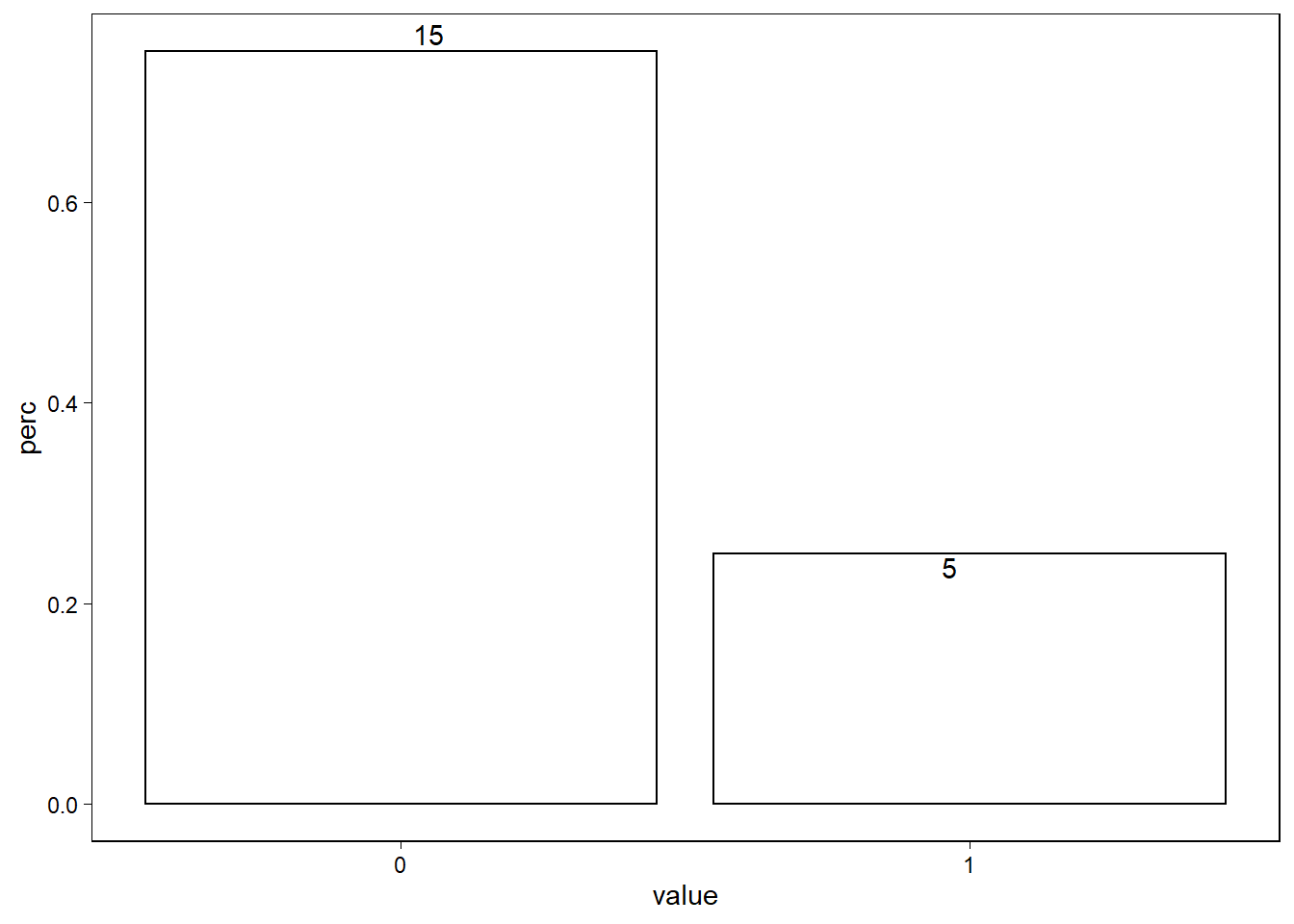
23.6.6 Linear transformations
A test is graded from 0 to 50, with an average score of 35 and a standard deviation of 10. For comparison to other tests, it would be convenient to rescale to a mean of 100 and standard deviation of 15.
23.6.6.1 (a)
Labeling the original test scores as x and the desired rescaled test score as \(y\), come up with a linear transformation, that is, values of a and b so that the rescaled scores \(y = a + bx\) have a mean of 100 and a standard deviation of 15.
23.6.6.2 (b)
What is the range of possible values of this rescaled score \(y\)?
23.6.6.3 (c)
Plot the line showing y vs. x.
23.6.7 Linear transformations
Continuing the previous exercise, there is another linear transformation that also rescales the scores to have mean 100 and standard deviation 15. What is it, and why would you not want to use it for this purpose?
23.6.9 Comparison of distributions
Find an example in the scientific literature of the effect of treatment on some continuous outcome, and make a graph similar to Figure 3.9 showing the estimated population shift in the potential outcomes under a constant treatment effect.
23.6.10 Working through your own example
Continuing the example from Exercises 1.10 and 2.10, consider a deterministic model on the linear or logarithmic scale that would arise in this topic. Graph the model and discuss its relevance to your problem.