Linear-Model Diagnostics & Statistical Significance and Confidence Intervals
Linear-Model Diagnostics & Statistical Significance and Confidence Intervals
여기서는 먼저 선형회귀(linear regression) 모델에 대해 간단하게 리뷰하고 어떤 경우에 선형회귀분석을 사용하는 것이 바람직한지를 진단하는 기준들에 대해 살펴보도록 하겠습니다. 그리고 나아가 간단하게 종속변수가 연속형이 아닌, 0과 1일 경우에 선형회귀모델을 적용한 경우, 선형확률모형(linear probability models)에 대해서도 살펴보도록 하겠습니다.
- 선형확률모형을 통해 우리는 종속변수가 연속형이 아닐 때, 즉 예측변수와 종속변수 간 선형 관계를 가정할 수 없을 때, OLS를 사용하는 것이 왜 ‘비효율적’(inefficient)이고 그 추정치가 BLUE1일 수 없는지를 알 수 있습니다.
Review: What is a linear model?
선형회귀모델은 몇 가지 가정들에 바탕을 두고 있습니다. 이 가정들을 통틀어 가우스 마르코프 가정(Gaus-Markov assumptions)라고 합니다. 여기서는 편의상 다중선형회귀모델의 가정이라는 의미로 MLR(Multiple linear regression)의 가정, MLR1부터 MLR5로 표현하겠습니다.
MLR1. 선형회귀분석은 다차항(polynomial terms) 등을 포함하여 비선형성(non-linearity)도 모델에 반영할 수 있지만 기본적으로는 종속변수와 예측변수 간의 관계가 선형일 것 등을 가정합니다. 여기서 언급한 선형회귀모델이 표현할 수 있는 비선형성의 문제는 이 다음 주차의 상호작용항에 관한 내용에서 자세히 살펴보실 수 있습니다.
MLR2. 잔차(residuals)는 정규적으로 분포되어 있어야 합니다.—잔차의 정규성
MLR3-4. 데이터는 iid 가정(assumed indendently and identically distributed)을 충족시켜야 합니다.
MLR3. 데이터의 각 확률변수는 상호독립적이며(independent),
MLR4. 모두 동일한 확률분포를 가지고(등분산성, identical) 정규분포를 따른다(normally distributed)는 가정입니다. 즉, 데이터의 각 확률변수들과 잔차는 서로 상관하지 않아야 합니다.
MLR5. 등분산성(homoscedasticity)
- 모든 잔차(오차)는 같은 분산을 가진다는 가정입니다.
이처럼 선형회귀모델은 강한 가정들을 위에 성립합니다. 또한 OLS, 제곱합 최소화 방법을 통한 추정치는 자료에 민감하다는 특징을 가집니다. 소수의 극단적인 이탈치들이 잔차의 제곱합을 크게 변화시킬 수 있기 때문입니다. 따라서 우리에게는 두 가지 선택지가 존재합니다.
OLS를 통한 추정을 포기하는 것OLS로 자료를 분석하되, 데이터를 “진단”(diagnose)해보는 것
Fox (2016, 266)은 회귀모델을 수립하기에 앞서 데이터에 대한 주의 깊은 분석을 통해 여러 문제들을 예상하고 미리 대처할 수 있다고 밝히고 있습니다. 대표적인 문제들로는,
이탈치 (outliers)
정규적으로 분포되지 않은 잔차(non-normally distributed errors)
일정하지 않은 분산(non-constant variance)
비선형성(non-linearity)
공선성(collinearity)
등이 있다고 할 수 있습니다.
Statistical Significanc
Linear-Model Diagnostics
이탈치
이탈치(outliers)는 설명변수의 값 중 다른 값들과는 달리 유독 튀는, 극단적인 값을 갖는 관측치를 의미합니다. 단, 단변량 분석에서의 이탈치와 양변량, 혹은 다변량에서의 이탈치는 차이가 있습니다.
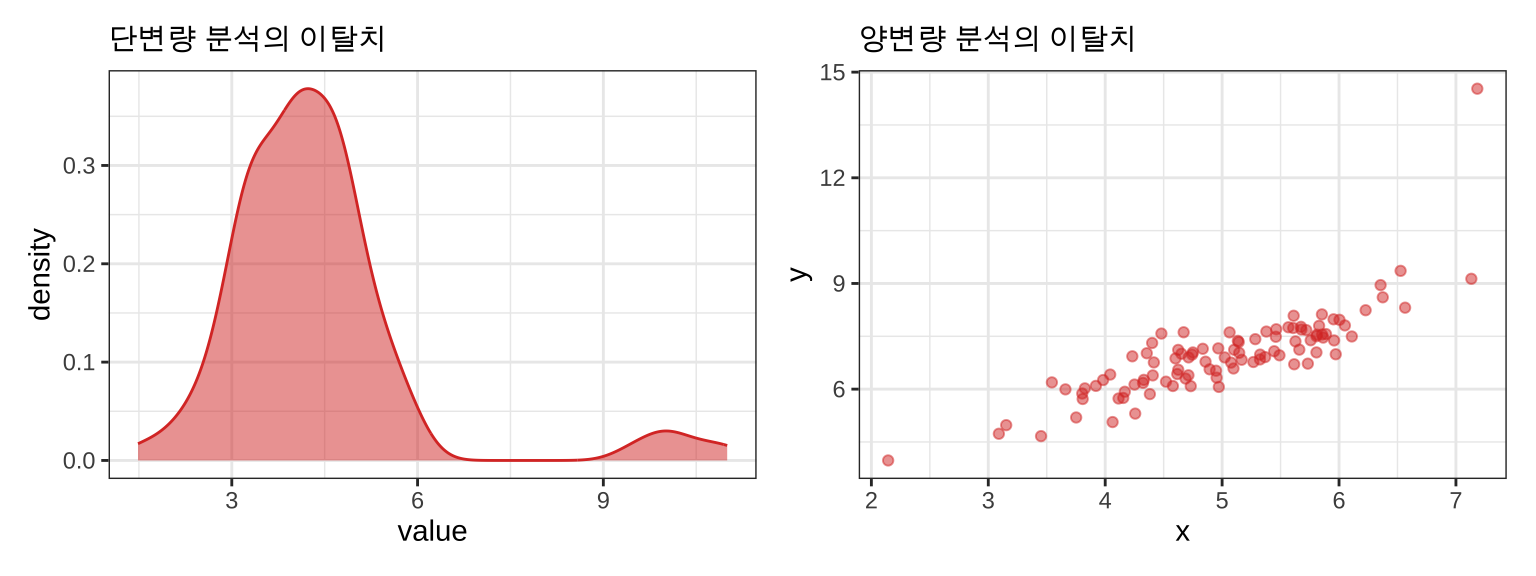
그리고 이탈치는 회귀모델의 추정에 큰 영향을 미칠 수 있습니다.
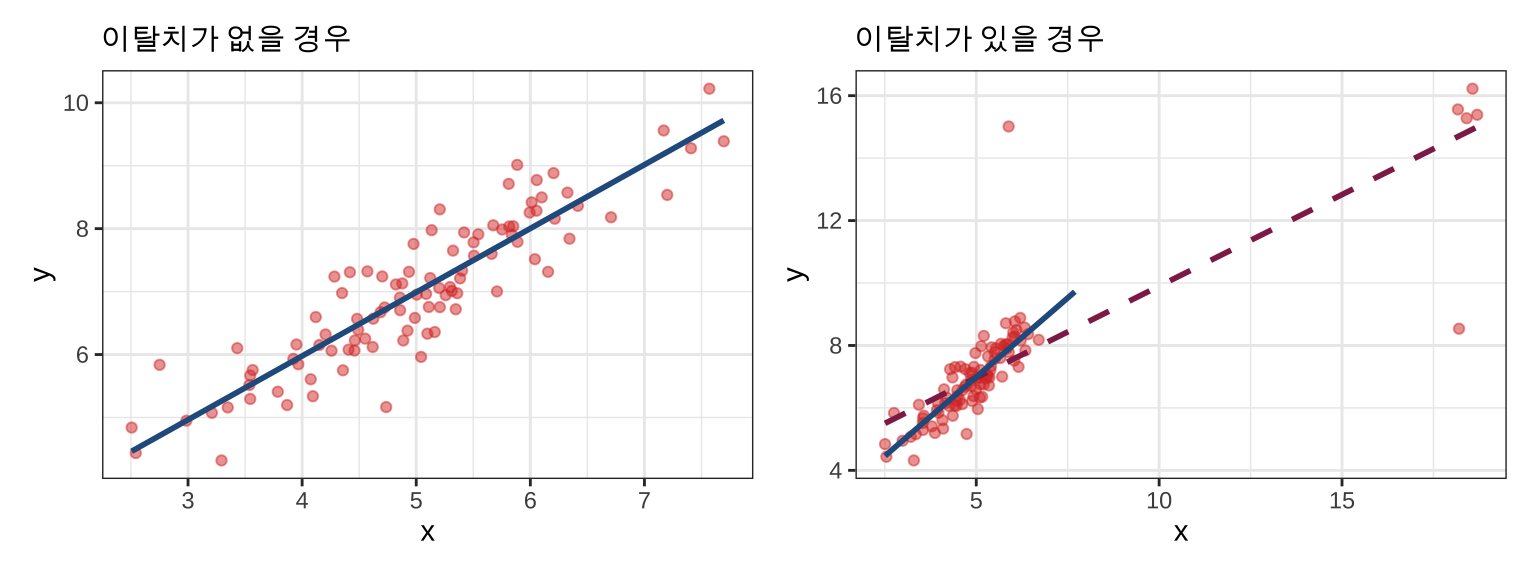
회귀선의 적합도(fit)에 영향 (Influence)을 미치기 때문에, 이탈치와 같이 “이례적인” 데이터는 제곱합(least square)에 문제가 될 수 있습니다.
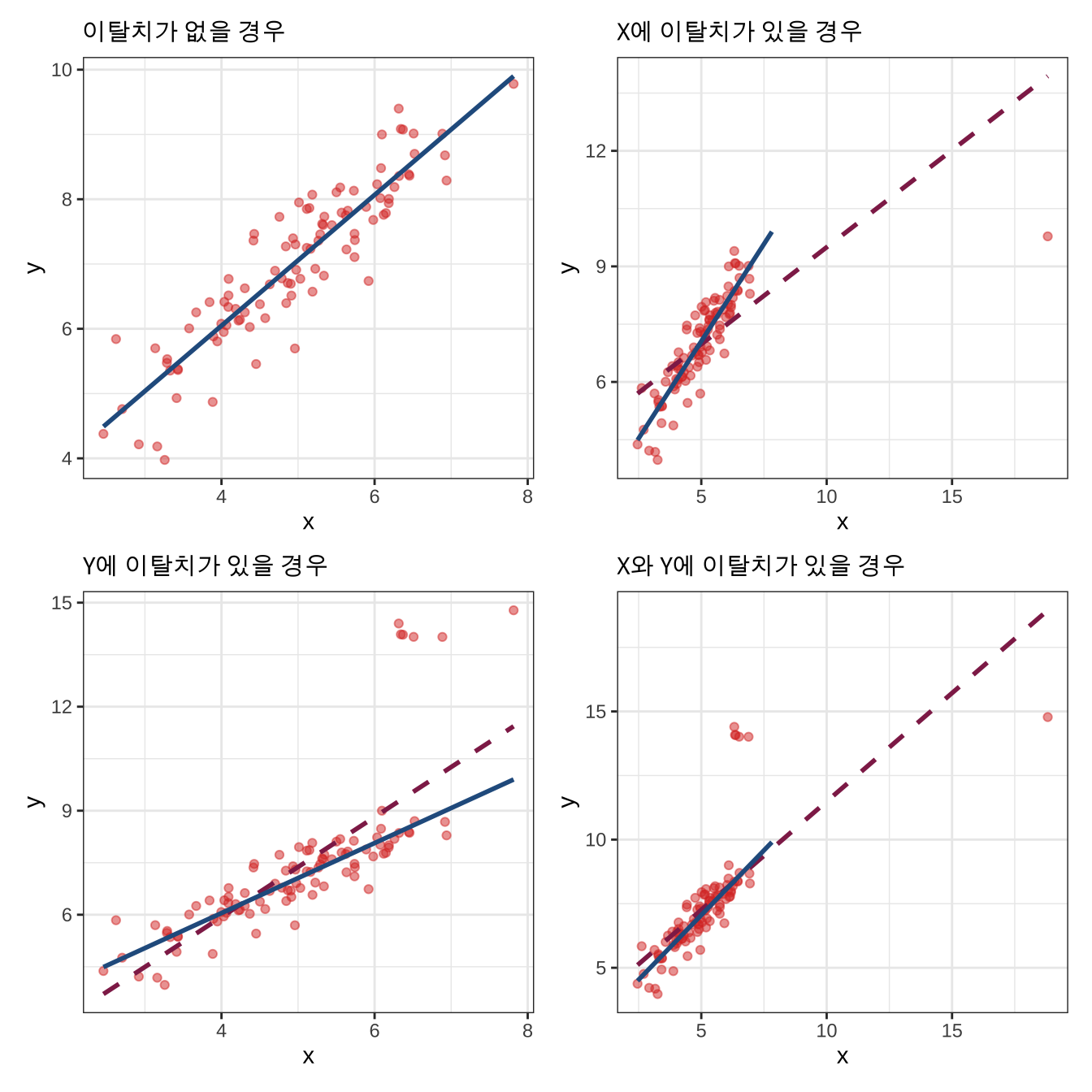
\(\text{Influence} = \text{Leverage}\times\text{Discrepancy}\)
\(\text{Leverage} = X\text{에서 관측치들이 떨어져 있는 정도}\)
\(h_i\)는 레버리지를 측정하는 대표적인 지표로, \(x_i\)와 \(\bar{x}\) 간의 거리를 보여줍니다.
\(h_i = \frac{1}{n}+\frac{(X_i-\bar{X})^2}{\sum^{n}_{j=1}(X_j-\bar{X})^2}\)
\(\text{Discrepancy} = Y\text{에서 관측치들이 떨어져 있는 정도}\)
큰 레버리지를 가진 관측치는 작은 잔차를 가지는 경향이 있습니다.
\(V(E_i) = \sigma^{2}_{\epsilon} (1-h_i)\)
표준화된 잔차: \(E_i = \frac{\sigma^{2}_{\epsilon} (1-h_i)}{S_E\sqrt{1-h}}\)
스튜던트화 잔차: \(E_i^{*} = \frac{\sigma^{2}_{\epsilon} (1-h_i)}{S_E(-i)\sqrt{1-h}}\)
스튜던트화 잔차 = 표준화 잔차에서 \(i\)번째 관측치를 제외한 결과
특정한 관측치가 아니라 1부터 \(n\) 사이의 아무 관측치를 제외하고 \(E_i\)와 \(E_i^{*}\)의 비교
가설검정의 문제처럼 이탈치를 식별(outlier identification)하여, 다른 관측치들과 유의미한 차이의 거리를 가진 값을 관측치로 “결정”하는 기법입니다.
\(\text{Influence} = \text{hat-value}\times\text{residuals}\)
이같은 이탈치의 영향력을 측정하는 대표적인 지표는 쿡스의 거리(Cook’s distance)가 있습니다.
\[ \frac{E^{\prime2}}{k+1} \times \frac{h_i}{1-h_i} = \text{Residual}\times\text{Leverage} \]
한번에 하나씩 관측치를 표본에서 제거합니다.
\(n-1\)의 표본을 대상으로 회귀모델을 다시 분석합니다.
\(i\)번째 표본이 제거되었을 때의 전체 예측값이 얼마나 변화하였는지를 분석합니다.
쿡스의 거리는 평균적으로 데이터셋에서 문제가 될 것이라고 생각되는 관측치가 제거되었을 때, 예측된 \(y\)의 값이 어떻게 변할지를 살펴보는 지표입니다.
비정규적으로 분포된 오차
Fox (2016, 297)에 따르면 “최소제곱합 추정법의 타당성(validity)이 강력하다 할지라도 그 효율성(efficiency)은 그렇지 않”습니다. 여러 개의 정점을 가진 오차의 분포(multimodal error distribution)는 데이터를 몇 가지 집단으로 나누는 설명변수가 누락되었을 가능성을 시사합니다. 즉, 데이터에 체계적인 영향을 미치는 변수를 빼먹었을 수 있다는 신호입니다.
오차의 비정규성을 검정하기 위해서 일단 여기서는 단변량 관계를 살펴보도록 하겠습니다. 분위비교플롯(quantile-cimparison plot)은 스튜던트화 잔차의 표본 분포를 단위정규분포의 분위와 비교 및 시각화하는 플롯입니다. 이른바 Q-Q 플롯을 통해 우리는 잔차 분포의 꼬리 부분이 어떻게 나타나는지를 효과적으로 보여줄 수 있습니다.
일정하지 않은 오차의 분산
일정한 오차의 분산을 동분산성 혹은 등분산성(homoscedasticity)라고 하며, 일정하지 않은 분산을 이분산성(heteroscadasticity)라고 합니다. OLS 추정치의 결과가 가지는 효율성과 타당성은 (1) 표본 크기, (2) 변동량(variations)의 정도, (3) \(X\) 값이 어떻게 이루어져 있는지, 그리고 (4) 오차 분산과 \(X\)의 관계 등에 의해 영향을 받습니다. 당연히 표본의 크기가 크면 클수록 트렌드가 존재한다면 그 패턴이 더 선명하게 나타날 것이니 보다 정확하게 추정할 수 있을 것이구요, 변수의 변화량이 많을수록 설명할 수 있는 것도 많을 것입니다. 이분산성은 오차의 분산이 일정하지 않아 \(X\)와 체계적인 관계를 맺을 수 있는 확률이 더 높다는 점에서 OLS 결과에 영향을 미칠 수 있습니다.
이분산성을 확인하기 위해서는 잔차 플롯(residual plot)을 살펴보아야 합니다. 대개 스튜던트화된 잔차와 예측값 간의 관계를 보거나, 혹은 절대값을 취한 스튜던트화 잔차와 예측값의 관계를 살펴봅니다. 논리는 간단합니다. 예측값은 우리가 이미 가지고 있는 \(X\)로 \(Y\)를 추정한 결과입니다. 잔차는 그 예측값과 실제 관측치 간의 차이를 보여주죠. 만약 예측값과 잔차 간에 체계적 관계가 존재한다면? 우리는 \(Y\)를 설명하기 위한 일련의 설명변수, \(X\)에 적절한 변수를 다 포함시키지 못한 것입니다. 통계적으로는 가장 큰 오차의 분산이 가장 작은 잔차의 분산보다 10배 이상 클 때 심각할 정도의 결과의 편향이 나타날 수 있다고 봅니다 (보수적으로는 4배를 기준으로 삼기도 함).
비선형성
\(Y\)와 \(X\) 간의 관계가 비선형일 때, 선형성을 가정한 선형회귀모델은 결과를 제대로 있습니다. 선형회귀모델의 회귀계수는 결과적으로 \(X\)의 한 단위 변화가 \(Y\)에 미치는 한계효과를 보여주는 것인데, 이 한계효과는 비선형적 관계를 단편적으로밖에 보여주지 못합니다. Fox (2016)은 성분잔차플롯(component-plus-residual plot)을 통해 변수들 간 관계의 비선형성 여부를 확인할 것을 주문합니다.
성분잔차플롯은 \(e + \hat{\beta}_{j} X_{j} \sim X_{j}\)의 관계를 보여주는 산포도입니다. \(\hat{\beta}_{j} X_{j}\)은 \(j\)번째 설명변수가 예측값에 기여하는, 계수값에 개별 설명변수의 관측치를 곱한 값입니다. 즉, 예측값에 오차를 더한 값과 개별 설명변수 간의 관계를 보여줌으로써, 만약 설명변수가 선형관계에 있다면 플롯은 \(\hat{beta}\)라는 기울기에 밀접하게 모인 관측치의 분포를 보여줄 것입니다. 비선형적이라면 선을 통과하기는 하지만 모여있지는 않은 휘어진 분포 등을 보여줄 것입니다.
공선성
공선성은 다른 문제들에 비해서는 상대적으로 문제시되지는 않습니다. 현실 세계에서 우리가 관측할 수 있는 통계치들, 표본의 값들이 공선성에서 자유로울 수는 없는데 만약 그렇다면 공선성이 어느 정도여야 선형회귀모델의 추정치가 편향되어 신뢰하기 어렵다고 판단할 수 있을까요?
먼저 설명변수들 간에 완벽한 공선성이 존재한다고 생각해보겠습니다. 이 경우, 최소제곱합으로 만들어진 모델은 유일한 해(solution), 계수를 가지지 못합니다. 왜냐하면 계수값에 대한 표집 분산이 무한대가 되기 때문입니다. 단순하게 설명하자면, \(Y\)를 설명하기 위한 각 \(X\)의 변량이 모두 동일하게 겹치므로 중복…중복… 그 결과 무한대나 다름 없는 해가 생기는 것입니다.
만약 공선성이 완전하지는 않지만 꽤 높은 수준으로 존재한다면 어떻게 될까요? 계수(_j$에 대한 표집 분산은 다음과 같이 추정되는데,
\[ Var(\beta_j) = \frac{1}{1-R^2_j}\times\frac{\sigma^2_{\epsilon}}{(n-1)S^2_j} \]
Fox (2016, 342)의 Figure 13.1에서 확인할 수 있듯이, “\(R_j\)가 0.9까지 도달하지 않는 한, 추정치의 정확성(precision)은 훼손되지 않”습니다.
다중선형회귀모델
선형회귀모델을 진단하기에 앞서 간단한 모델을 하나 만들어보도록 하겠습니다. ggplot2 패키지에서 제공하는 diamonds 데이터로 다중선형회귀모델을 만들도록 하겠습니다. 이 예제에서 사용할 종속변수는 바로 다이아몬드 데이터의 가격(price) 변수입니다. 따라서 가격 변수의 분포를 살펴보겠습니다.
library(ezpickr) # 다른 확장자의 파일을 R로 불러오기 위한 패키지
library(here) # 현재 작업디렉토리를 R-스크립트가 위치한 디렉토리로 자동설정하는 패키지
library(broom) # 통계분석 함수의 결과를 정연하게 정리해주는 패키지
library(ggfortify) # ggplot2 시각화를 도와주는 패키지
library(estimatr) # 로버스트 표준오차나 신뢰구간 등과 같은 추정치들을 계산해주는 패키지
library(patchwork)
library(futurevisions) # 시각화를 위한 컬러패키지
library(ggplot2)
library(tidyverse) # 데이터 관리 및 전처리를 위한 주요 패키지
df <- diamonds
df |>
ggplot(aes(price)) + geom_histogram()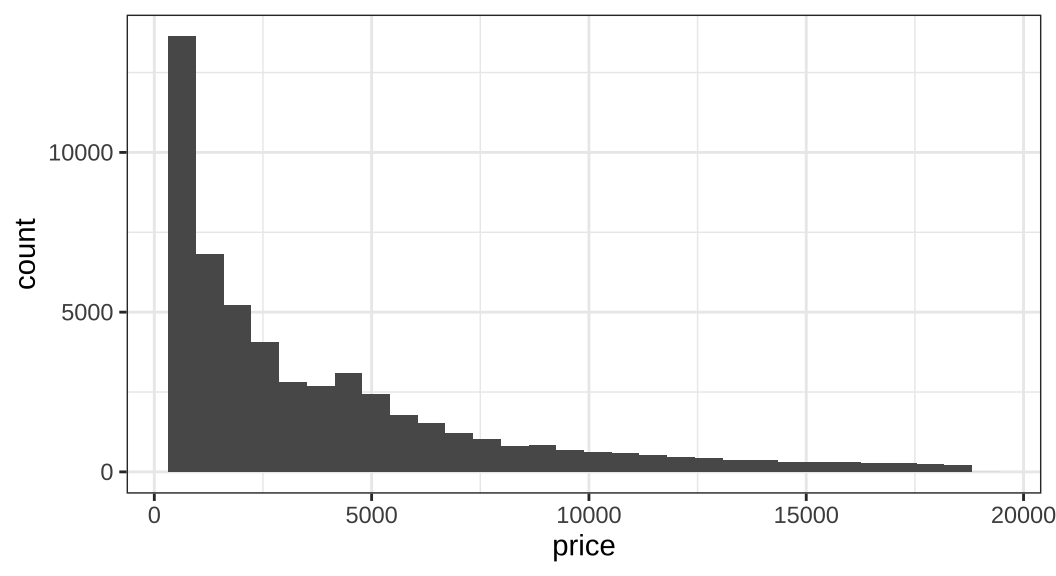
일단 전체 다이아몬드 데이터에서 가격 변수의 분포는 좌측으로 치우친(left-skewed) 것을 확인할 수 있습니다. 즉, OLS의 기본 가정에서 언급되었던 종속변수가 정규적으로 분포되어 있을 것이라는 가정이 위배된다 충분히 의심해볼 수 있습니다.
자, 이제는 이 df 데이터의 변수들을 필요에 따라 조작해주도록 하겠습니다.
sold의 경우는 예제이니까 30퍼센트의 확률로 팔린다 (1)가 나타나도록 이항분포에서 무작위 추출을 한 변수입니다.price_bin은 원래 숫자형 변수인price를 조건에 따라low, medium, high의 레이블을 갖는 요인형 변수로 조작하였습니다.
df <- df |>
mutate(
sold = rbinom(nrow(df), 1, 0.3),
price_bins = case_when(
price <= 2500L ~ 'low',
price > 2500L & price <= 7500L ~ 'medium',
price > 7500L ~ 'high',
TRUE ~ NA_character_
),
price_bins = factor(price_bins, levels = c('low', 'medium', 'high'))
)분석하게 용이하게 변수의 순서도 조금 손을 봐주도록 하겠습니다.
df <- df |> rowid_to_column() |>
dplyr::select(
rowid,
sold, carat, cut,
color, clarity, depth,
table, price, price_bins,
x, y, z)
head(df)# A tibble: 6 × 13
rowid sold carat cut color clarity depth table price price_bins x y
<int> <int> <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <fct> <dbl> <dbl>
1 1 1 0.23 Ideal E SI2 61.5 55 326 low 3.95 3.98
2 2 1 0.21 Prem… E SI1 59.8 61 326 low 3.89 3.84
3 3 0 0.23 Good E VS1 56.9 65 327 low 4.05 4.07
4 4 0 0.29 Prem… I VS2 62.4 58 334 low 4.2 4.23
5 5 0 0.31 Good J SI2 63.3 58 335 low 4.34 4.35
6 6 1 0.24 Very… J VVS2 62.8 57 336 low 3.94 3.96
# ℹ 1 more variable: z <dbl>이번에는 데이터 안에서 가격이 high인 다이아몬드가 몇 개나 있을지 세어보겠습니다. 이미 price_bin이라는 변수를 새로 만들어서 숫자형인 price가 얼마를 기준으로 초과할 때 high라고 할 수 있는지를 지정해 두었습니다.
df |> count(price_bins)# A tibble: 3 × 2
price_bins n
<fct> <int>
1 low 27542
2 medium 18016
3 high 8382그렇다면 각각의 가격 범주에서의 평균 가격은 어떻게 될까요?
df |> dplyr::select(price, price_bins) |>
group_by(price_bins) |>
summarise_all(mean, na.rm = T)# A tibble: 3 × 2
price_bins price
<fct> <dbl>
1 low 1153.
2 medium 4542.
3 high 11759.선형관계 살펴보기
여기까지가 대략적인 데이터의 기술분석이라고 한다면, 이제는 이번에는 다이아몬드의 무게(carot)와 가격 간의 관계를 살펴보도록 하겠습니다. 이번에는 통계치보다는 가시화된 플롯으로 그 결과를 구성해보도록 하겠습니다. x축에는 무게, y축에는 가격이 오도록 플롯을 그립니다.
df |>
ggplot(aes(x = carat, y = price)) +
geom_point(alpha = .05, color = futurevisions("mars")[3]) +
geom_smooth(method = 'lm', se = F, color = futurevisions("mars")[1]) +
coord_cartesian(ylim = c(-1000, 22000)) +
theme_bw() +
labs(
x = 'Carat of Diamond', y = 'Price of Diamond',
title = "Effect of Carat on Diamond Price"
) +
scale_y_continuous(labels = scales::dollar_format())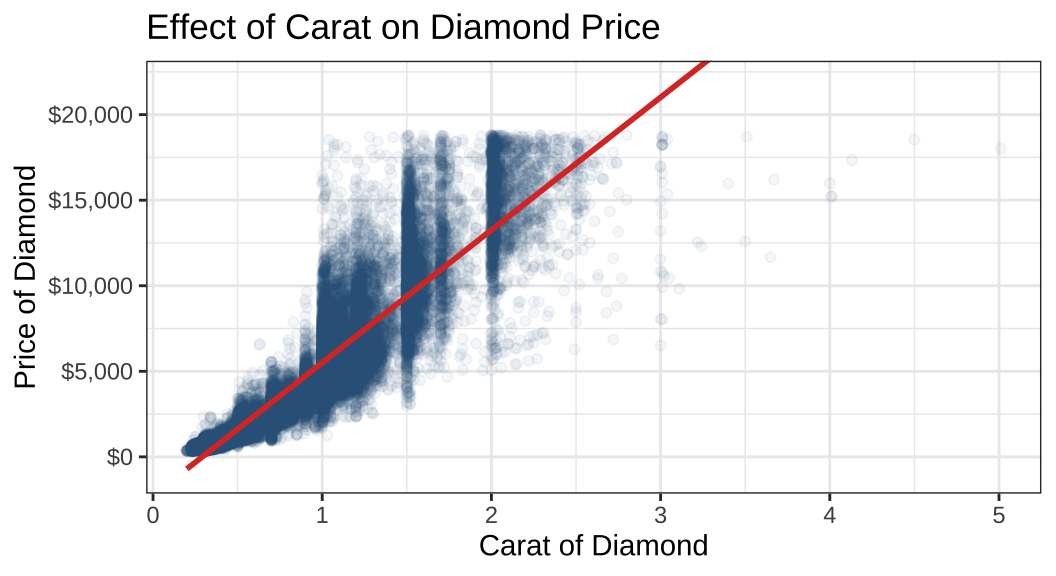
결과를 보면 선형이라기 보다는 지수함수와도 같은 형태로 우측으로 가파르게 상승하는 관계가 존재하는 것을 확인할 수 있습니다. alpha = .05로 관측치들의 집중도를 확인할 수 있는데, carat 값이 커질수록 관측치가 옅어지는 것을 확인할 수 있습니다. 아마도 이차항(quadratic term)을 포함하는 것이 더 관계를 잘 보여줄 수 있을 것으로 보입니다.
\(y = \alpha + \beta_1x_1 + \epsilon\)과 같은 선형 모델에서
\(y = \alpha + \beta_1{x_1}^2 + \epsilon\)과 같은 관계일 것이라고 상정해보는 것이죠.
df |>
ggplot(aes(x = carat, y = price)) +
geom_point(alpha = .05, color = futurevisions("mars")[3]) +
geom_smooth(method = 'lm', se = F, color = futurevisions("mars")[1]) +
geom_smooth(method = 'lm', formula = y ~ x + I(x^2),
se = F, color = futurevisions("mars")[4]) +
coord_cartesian(ylim = c(-1000, 22000)) +
theme_bw() +
labs(
x = 'Carat of Diamond', y = 'Price of Diamond',
title = "Effect of Carat on Diamond Price"
) +
scale_y_continuous(labels = scales::dollar_format())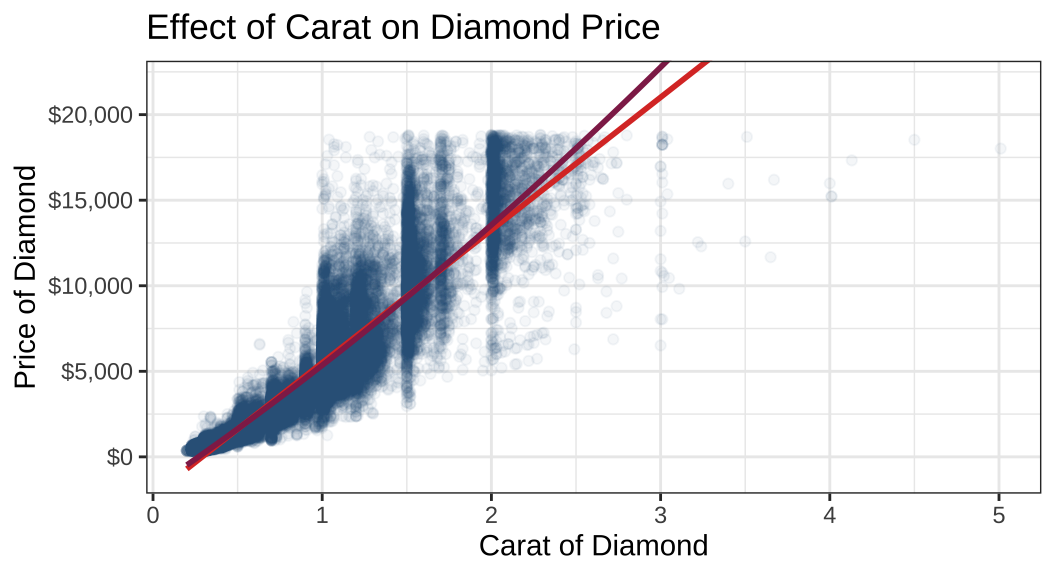
어떤 것이 데이터를 더 잘 보여주는 것 같나요? 보라색 회귀선, 이차항으로 그 관계를 표현해준 것이 좀 더 carat과 price의 관계를 잘 보여주는 것으로 보이네요. 그럼 이번에는 다이아몬드 데이터에 관측치가 너무 많기 때문에 딱 1,000의 배수가 되는 관측치들만 뽑아서 살펴보도록 하겠습니다.—천번째, 이천번째, 삼천번째…
temp_df <- df |>
dplyr::filter(rowid %% 1000 == 0)
glimpse(temp_df)Rows: 53
Columns: 13
$ rowid <int> 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000…
$ sold <int> 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1,…
$ carat <dbl> 1.12, 0.72, 0.90, 0.74, 1.05, 1.01, 1.00, 1.01, 0.91, 1.00,…
$ cut <ord> Premium, Ideal, Good, Ideal, Very Good, Premium, Premium, P…
$ color <ord> J, D, G, D, I, H, F, G, E, D, D, D, G, H, F, I, E, H, J, E,…
$ clarity <ord> SI2, VS2, SI2, SI1, SI2, SI2, SI2, SI2, SI1, SI1, VS2, SI1,…
$ depth <dbl> 60.6, 61.8, 63.8, 61.8, 62.3, 62.8, 62.6, 61.9, 63.5, 64.9,…
$ table <dbl> 59, 57, 56, 56, 59, 61, 58, 59, 57, 59, 59, 62, 60, 59, 61,…
$ price <int> 2898, 3099, 3303, 3517, 3742, 3959, 4155, 4327, 4512, 4704,…
$ price_bins <fct> medium, medium, medium, medium, medium, medium, medium, med…
$ x <dbl> 6.68, 5.76, 6.13, 5.84, 6.42, 6.33, 6.37, 6.46, 6.11, 6.20,…
$ y <dbl> 6.61, 5.73, 6.16, 5.88, 6.46, 6.25, 6.31, 6.39, 6.14, 6.13,…
$ z <dbl> 4.03, 3.55, 3.92, 3.62, 4.01, 3.95, 3.97, 3.98, 3.89, 4.00,…새로운 데이터셋, temp_df의 rowid를 보면 천의 자리의 배수로 관측치들이 추출되어 있다는 것을 확인할 수 있습니다. 이제, 이 데이터를 가지고 선형회귀모델을 다시 만들어보겠습니다.
model <- lm(price ~ carat, data = temp_df)
summary(model)
Call:
lm(formula = price ~ carat, data = temp_df)
Residuals:
Min 1Q Median 3Q Max
-6874.0 -727.7 -413.6 121.2 5785.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -836.3 471.6 -1.774 0.0821 .
carat 5719.0 440.7 12.977 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1983 on 51 degrees of freedom
Multiple R-squared: 0.7676, Adjusted R-squared: 0.763
F-statistic: 168.4 on 1 and 51 DF, p-value: < 2.2e-16broom 패키지를 이용하면 baseR의 summary 패키지보다 조금 더 세련된 방식으로 원하는 결과를 얻을 수 있습니다.
fitted_values <- broom::augment(model)
head(fitted_values)# A tibble: 6 × 8
price carat .fitted .resid .hat .sigma .cooksd .std.resid
<int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2898 1.12 5569. -2671. 0.0219 1966. 0.0207 -1.36
2 3099 0.72 3281. -182. 0.0200 2003. 0.0000882 -0.0929
3 3303 0.9 4311. -1008. 0.0189 1998. 0.00254 -0.513
4 3517 0.74 3396. 121. 0.0197 2003. 0.0000384 0.0617
5 3742 1.05 5169. -1427. 0.0204 1993. 0.00550 -0.727
6 3959 1.01 4940. -981. 0.0198 1998. 0.00252 -0.500 .fitted는 각 관측치에 따른 예측값으로 주어진 선형회귀모델에 개별 price와 carat, 즉 \(\text{price}_i\)와 \(\text{carat}_i\)를 대입하여 얻어낸 \(\hat{Y_i}\)입니다. 그리고 .resid는 실제 종속변수의 관측치, \(Y_i\)와 예측값의 차이인 잔차를 보여줍니다.
fitted_values |>
ggplot(aes(x = carat, y = price)) +
geom_point() +
geom_smooth(method = 'lm', se = F, color = futurevisions("mars")[3]) +
geom_segment(
aes(x = carat, y = price, xend = carat, yend = .fitted),
color = futurevisions("mars")[1], size = 0.3
) +
geom_curve(
aes(x = 2.75, y = 10000, xend = 2.55, yend = 15000),
color = futurevisions("mars")[1],
size = 1, arrow = arrow(length = unit(.1, "inches"))
) +
annotate(
"text", x = 2.75, y = 9500, label = "Residual / Error",
color = futurevisions("mars")[1]
) +
geom_curve(
aes(x = 1.5, y = 17500, xend = 2.0, yend = 11000),
color = futurevisions("mars")[3],
size = 1, arrow = arrow(length = unit(.1, "inches")),
curvature = -0.05
) +
annotate(
"text", x = 1.5, y = 18500,
label = "Regression line / Fitted Values",
color = futurevisions("mars")[3]
) +
labs(x = 'Carat', y = "Price") +
scale_y_continuous(labels = scales::dollar_format())
이 문서는 기본적으로 OLS 회귀분석—최소자승법을 이용한 선형회귀분석에 대한 개념을 이해하고 있다는 전제를 바탕으로 작성되었습니다. 이 그림은 carat과 price 간의 관계를 보여줄 때, 선형회귀선을 긋는다는 것이 어떠한 의미인지를 보여줍니다.
우리가 가진 관측치는 개별 검은 점들입니다.
우리는 각 점들로부터 얻은 정보를 바탕으로 그 추세를 파악하기 위해 선형인 관계로 예측하는 선을 그립니다.
이때 중요한 것이, 어떤 기준으로 선을 그어야 하냐는 것입니다.
OLS는 각 점들로부터 수직거리(즉, 실제 관측치와 예측값 간의 차이), 잔차(residuals)의 제곱 합이 가장 적은 선을 긋는 기법입니다.- 모집단에 대해서는 오차(errors)지만, 표본에 적용할 때에는 잔차(residuals)라고 표현합니다.
따라서 Ordinary least square란 결국 잔차의 제곱합이 최소가 되는 선을 긋는 방법을 말합니다.
제곱을 하는 이유는 가정 상 잔차의 총합은 0(\(\sum_{i=1}^n\epsilon_i = 0\))이기 때문에 잔차의 총합을 그냥 구하게 되면 서로 상쇄되어 0이 되므로 잔차의 총합이 가장 작아지는 선을 긋기 어렵습니다.
그렇다면 이번에는 다중선형회귀모델로 기존의 단순선형회귀모델을 확장해보도록 하겠습니다.
full_model <- lm(
price ~ carat + cut + color + clarity + depth + x + y + z,
data = temp_df
)
summary(full_model)
Call:
lm(formula = price ~ carat + cut + color + clarity + depth +
x + y + z, data = temp_df)
Residuals:
Min 1Q Median 3Q Max
-1668.2 -540.8 -132.6 330.2 2610.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39476.37 49735.10 0.794 0.43320
carat 12483.92 1742.57 7.164 3.92e-08 ***
cut.L 964.37 605.16 1.594 0.12086
cut.Q -922.27 527.28 -1.749 0.08986 .
cut.C 427.08 441.22 0.968 0.34033
cut^4 611.97 374.80 1.633 0.11232
color.L -2199.29 493.21 -4.459 9.49e-05 ***
color.Q -548.75 421.33 -1.302 0.20207
color.C 82.06 456.69 0.180 0.85853
color^4 -13.17 451.26 -0.029 0.97690
color^5 -317.53 434.29 -0.731 0.47001
color^6 -519.72 399.58 -1.301 0.20266
clarity.L 14308.21 1974.52 7.246 3.12e-08 ***
clarity.Q -10561.87 1712.62 -6.167 6.70e-07 ***
clarity.C 7119.07 1187.18 5.997 1.10e-06 ***
clarity^4 -3150.77 607.94 -5.183 1.17e-05 ***
clarity^5 1405.62 404.47 3.475 0.00149 **
depth -660.91 798.16 -0.828 0.41378
x 188.06 5272.89 0.036 0.97177
y -7612.02 5874.17 -1.296 0.20430
z 9615.52 13534.97 0.710 0.48259
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 971.5 on 32 degrees of freedom
Multiple R-squared: 0.965, Adjusted R-squared: 0.9431
F-statistic: 44.13 on 20 and 32 DF, p-value: < 2.2e-16tidy_model <- broom::tidy(full_model) |>
mutate_if(is.numeric, ~ round(., 2))
tidy_conf <- broom::confint_tidy(full_model)
tidy_conf <- tidy_conf |>
rename(ll = conf.low, ul = conf.high)
tidy_model <- bind_cols(tidy_model, tidy_conf) |>
mutate_if(is.numeric, ~ round(., 2)) 만들어진 티블은 선형회귀분석 결과를 잘 정리하여 보여줍니다. 먼저 상수항(절편)을 포함한 변수들의 계수값(estimate)이 나타나있고, 이어서 표준오차(std.error)를 보여주고 있습니다. t값(statistic)을 바탕으로 유의수준(p.value)도 보여주고 있고, 신뢰구간을 위해 최저값(ll)과 최고값(ul)도 나타납니다.
그렇다면 이제는 이 모델이 선형회귀모델의 기본적인 가정들, Gaus-Markov 가정을 위해하는지를 살펴보겠습니다. 먼저 선형회귀모델의 결과를 broom 패키지의 augment() 함수를 이용하여 별도의 객체인 fitted_model에 저장하였습니다.
fitted_model <- augment(full_model)
head(fitted_model)# A tibble: 6 × 15
price carat cut color clarity depth x y z .fitted .resid .hat
<int> <dbl> <ord> <ord> <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2898 1.12 Premium J SI2 60.6 6.68 6.61 4.03 3485. -587. 0.360
2 3099 0.72 Ideal D VS2 61.8 5.76 5.73 3.55 4367. -1268. 0.206
3 3303 0.9 Good G SI2 63.8 6.13 6.16 3.92 2961. 342. 0.424
4 3517 0.74 Ideal D SI1 61.8 5.84 5.88 3.62 3217. 300. 0.313
5 3742 1.05 Very G… I SI2 62.3 6.42 6.46 4.01 4283. -541. 0.300
6 3959 1.01 Premium H SI2 62.8 6.33 6.25 3.95 3430. 529. 0.338
# ℹ 3 more variables: .sigma <dbl>, .cooksd <dbl>, .std.resid <dbl>fitted_model을 보면 변수 중에 표준화된 잔차(.std.resid)가 있습니다. 이 변수를 히스토그램으로 나타내보겠습니다.
fitted_model |>
ggplot(aes(x = .std.resid)) + geom_histogram()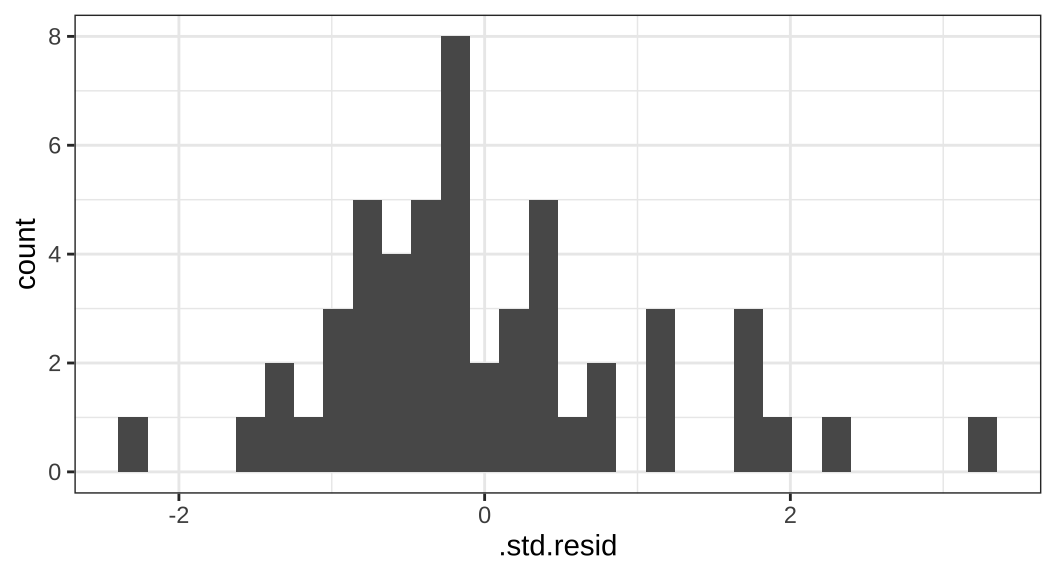
표준화된 잔차의 값이 넓게 분포하여 있다는 것은 우리의 예측값과 개별 관측치 간의 차이가 큰 경우가 존재한다는 것입니다. 회귀분석의 가정을 보다 자세히 살펴보기 위해서 다음과 같은 플롯을 그려보았습니다.
autoplot(full_model)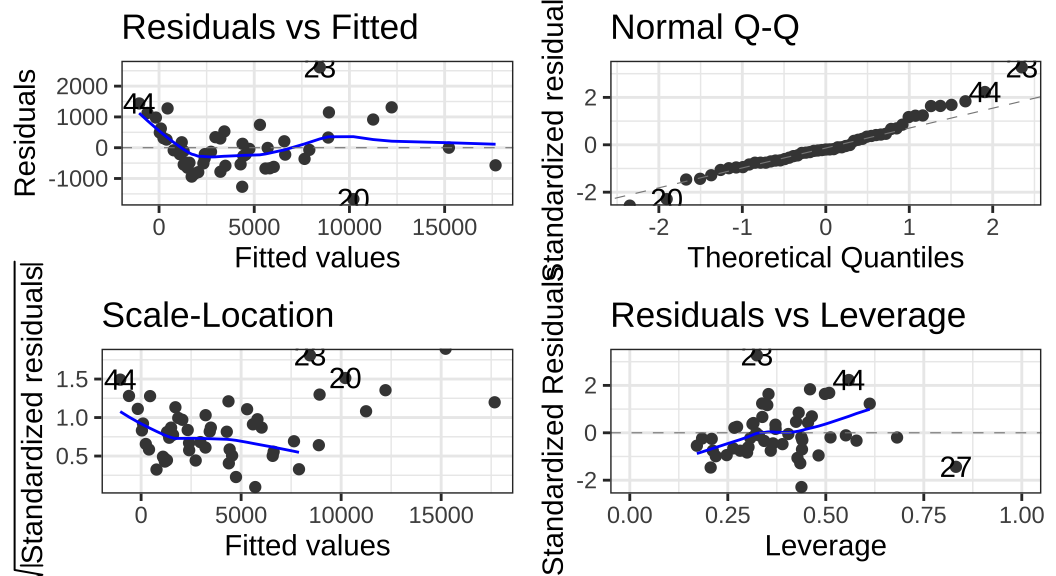
autoplot()은 ggplot2 패키지에서 주로 사용되는 함수들을 데이터에 맞게 적용시켜주는 ggfortify 패키지에 속한 함수입니다. 순서대로 보자면,
- 잔차와 예측값 간의 관계 (Residuals vs Fitted)
이 플롯은 잔차와 예측값의 관계가 선형인지 아닌지를 보여주는 플롯입니다.
선형회귀분석의 가정이 만족되기 위해서는 이 플롯은 0의 값을 갖는 수평선을 보여주어야 합니다.
여기서는 심하지는 않지만 약간의 선형성을 보여주고는 있습니다.
따라서 이 선형 모형에 제곱항(squared terms)을 포함해주는 등의 조치를 취해줄 필요가 있다는 것을 보여줍니다.
- QQ 플롯
QQ 플롯은 잔차가 정규분포를 따르고 있는지를 보여줍니다.
점선을 따라 분포되어 있어야 정규분포인데, 이 데이터의 결과는 역시 잔차의 정규성 또한 위반의 소지가 있음을 보여줍니다.
- 잔차의 동분산성 확인(Scale-Location or Spread-Location)
잔차의 분산의 동질성을 확인하기 위해 그리는 플롯입니다(등분산성).
선들이 평평하게 확산되는 수평선이 등분산성을 보여주는 좋은 지표입니다.
이 예제 데이터는 일정한 경향성을 보여주기 때문에 이분산성의 문제(heteroscedasticity)가 존재할 수 있음을 보여줍니다.
이분산성은 로버스트 표준오차(robust standard errors)를 통해서 쉽게 해결할 수 있습니다.
로버스트 표준오차란 표준오차를 계산할 때, 단위(units) 간 차이를 고려해 보정해준 표준오차를 의미합니다.
- 잔차 대 레버리지(Residuals vs Leverage)
극단적인 값들이 분석에 포함/배제될 경우에는 회귀분석 결과에 영향을 미칠 수 있습니다.
따라서 이 플롯은 그러한 극단적인 이상치들이 있는지를 확인하는 데 사용됩니다.
우측 극단에 값들이 나타나는 것을 확인할 수 있습니다.
확실히 몇몇 극단적인 이탈치들이 제거될 필요가 있음을 보여줍니다.2
연속형이 아닐 경우에 선형회귀분석을 쓰면 어떻게 될까?
그렇다면 종속변수가 이항변수(binary)일때는 선형회귀모형(OLS)을 사용할 수 없을까요? 그건 아닙니다. 사용할 ‘수는’ 있습니다. 종속변수가 이항변수일 때, 선형회귀보델을 사용할 경우, 우리는 그것을 선형확률모형(linear probability model, LPM)이라고 부릅니다. 그러나 LPM을 사용하는 데 있어서는 여러 가지 제약들이 존재합니다.
LPM은 이분산성이 거의 확정적입니다.
왜냐하면 종속변수는 0에서 1 중 하나의 값만 가지는 데 비해 설명변수는 연속형일 경우 큰 변량(variations)을 가지므로 당연히 오차항의 이분산성이 존재할 가능성이 커집니다.
이 문제는 표본의 크기가 크면 로버스트 표준오차를 취함으로써 쉽게 해결해줄 수 있습니다.
LPM을 통해 우리는 0…1의 확률을 넘어서는 예측을 할 수 있습니다.
만약 단위 구간(0…1)을 넘어서는 예측확률이 없거나, 거의 없다면
LPM은 대개 불편(unbiased)하고 일관될 것으로 기대됩니다.하지만 선형회귀모델은 기본적으로 종속변수가 0과 1 사이에 ’갇혀있다’고 가정하지는 않습니다. 즉, 경우에 따라 예측값이 0과 1을 넘는, 실존할 수 없는 값을 가지게 될 수 있습니다. 이를 외삽의 문제(extrapolation)라고 합니다.
그렇다면 LPM을 사용하는 이유는 무엇일까요?
- 빅데이터 분석을 할 때, 더 빠르게 계산이 가능합니다.
물론 속도 문제는 이제 컴퓨터 기술이 발전해서 큰 문제는 아닐 수 있습니다.
그러나 아무리 컴퓨터가 좋아도 확률론이 아니라 최대가능도를 반복계산하게 되면 시간이 더 걸리는 것은 사실이기 때문에, 실무에서는
LPM이 종종 사용됩니다.
- 해석하기가 정말 쉽습니다.
계수 값은 결국
x의 한 단위 증가와 관련된y의 증가분을 보여주는 “한계효과”입니다.LPM역시y를 일종의 확률로 이해한다는 것에 차이가 있을 뿐, 기본적인OLS해석의 결을 같이하기 때문에 직관적입니다.
그럼 한 번 LPM 모형을 만들어보겠습니다. 종속변수를 다이아몬드의 판매 여부(sold)로 설정하겠습니다. 이분산성은 거의 확실하기 때문에 표준오차를 로버스트 표준오차로 설정해주도록 하겠습니다(se_type = "HC1).
lmp <- lm_robust(
sold ~ price + carat + cut + color + clarity + depth + x + y + z,
data = df, se_type = "HC1"
)
non_lmp <- lm(
sold ~ price + carat + cut + color + clarity + depth + x + y + z,
data = df
)
lmp_tidy <- tidy(lmp) |>
dplyr::select(1:5)
nonlmp_tidy <- tidy(non_lmp) |>
dplyr::select(1:5)lmp.table <- lmp_tidy |>
mutate_if(is.numeric, ~ round(., 3))knitr::kable(lmp.table, digits = 3)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.482 | 0.111 | 4.358 | 0.000 |
| price | 0.000 | 0.000 | -1.207 | 0.227 |
| carat | 0.041 | 0.027 | 1.491 | 0.136 |
| cut.L | 0.014 | 0.008 | 1.634 | 0.102 |
| cut.Q | -0.012 | 0.007 | -1.631 | 0.103 |
| cut.C | 0.006 | 0.006 | 0.911 | 0.362 |
| cut^4 | -0.004 | 0.005 | -0.873 | 0.383 |
| color.L | -0.019 | 0.008 | -2.384 | 0.017 |
| color.Q | 0.003 | 0.006 | 0.522 | 0.601 |
| color.C | -0.004 | 0.006 | -0.741 | 0.459 |
| color^4 | 0.005 | 0.005 | 0.879 | 0.379 |
| color^5 | 0.006 | 0.005 | 1.120 | 0.263 |
| color^6 | 0.009 | 0.005 | 1.902 | 0.057 |
| clarity.L | 0.021 | 0.014 | 1.474 | 0.140 |
| clarity.Q | -0.009 | 0.012 | -0.784 | 0.433 |
| clarity.C | 0.015 | 0.010 | 1.581 | 0.114 |
| clarity^4 | -0.004 | 0.008 | -0.545 | 0.586 |
| clarity^5 | 0.002 | 0.006 | 0.278 | 0.781 |
| clarity^6 | -0.004 | 0.006 | -0.766 | 0.444 |
| clarity^7 | 0.006 | 0.005 | 1.291 | 0.197 |
| depth | -0.003 | 0.002 | -1.644 | 0.100 |
| x | -0.013 | 0.010 | -1.370 | 0.171 |
| y | -0.009 | 0.002 | -4.304 | 0.000 |
| z | 0.020 | 0.008 | 2.476 | 0.013 |
non_lmp.table <- nonlmp_tidy |>
mutate_if(is.numeric, ~ round(., 3))knitr::kable(non_lmp.table, digits = 3)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.482 | 0.118 | 4.097 | 0.000 |
| price | 0.000 | 0.000 | -1.196 | 0.232 |
| carat | 0.041 | 0.028 | 1.477 | 0.140 |
| cut.L | 0.014 | 0.009 | 1.608 | 0.108 |
| cut.Q | -0.012 | 0.007 | -1.606 | 0.108 |
| cut.C | 0.006 | 0.006 | 0.903 | 0.367 |
| cut^4 | -0.004 | 0.005 | -0.871 | 0.384 |
| color.L | -0.019 | 0.008 | -2.379 | 0.017 |
| color.Q | 0.003 | 0.006 | 0.522 | 0.602 |
| color.C | -0.004 | 0.006 | -0.740 | 0.459 |
| color^4 | 0.005 | 0.005 | 0.875 | 0.382 |
| color^5 | 0.006 | 0.005 | 1.119 | 0.263 |
| color^6 | 0.009 | 0.005 | 1.900 | 0.057 |
| clarity.L | 0.021 | 0.014 | 1.451 | 0.147 |
| clarity.Q | -0.009 | 0.012 | -0.768 | 0.443 |
| clarity.C | 0.015 | 0.010 | 1.557 | 0.119 |
| clarity^4 | -0.004 | 0.008 | -0.539 | 0.590 |
| clarity^5 | 0.002 | 0.006 | 0.276 | 0.782 |
| clarity^6 | -0.004 | 0.006 | -0.764 | 0.445 |
| clarity^7 | 0.006 | 0.005 | 1.290 | 0.197 |
| depth | -0.003 | 0.002 | -1.522 | 0.128 |
| x | -0.013 | 0.013 | -0.985 | 0.324 |
| y | -0.009 | 0.008 | -1.087 | 0.277 |
| z | 0.020 | 0.014 | 1.473 | 0.141 |
표준오차가 미묘하게 다른 것을 확인할 수 있습니다. 좀 더 가시적으로 보기 위해서는 이 결과를 autoplot()으로 살펴보도록 하겠습니다. 먼저 로버스트 표준오차를 취하지 않은 경우입니다.
lm(
sold ~ price + carat + cut + color + clarity + depth + x + y + z, data = df
) |> autoplot()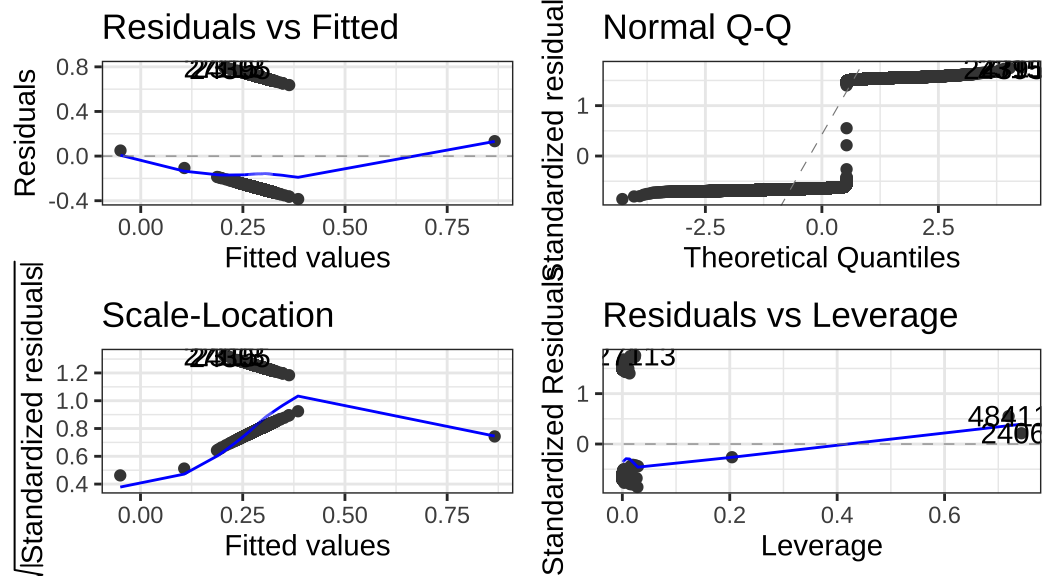
## Comparison of coefficients
round(lmp_tidy$estimate, 4) |> unname() [1] 0.4821 0.0000 0.0410 0.0137 -0.0117 0.0056 -0.0043 -0.0186 0.0034
[10] -0.0044 0.0048 0.0058 0.0089 0.0206 -0.0091 0.0155 -0.0042 0.0018
[19] -0.0042 0.0063 -0.0026 -0.0132 -0.0085 0.0200round(nonlmp_tidy$estimate, 4) [1] 0.4821 0.0000 0.0410 0.0137 -0.0117 0.0056 -0.0043 -0.0186 0.0034
[10] -0.0044 0.0048 0.0058 0.0089 0.0206 -0.0091 0.0155 -0.0042 0.0018
[19] -0.0042 0.0063 -0.0026 -0.0132 -0.0085 0.0200## Comparison of standard errors
round(lmp_tidy$std.error, 7) |> unname() [1] 0.1106419 0.0000017 0.0274991 0.0083997 0.0071796 0.0061152 0.0049379
[8] 0.0077837 0.0064853 0.0059586 0.0054492 0.0051671 0.0046965 0.0139508
[15] 0.0116596 0.0097786 0.0077573 0.0063610 0.0055404 0.0048956 0.0015881
[22] 0.0096612 0.0019752 0.0080639round(nonlmp_tidy$std.error, 7) [1] 0.1176719 0.0000017 0.0277558 0.0085350 0.0072938 0.0061702 0.0049474
[8] 0.0078001 0.0064924 0.0059671 0.0054750 0.0051740 0.0047016 0.0141779
[15] 0.0119070 0.0099244 0.0078317 0.0063884 0.0055514 0.0049016 0.0017158
[22] 0.0134312 0.0078239 0.0135539계수는 한계효과를 보여주기 때문에 이 경우에는 해석이 꽤 쉬운 편입니다. 이번에는 가격에 대한 선형회귀모형을 분석하고 그 결과를 좀 더 보기 좋은 플롯으로 바꾸어 보겠습니다. 가격을 종속변수로 쓰는 이유는 다이아몬드 데이터는 실제 데이터기 때문에 무작위 값을 가지지 않기 때문입니다 (관계가 나타나면 잘 보일 것).
new_df <- df |> sample_n(1000)
full_model <- lm(
price ~ carat + cut + color + clarity + depth + x + y + z, data = new_df
)
summary(full_model)
Call:
lm(formula = price ~ carat + cut + color + clarity + depth +
x + y + z, data = new_df)
Residuals:
Min 1Q Median 3Q Max
-5353.3 -579.2 -129.3 412.1 6676.8
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7137.56 3512.12 -2.032 0.042397 *
carat 10981.80 369.96 29.684 < 2e-16 ***
cut.L 706.77 150.08 4.709 2.84e-06 ***
cut.Q -280.83 133.02 -2.111 0.035003 *
cut.C 156.43 116.94 1.338 0.181297
cut^4 -56.43 89.27 -0.632 0.527435
color.L -2136.85 129.85 -16.456 < 2e-16 ***
color.Q -627.25 116.40 -5.389 8.89e-08 ***
color.C -149.21 108.34 -1.377 0.168753
color^4 -36.90 98.26 -0.375 0.707387
color^5 -89.66 91.57 -0.979 0.327733
color^6 29.44 83.12 0.354 0.723259
clarity.L 4044.26 209.23 19.330 < 2e-16 ***
clarity.Q -2031.17 191.46 -10.609 < 2e-16 ***
clarity.C 815.57 165.67 4.923 1.00e-06 ***
clarity^4 -141.57 132.47 -1.069 0.285469
clarity^5 149.48 110.54 1.352 0.176602
clarity^6 72.15 101.02 0.714 0.475268
clarity^7 103.18 90.11 1.145 0.252447
depth 114.61 58.07 1.974 0.048701 *
x 244.13 801.63 0.305 0.760784
y 808.75 829.49 0.975 0.329804
z -3236.79 922.82 -3.507 0.000473 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1110 on 977 degrees of freedom
Multiple R-squared: 0.9242, Adjusted R-squared: 0.9225
F-statistic: 541.2 on 22 and 977 DF, p-value: < 2.2e-16full_model은 가격을 종속변수로 하고, carat, cut, color, clarity, depth, x, y, z를 설명변수로 하는 다중선형회귀모델입니다. 이제 full_model의 결과를 broom 패키지의 함수들을 이용해 깔끔하게 정리해보겠습니다.
new_tidy_model <- broom::tidy(full_model) |>
print(n = Inf) # A tibble: 23 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -7138. 3512. -2.03 4.24e- 2
2 carat 10982. 370. 29.7 1.55e-138
3 cut.L 707. 150. 4.71 2.84e- 6
4 cut.Q -281. 133. -2.11 3.50e- 2
5 cut.C 156. 117. 1.34 1.81e- 1
6 cut^4 -56.4 89.3 -0.632 5.27e- 1
7 color.L -2137. 130. -16.5 6.84e- 54
8 color.Q -627. 116. -5.39 8.89e- 8
9 color.C -149. 108. -1.38 1.69e- 1
10 color^4 -36.9 98.3 -0.375 7.07e- 1
11 color^5 -89.7 91.6 -0.979 3.28e- 1
12 color^6 29.4 83.1 0.354 7.23e- 1
13 clarity.L 4044. 209. 19.3 9.57e- 71
14 clarity.Q -2031. 191. -10.6 5.81e- 25
15 clarity.C 816. 166. 4.92 1.00e- 6
16 clarity^4 -142. 132. -1.07 2.85e- 1
17 clarity^5 149. 111. 1.35 1.77e- 1
18 clarity^6 72.2 101. 0.714 4.75e- 1
19 clarity^7 103. 90.1 1.15 2.52e- 1
20 depth 115. 58.1 1.97 4.87e- 2
21 x 244. 802. 0.305 7.61e- 1
22 y 809. 829. 0.975 3.30e- 1
23 z -3237. 923. -3.51 4.73e- 4new_tidy_conf <- broom::confint_tidy(full_model)
new_tidy_conf <- new_tidy_conf |>
rename(ll = conf.low, ul = conf.high)
new_tidy_model <- bind_cols(new_tidy_model, new_tidy_conf)
print(new_tidy_model, n = Inf)# A tibble: 23 × 7
term estimate std.error statistic p.value ll ul
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -7138. 3512. -2.03 4.24e- 2 -14030. -245.
2 carat 10982. 370. 29.7 1.55e-138 10256. 11708.
3 cut.L 707. 150. 4.71 2.84e- 6 412. 1001.
4 cut.Q -281. 133. -2.11 3.50e- 2 -542. -19.8
5 cut.C 156. 117. 1.34 1.81e- 1 -73.0 386.
6 cut^4 -56.4 89.3 -0.632 5.27e- 1 -232. 119.
7 color.L -2137. 130. -16.5 6.84e- 54 -2392. -1882.
8 color.Q -627. 116. -5.39 8.89e- 8 -856. -399.
9 color.C -149. 108. -1.38 1.69e- 1 -362. 63.4
10 color^4 -36.9 98.3 -0.375 7.07e- 1 -230. 156.
11 color^5 -89.7 91.6 -0.979 3.28e- 1 -269. 90.0
12 color^6 29.4 83.1 0.354 7.23e- 1 -134. 193.
13 clarity.L 4044. 209. 19.3 9.57e- 71 3634. 4455.
14 clarity.Q -2031. 191. -10.6 5.81e- 25 -2407. -1655.
15 clarity.C 816. 166. 4.92 1.00e- 6 490. 1141.
16 clarity^4 -142. 132. -1.07 2.85e- 1 -402. 118.
17 clarity^5 149. 111. 1.35 1.77e- 1 -67.4 366.
18 clarity^6 72.2 101. 0.714 4.75e- 1 -126. 270.
19 clarity^7 103. 90.1 1.15 2.52e- 1 -73.6 280.
20 depth 115. 58.1 1.97 4.87e- 2 0.655 229.
21 x 244. 802. 0.305 7.61e- 1 -1329. 1817.
22 y 809. 829. 0.975 3.30e- 1 -819. 2437.
23 z -3237. 923. -3.51 4.73e- 4 -5048. -1426. 마지막으로 이렇게 ’표’로 보여주는 것이 아니라 가독성이 좋게 계수플롯(coef.plot)의 형태로 나타내 보겠습니다.
library(wesanderson)
new_tidy_model |>
dplyr::filter(term != "(Intercept)") |>
mutate(
term = str_replace(term, 'cut', 'cut -- '),
term = str_replace(term, 'color', 'color -- '),
term = str_replace(term, 'clarity', 'clarity -- ')
) |>
rename(variable = term) |>
ggplot(aes(x = reorder(variable, estimate), y = estimate,
color = p.value <= 0.05)
) +
geom_point(show.legend = F) +
geom_linerange(aes(ymin = ll, ymax = ul), show.legend = F) +
geom_hline(yintercept = 0, color = 'purple', linetype = 'dashed') +
coord_flip() +
labs(x = 'Independent Variables', y = 'Estimate with Confidence Intervals') +
scale_color_manual(values = wes_palette("Royal1"))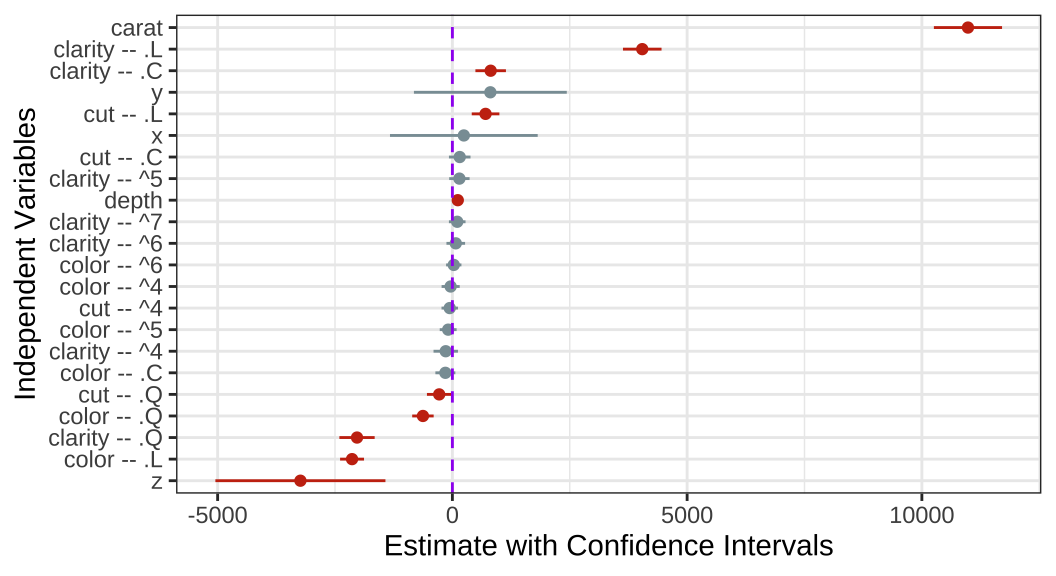
이 결과는 예측변수들이 가격과 어떠한 관계를 가지는지 다변량(multivariate) 관계를 바탕으로 보여주고 있습니다.
문제의 진단과 해결?
일반적으로 이탈치와 오차의 비정규적 분포의 문제는 변수를 제곱 또는 제곱근을 취하는 등의 변환(transform)을 통해 통계적으로 해결하는 방법이 있습니다. 이러한 방법들의 기본 논리는 비선형적 관계를 수리적 조치를 이용해 일견 선형성의 틀에 가두는 것과 같습니다. 예를 들어 \(\frac{1}{2}, 1, 2\)의 관계는 비선형적입니다. 하지만 로그화할 경우, \(\text{log}_2(\frac{1}{2}), \text{log}_2(1), \text{log}_2(2)\)는 \(-1, 0, 1\)로 선형적 틀에 가두어 보여줄 수 있습니다.
일정하지 않은 분산의 경우 일종의 가중치를 가중최소제곱 기법(weighted-least-squares)을 사용해볼 수 있습니다. 가중치를 부여한 제곱합을 최소화하는 방법으로 더 작은 분산을 가진 관측치에 가중치를 주어 일정하지 않은 분산에 대한 표준오차를 보정(correct)하는 것입니다. 또는, Huber-White 로버스트 표준오차라는 방법으로 공분산행렬의 대각행렬에 제곱근을 취하는 방밥이 있습니다. 자세한 내용은 King and Roberts (2015)를 참고하시기 바랍니다.
마지막으로 공선성의 문제를 해결하는 방법으로는 변수에 새로운 정보를 더하여 새로운 측정지표를 만들어내는 것이 있습니다. 그리고 새로운 정보를 포함한 지표와 기존 변수들 간에 어떤 것이 더 \(Y\)를 잘 설명하는지 순위를 매겨보는 것이죠. 공선성의 문제는
변수의 수를 줄이고
\(X\)들 간의 독립성을 확보하고
변수 간 상호이동성(interpretability, 서로 거의 비슷하면 사실 이동성이 매우 높은 것이라고 할 수 있습니다)을 줄이는
것을 통해 해결할 수 있습니다. 따라서 구성개념의 다른 측면을 보여줄 수 있는 경험지표를 설계하는 모델의 재구성(model respecification)과 변수 선택, 그리고 일종의 편향된 추정방법(e.g., ridge regression) 등을 사용하여 해결하고는 합니다.
Statistical Significance
기초통계 파트와 현재 이 챕터까지 따라오셨다면, 회귀분석에 있어서 BLUE라는 것이 무엇을 의미하는지, 그리고 표집분포(sampling distribution)이 무엇인지, 적절하지 않은 변수들을 모델에 포함하였을 때 어떤 결과를 얻게 되는지와 적절한 변수를 모델에 포함시키지 않았을 때 생기는 문제 등에 대해서는 익숙하시리라 생각합니다.
바로 이전 챕터를 통해 이제는 \(y = \alpha + \beta_1x + \beta_2z + \beta_3xz + \epsilon\)이라는 상호작용이 포함된 모델을 해석하실 수 있을 것이며, 나아가 \(y = \alpha + \beta_1I(x = 1) + \beta_2I(x = 2) + \epsilon, \text{with }x \in \{0, 1,2\}\)와 같이 \(x\)가 이산형 변수(discrete)일 때 모델에 어떻게 투입하고 그 결과를 해석하실 수 있을 것이라 생각합니다.
이 챕터에서는 통계적으로 유의미하다는 것의 의미와 그 기준, 그리고 모집단을 알 수 없기 때문에 표본을 통해 통계적 추론을 한다는 것이 실제로 어떠한 분석을 수반하는지 등을 중점적으로 살펴보고자 합니다.
영가설 유의성 검정 (Null Hypothesis Significance Testing; NHST)
우리가 생각하는 모집단에 대한 \(\beta_k\)가 사실(true)라고 가정해보겠습니다. \(\beta_k\)가 보여주고자 하는 모수를 \(w\)라고 하겠습니다.
\(\beta_k = w\)라는 가정 하에서, 우리는 관측가능한 표본들로부터 추출한 \(\hat{\beta}_k\)들로부터 나타나는 분포가 얼마나 그 \(w\)를 보여주는 \(\beta_k\)를 포함할 가능성을 가지는지를 생각해볼 수 있습니다. 나아가 \(\beta_k = w\)라고 가정한다면 우리는 사실상 알 수 없는 모수를 아는 것과 다름없게 됩니다. 왜냐하면 \(\beta_k\)의 표집분포의 기대값이 \(w\)를 제대로 보여준다면, 이후에는 충분한 수의 표집과정을 통해 \(\beta_k\)를 충분히 확보만 하면 되는 것이니까요.
기술적으로 우리는 이것을 \((n-k-1)\)의 자유도를 가진 Student t 분포라고 합니다. 그리고 상당한 수의 관측치를 확보하게 된다면, 이 분포는 가우시안(Gaussian) 분포라고 할 수 있습니다. 아래와 같은 공식으로 나타낼 수 있겠네요.
\[
\frac{\hat{\beta_k} - \beta_k}{se(\hat{\beta})} \sim t_{n-k-1}
\] 그렇다면 이제 영가설 유의성검정의 절차를 한 번 살펴보도록 하겠습니다. 영가설을 \(H_0: \beta_k = w\)이라고 설정해보도록 하겠습니다. 그리고 이때 t 통계치는 \(\frac{\hat{\beta_k} - w}{se(\hat{\beta_k}-w)} \sim t_{n-k-1}\)로 나타낼 수 있겠네요. 그렇다면 여기서 문제입니다. \(\beta_k\)에 대한 영가설 혹은 연구가설을 기각하기 위해서 우리에게 필요한 t 통계치는 얼마일까요? 즉 \(\hat{\beta_k}\)은 얼마나 \(\beta_k\)로부터 떨어져 있어야할까요?
먼저 영가설 \(H_0: \beta_k = w\)에 대해 그것과 비교하기 위한 대안가설(연구가설)을 \(H_1: \beta_k > w\)이라고 해보겠습니다. 즉, 우리가 관심있는 것은 \(\beta_k > w\)이지만 이것을 직접적으로 검증하거나 혹은 확증할 수는 없기 때문에 \(\beta_k \neq w\)라는 것을 통해 영가설을 기각함으로써 영가설이 기각될 확률, 연구가설이 유의미할 ’확률’을 구하게 되는 것입니다.
이것이 우리가 흔히 말하는 유의수준(significance level)입니다. 기술적으로 서술하자면 “모집단에서 추출한 100개의 표본 중에서 영가설이 사실일 경우를 기각하는 것을 몇 번 관측할 수 있느냐”라고 하는 것입니다. 만약 100개의 표본 중에서 12개의 표본이 영가설의 기대대로 \(\beta_k = w\)라는 것을 보여줬다면, 영가설이 사실일 확률은 0.12 이 될 것입니다. 이때 우리는 이 영가설이 사실일 확률 0.12를 \(\alpha\)라고 표현합니다. \(\alpha\)의 값이 더 작을 수록 영가설을 기각하는 \(\hat{\beta_k}\)가 더 많다는 것을 의미합니다.
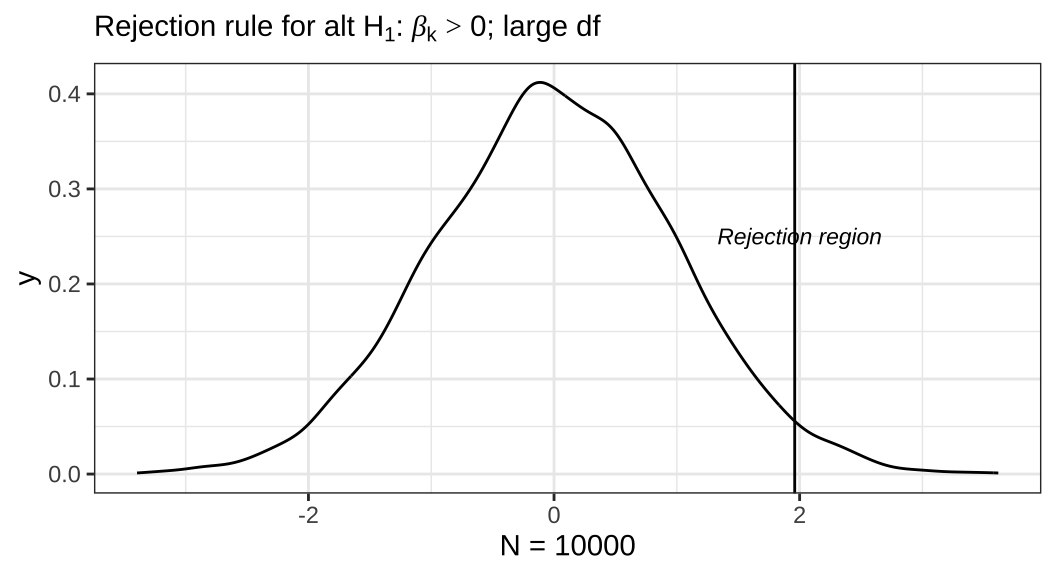
위의 플롯은 영가설(\(H_0\))이 \(\beta_k = 0\)이라고 했을 때, 연구가설(\(H_1\))이 \(\beta_k > 0\)인 경우, 관측치가 10,000개인 표본에서의 기각역(rejection region)을 보여주고 있습니다. 일단 전체 곡선 면적의 합은 1입니다. 당연하겠죠? 밀도함수로 나타낸 분포이니까 전체의 총합은 1입니다. 그리고 플롯에서 기각역이라고 나타난 선 우측의 면적의 총합은 0.05가 됩니다. 통상적으로 그것은 우리가 상정한 영가설대로 \(\beta_k = 0\)일 확률을 의미합니다.
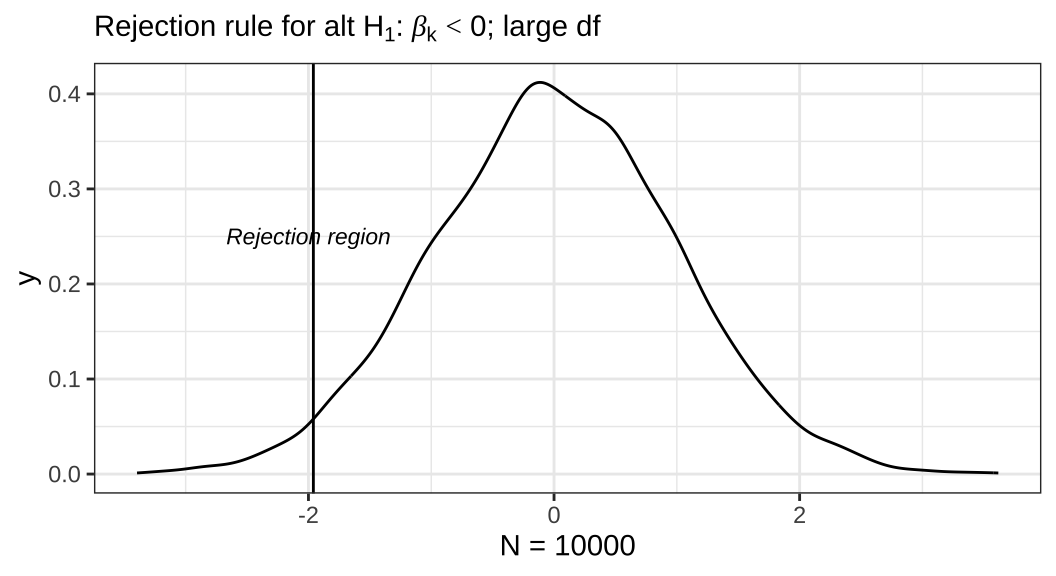
이번에는 영가설(\(H_0\))이 \(\beta_k = 0\)이라고 했을 때, 연구가설(\(H_1\))이 \(\beta_k < 0\)인 경우, 관측치가 10,000개인 표본에서의 기각역(rejection region)을 살펴보겠습니다. 마찬가지로 전체 곡선 면적의 합은 1입니다. 앞서의 플롯과 다른 점은 기각역의 위치입니다. 연구가설이 상정한 계수의 부호가 달라졌기 때문에 기각역의 위치도 달라진 것이죠. 따라서 이때는 선 좌측의 면적의 총합이 0.05가 되고, 영가설대로 \(\beta_k = 0\)일 확률을 의미합니다.
우리는 t 통계치가 우리가 상정한 100개의 표본 중에서 n개의 표본만이 영가설에 부합할 것이다라고 할 수 있는 일종의 결정적 기준값(critical value)보다 클 경우에 영가설을 기각할 수 있습니다. 이 결정적 기준값은 유의수준(\(\alpha\)) 혹은 전체 확률에서 유의수준을 제한 값(\(1-\alpha\))을 Student t 혹은 정규누적밀도함수에 대입하면 구할 수 있습니다.
영가설의 기각 이후
영가설을 기각했다고 해보겠습니다. 그렇다면 우리는 그 기각 결과를 가지고 어떻게 연구가설에 대해 설명할 수 있을까요?
사실 \(\alpha\)라고 하는 특정한 값을 사전에 미리 설정하고 그것을 선긋듯이 어떠한 결과를 결정하는 도구로 사용한다는 것은 문제의 소지가 있어 보입니다. 예를 들어 \(p\) 값이 0.051인 경우와 0,049일 때, 우리는 이들의 통계적 의미를 어떻게 이해해야할까요?
\(p\) 값은 주어진 t 통계치 하에서 영가설을 기각할 수 있는 가장 작은 \(\alpha\)를 의미합니다. 공식을 통해서 살펴보자면, \(T\)가 우리가 얻을 수 있는 모든 가능한 검정 통계량(test statistics)라고 해보겠습니다. 예를 들어 Student t나 Gaussian이 있겠네요. 이때 만약 가설이 특정한 관계의 방향을 설정하지 않고 있다면, 단지 영가설 \(\beta_k = 0\)만을 기각하면 되기 때문에 이른바 양측검정을 상정한 연구가설을 설정하게 될 것입니다. 따라서 이때는 관계의 방향을 상정하지 않는 \(Pr(|T|>|t|) = 2Pr(T>|t|)\)가 성립하게 됩니다.
이제까지는 \(\beta_k = 0\)인 경우를 중심으로 살펴보았습니다. 왜냐하면 사실 회귀분석 같은 경우 영가설은 우리가 기대한 변수가 종속변수에 대해 ’효과가 없을 것’을 주로 기대하기 때문입니다. 따라서 \(\beta_k = 0\)이 기각되었다는 것은 우리가 관심을 가지고 있는 변수가 종속변수에 대해 유의미한 영향이 있을 수 있다는 것을 시사합니다.
하지만 사실 영가설은 반드시 0, 효과가 없다는 것만을 기대할 필요는 없습니다. 예를 들어서 \(H_0: \beta_k = g\)라는 특정한 값을 가지는 영가설에 대해서 \(H_1: \beta_k > g\)와 같이 계수값이 그 특정한 값보다 클 경우를 상정할 수 있습니다. 이때 유의수준 \(\alpha\)를 설정한다면, \(t = \frac{\hat{\beta_k} - g}{se(\hat{\beta_k})}\)가 되므로, 우리는 \(t > c\)이기만 하면 영가설을 기각할 수 있습니다.3 조금 더 풀어서 말하자면 일반적인 t 통계량은 다음과 같이 쓸 수 있습니다.
\[ t = \frac{\text{추정치 - 가설로 기대하는 값}}{\text{추정치의 표준오차}} \]
이제 정치학 분야에서 실제로 사용할법한 데이터를 이용해서 위의 내용을 한 번 더 살펴보도록 하겠습니다. Quality of Government 데이터셋을 이용해서 \(y = a_0 + \sum_k \beta_k x_k + e\)의 형태를 갖는 선형회귀모델을 한 번 만들어 보겠습니다.
QOG <- ezpickr::pick(file = "http://www.qogdata.pol.gu.se/data/qog_std_ts_jan20.dta")
QOG.sub <- QOG |> dplyr::filter(year == 2015) |>
dplyr::select(ccode, cname, year,
p_polity2, wdi_trade, wdi_pop1564, wdi_gdpcapcon2010) |>
drop_na()위의 데이터를 바탕으로 단순선형회귀모델과 다중선형회귀모델을 각각 만들어보도록 하겠습니다.
model.simple <-
lm(wdi_gdpcapcon2010 ~ wdi_trade, data=QOG.sub)
result1 <- summary(model.simple) |> broom::tidy() |>
mutate(model = "SLR")
model.multiple <-
lm(wdi_gdpcapcon2010 ~ wdi_trade + p_polity2 +
wdi_pop1564, data=QOG.sub)
result2 <- summary(model.multiple) |> broom::tidy() |>
mutate(model = "MLR")
results <- bind_rows(result1, result2) |>
mutate_if(is.numeric, round, 3)이렇게 만들어진 두 선형회귀모델을 가지고 영가설이 \(\beta_k = 0\)인 경우와 \(\beta_k = c\)인 경우를 한 번 살펴보도록 하겠습니다. 물론 이 경우에는 \(c\)가 합당한 비교 기준이라고 정당화할 수 있어야할 것입니다. 다중선형회귀모델을 기준으로 모델을 수식으로 표현한다면 아래와 같습니다.
\[ \text{Economy} = \beta_1\text{Trade} + \beta_2\text{Level of Democracy} + \beta_3\text{Working Population} + e. \]
results |> knitr::kable()| term | estimate | std.error | statistic | p.value | model |
|---|---|---|---|---|---|
| (Intercept) | -390.277 | 2798.098 | -0.139 | 0.889 | SLR |
| wdi_trade | 164.335 | 28.365 | 5.794 | 0.000 | SLR |
| (Intercept) | -56094.546 | 12291.936 | -4.564 | 0.000 | MLR |
| wdi_trade | 118.001 | 27.842 | 4.238 | 0.000 | MLR |
| p_polity2 | 754.766 | 218.613 | 3.453 | 0.001 | MLR |
| wdi_pop1564 | 889.742 | 201.305 | 4.420 | 0.000 | MLR |
여기서 \(x_1\)에 대한 계수, \(\beta_1\)을 중심으로 일단 영가설을 특정해보도록 하겠습니다.
먼저 \(H_0: \beta_1 = 0\)이라고 할때, 민주주의 변수, 노동가능 인구비율이 통제되었을 때, GDP 대비 재화와 서비스의 수출 및 수입의 총합으로 측정된 무역개방성의 한 단위 증가는 2010년 고정 달러로 측정된 1인당 GDP, 즉 그 국가의 경제규모에 미치는 효과가 없다라는 것이 영가설임을 이해할 수 있습니다.
그 다음으로는 결정적 기준값으로 영가설을 수립해보도록 하겠습니다. 이번의 영가설은 \(\beta_1 = 164.355\)라고 하겠습니다. 즉, 무역 개방성의 한 단위 변화는 1인당 GDP로 측정된 경제규모가 163.48 증가하는 만큼의 효과를 가지고 있다는 것을 의미합니다.
여기서 결정적 기준값을 \(\beta_1 = 164.355\)라고 설정한 것은 단순선형회귀 모델에서의 무역 개방성의 계수값입니다. 따라서 이 영가설을 통해 우리는 단순선형회귀모델에서 무역 개방성과 경제 규모 간의 관계가 다중선형회귀 모델에서 다른 통제변수들이 통제된 가운데 나타나는 무역 개방성과 경제 규모 간의 관계와 다른지, 그리고 그러한 차이가 통계적으로 유의미한지를 살펴볼 수 있습니다.
그렇다면 이번에는 우리가 관심을 가지고 있는, 연구가설에 대해 살펴보겠습니다. 효과의 방향(부호)를 생각할 필요가 없는 경우(양측, two-sided)와 방향도 고려해야 하는 경우(단측, one-sided) 모두를 특정해보도록 하겠습니다.
효과가 없음이 영가설일 때(\(H_0: \beta_1 = 0\))
단측 연구가설(\(H_A: \beta_1 > 0\), 또는 \(H_A: \beta_1 < 0\)): 무역 개방성은 경제규모에 대해 긍정적 또는 부정적 효과를 가지고 있다. 이때의 연구가설은 긍정적 효과 또는 부정적 효과가 별개의 것이다.
양측 연구가설(\(H_A: \beta_1 \neq 0\)): 무역 개방성은 경제규모에 대해 ‘효과가 있다.’
연구가설이 \(H_A: \beta_1 = 164.355\)일 경우
단측 연구가설(\(H_A: \beta_1 > 164.355\), 또는 \(H_A: \beta_1 < 164.355\)): 경제규모에 영향을 미칠 수 있는 다른 요인들을 고려하지 않을 때보다 고려했을 경우(통제했을 경우), 무역 개방성이 경제규모에 미치는 효과가 더 크다/작다.
양측 연구가설(\(H_A: \beta_1 \neq 164.355\)): 경제규모에 영향을 미칠 수 있는 다른 요인들을 고려하지 않을 때와 고려했을 경우(통제했을 경우), 무역 개방성이 경제규모에 미치는 효과는 다르다(같지 않다).
이번에는 각각의 영가설과 연구가설에 대한 검정을 시행하고 그 결과를 제시 및 해석해보도록 하겠습니다.
바로 이전의 분석을 이용해보도록 하겠습니다. 단순선형회귀모델의 무역 개방성에 대한 계수와 표준오차, 자유도를 각각 객체로 저장합니다.
b1.simple <- results[2,2]
se1.simple <- results[2,3]
simple.df <- model.simple$df마찬가지로 다중선형회귀모델의 무역 개방성에 대한 계수와 표준오차, 자유도도 객체로 저장합니다.
b1.multiple <- results[4,2]
se1.multiple <- results[4,3]
multiple.df <- model.multiple$df첫 번째 연구가설 중 단측 가설입니다. 이 경우, \(H_A: \beta_1 > 0\)으로 나타낼 수 있습니다.
pt(as.numeric((b1.simple-0)/se1.simple),
simple.df, lower = FALSE)[1] 1.937543e-08분석 결과, 0.05보다 훨씬 작은 값을 확인할 수 있습니다. 즉, 영가설의 기대대로 표본에서 결과를 얻을 확률이 매우 낮다는 것이고 영가설을 기각하기에 충분한 경험적 근거를 확보했다고 할 수 있습니다.
다음으로는 양측 가설을 한 번 살펴보겠습니다. 방향을 고려할 필요가 없죠. 따라서 \(H_A: \beta_1 \neq 0\)가 됩니다.
2*pt(-abs(as.numeric((b1.simple-0)/se1.simple)),
simple.df)[1] 3.875085e-08방향을 고려할 필요가 없기 때문에 방향을 고려했을 때의 확률에 2를 곱해줍니다 (좌측 + 우측).
이번에는 두 번째 연구가설(단순 vs. 다중) 중 단측 가설입니다. \(H_A: \beta_{1\cdot \text{Multi}} > \beta_{1 \cdot \text{Simple}}\)
pt(as.numeric((b1.multiple-b1.simple)/
(se1.multiple-b1.simple)),
multiple.df, lower = FALSE)[1] 0.3673704검정 결과, 0.05보다 훨씬 큰 값을 얻어 영가설은 기각되지 않습니다. 당연합니다. 다중회귀분석에서의 무역 개방성의 계수값과 단순회귀분석의 무역 개방성의 계수값은 일단 단순회귀분석의 계수값이 더 컸습니다. 따라서 위의 연구가설, 다중회귀분석의 계수값이 단순회귀분석의 그것보다 클 것이라는 기대는 기각되는 것이 우리의 상식에 부합합니다. 그렇다면 이번에는 양측 가설을 볼까요? 양측 가설은 방향을 가정하지 않으므로 같지 않다로 놓습니다. \(H_A: \beta_{1\cdot \text{Multi}} \neq \beta_{1 \cdot \text{Simple}}\)
2*pt(-abs(as.numeric((b1.multiple-0)/
(se1.multiple-b1.simple))),
multiple.df)[1] 0.3886917방향을 고려할 필요가 없기 때문에 방향을 고려했을 때의 확률에 2를 곱해줍니다 (좌측 + 우측). 마찬가지로 영가설을 기각하기에 충분한 근거를 얻었습니다. 둘이 서로 같지 않다는 기대죠? 하지만 두 계수 값의 차이는 각 계수값이 서로 다른 표본에서 계산되어 가지게 될 표집분포에 따른 편차, 즉, 표준오차에 따라 고려했을 때, 계수의 차이가 유의미하기 보다는 표본의 차이에 따라 나타날 수 있는 차이라고 볼 수도 있습니다. 그 결과 영가설은 기각되지 않습니다. 두 효과는 통계적으로 차이가 있다고 말하기에는 영가설을 기각할 수 있는 충분한 경험적 근거를 확보하지 못한 것입니다.
\(\beta_k\)에 대한 가설검정?
가설검정에 관련된 내용은 사실 영가설과 연구가설의 기각과 채택, 연역적 접근과 귀납적 접근에 대한 이론적 논의와 동시에 모집단과 표본에 대한 이해에서 시작됩니다. 만약 이 부분들에 대한 이해가 선행되지 않는다면, 같은 것을 말하고 있는 것 같지만 사실 다른 것을 의미하는 결과로 이어지기도 합니다.
예를 들어, 누군가가 \(\beta_k\)에 대한 가설검정을 해야한다고 합시다. 대충 들었을 때는 어떤 변수가 종속변수에 미치는 효과가 통계적으로 유의미한지, 혹은 어떠한 기준값에 비해 큰지 작은지 등과 같은 가설검정을 하고 싶다는 것으로 이해할 수 있을 것입니다. 하지만 저 ’표현’에는 오류가 있습니다.
우리는 어떠한 관계를 보여주는 \(\beta\)가 모집단의 수준에서도 존재하는지 여부를 추론하기 위하여 가설을 수립합니다. 그러나 \(\beta_k\)는 단지 하나의 표본에서 추출한 하나의 통계치일 뿐입니다. 즉, 1번 표본으로부터 모집단의 \(\beta\)를 추정하기 위해 구한 것이 \(\beta_1\)이듯, \(k\)번의 표본으로부터 뽑은 통계치가 바로 \(\beta_k\)인 것입니다. 표집 과정의 본연적 한계로 인하여, 우리는 이론적으로 무수히 많은 표본들을 모집단으로부터 뽑을 수 있지만, 그 표본들로부터 얻을 수 있는 \(\beta_k\)들이 전부 동일하다고 기대할 수 없습니다. 따라서 하나의 표본에 대응하는 하나의 \(\beta_k\)에 대해 가설을 검증한다고 하는 표현은 우리가 실제로 관심을 가지고 있는 모수를 이해하는 데 있어서는 의미없다고 할 수 있습니다. 아 다르고 어 다른 것인데 이론적으로는 이렇게 큰 차이가 있습니다.
\(\beta_k\)와 \(\hat{\beta_k}\)에 대한 또 다른 접근
서로 다른 데이터를 보여주는 간단한 분포 세 개를 보도록 하겠습니다.
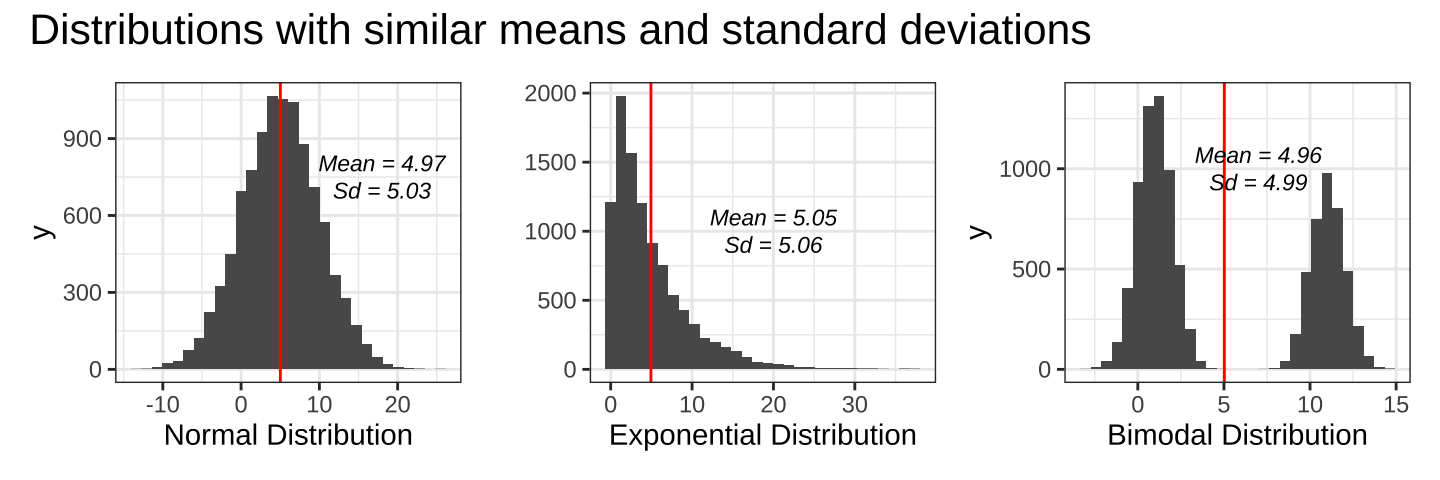
세 분포의 공통점과 차이점은 무엇일까요? 우선 세 분포는 평균(mean)과 표준편차(standard deviation)가 매우 비슷합니다. 하지만 실제 관측치들의 분포 양상은 매우 다르죠. 첫 번째 분포는 정규분포를 따른다면, 두 번째 분포는 지수분포, 마지막 분포는 크게 양극화된 양봉분포(bimodal distribution)의 형태를 띄고 있습니다.
단순히 데이터를 평균과 표준편차만으로 섣불리 이해할 경우 그 데이터를 이용한 통계적 추론에서 오류를 범할 수 있습니다. 따라서 우리는 ‘보다 구조화된’ (more structured) 접근법을 취할 필요가 있습니다.
우선 가장 클래식한 선형회귀모델의 가정들을 다시 한 번 생각해보겠습니다. 총 다섯 개의 세부 가정으로 살펴볼 수 있는데, 순서대로 다중선형회귀분석(Multiple linear regression)에 대한 가정이라는 의미로 MLR라고 라벨링을 해보도록 하겠습니다. 어디까지나 여기서 클래식한 다중선형회귀분석의 가정들은 교차사례(cross-sectional) 자료에 적용가능합니다. 시계열(time-series)이 포함되면 또 고려해야할 문제들이 있기 때문인데, 이는 아마 고급 통계파트의 자료에서 다루게 될 것 같습니다.
MLR1. 모집단에서의 모수들의 관계가 선형이다.
MLR2. 무작위로 추출된 표본이다.
MLR3. 설명변수들 간의 완벽한 다중공선성은 존재하지 않는다.
MLR4. 설명변수와 오차는 독립적이다(Zero-conditional mean)
주어진 설명변수라는 조건 하에서 오차항(\(u\))의 기대값은 0이다.
만약 이 가정이 성립되지 않는다면 우리는 모델 특정에 문제가 있었다고 생각할 수 있다. 예를 들면, 종속변수에 영향을 미치는 적절한 변수를 모델에 포함시키지 않아 오차항이 설명변수와 상관성을 가진다고 볼 수 있다.
이 MLR4는 선형회귀분석의 추정치, 계수의 편향성 문제와 매우 밀접한 관계를 가진다.
MLR5. (오차항의) 동분산성
주어진 설명변수들에 대해 오차항의 조건 분포가 일정해야 한다.
만약 오차항이 이분산성(heteroskedasticity)을 띈다고 하더라도 그것이 OLS 추정치가 편향되었다는 것을 의미하지는 않는다.
다만 OLS 추정치의 ’효율성’이 낮다는 것을 의미한다. 즉, OLS 중
least의 조건 최소 분산(least variance)이 아니라는 것을 의미할 뿐이다.
MLR1부터 MLR5까지가 충족되었을 때, 우리는 OLS의 결과를
BLUE(BestLinearUnbiasedEstimates)라고 한다.
자, 이 다섯 가정을 우리는 한 데 묶어서 Gauss-Markov 가정이라고 합니다. 이 클래식한 선형회귀모델의 가정을 조금 단순하게 묶어보자면 다음과 같이 표현할 수 있을 것 같습니다.
\(E(\hat{\beta}_k) = \beta_k\). 당연하겠죠? 만약
BLUE라면 우리가 표본들로부터 얻는 평균들의 평균이 모집단의 기대값과 일치할 거라는 가정 또한 충족될 것입니다.\(Var(\hat{\beta}_k)\)는 표본들로부터 얻은 평균들의 분산으로 어떠한 값을 가지게 될 것입니다. 뭐, 놀랄 건 아니죠. 모집단에서 표본을 추출하는 것은 본연적으로 일정한 오류를 내재하게 되어있기 때문에 평균들도 항상 모집단의 기대값과 같지는 않을 것이고, 그런 표본들의 평균들 간의 차이는 일종의 분산으로 나타날 것이니까요.
그런데 여기서 우리는 위의 두 발견으로부터 하나의 식을 도출해낼 수 있습니다. 만약 우리가 구한 OLS 추정치가 BLUE라면? 그래서 위의 두 조건이 충족된다면? 우리는 표본들로부터 구한 평균들이 어떠한 분포를 보일 것이라고 생각해볼 수 있습니다. 바로 모집단의 기대값을 보여줄 \(E(\hat{\beta}_k)\)를 중심으로 \(Var(\hat{\beta}_k)\)라는 분산을 가진 정규분포입니다. \[
\hat{\beta}_k \sim N(\hat{\beta}_k, Var(\hat{\beta}_k))
\]
보통 통계학을 공부하다가 유의수준, 유의값, 신뢰구간 등을 배울 때 보면 순서가 연구가설/대안가설과 영가설의 관계, 가설 기각의 의미, 유의값의 의미, 그리고 잠정적인 1종오류와 2종오류의 문제, 점추정과 구간추정의 개념에서 살펴볼 수 있는 계수값과 신뢰구간의 관계와 의미 등으로 전개되는 것을 확인할 수 있습니다. 아마 Lv.1.Stats_R에서도 비슷한 접근법을 취했을 겁니다. 여기서는 조금 다른 방식으로 해당 주제들을 다루어보고자 합니다.
앞서 살펴보았던 \(\hat{\beta}_k \sim N(\hat{\beta}_k, Var(\hat{\beta}_k))\)가 성립한다고 할 때, 우리가 “알 수 있는 것”과 “알 수 없는 것”은 무엇일까요?
먼저 우리가 알 수 있는 것은 크게 세 가지라고 할 수 있습니다. 우리가 가지고 있는 예측변수이자 확률변수인 \(x\)가 어떠한 평균과 분산을 가진 정규분포를 따를 것이라는 것을 알 수 있습니다: \(x\text{에 대한 분포} \sim N(\mu, \tau^2): \frac{1}{2\sqrt{\tau^2\pi}}\text{exp}[-\frac{(x-\mu)^2}{2\tau^2}]\). 그리고 실제로 표본을 통해서 \(\hat{\beta_k}\)와 \(Var{\hat{\beta_k}}\)도 구할 수 있습니다.
반면에 모집단의 모수, \(\beta_k\)는 알 수 없습니다.
만약 우리가 \(\beta_k\)에 대한 가정을 세울 수 있고, 이론적 분석이 아니라 실제 경험적 데이터를 통해 그러한 가정이 충족되는지 아닌지를 확인할 수 있다면 어떻게 될까요?
Confidence intervals
영가설 유의성 검정, 즉 NHST에서 우리는 이미 \(\alpha\)에 대해서 살펴보았습니다. 알 수 없는 모수 \(\beta_k\)에 대한 알고 있는 통계치 \(\hat{\beta_k}\)를 바탕으로 한 분포의 가정에서 우리는 다시 이 \(\alpha\)로 돌아옵니다. \(\alpha\)라는 개념의 바탕에는 “이론적으로 무수히 많은 표본”이 전제되어 있습니다. 적어도 이론적 수준에서 우리는 하나의 모집단으로부터 수많은 표본을 반복하여 추출할 수 있습니다. 그렇게 무수히 많은 표본들로부터 얻은 통계치의 분포를 표집분포(sampling distribution)이라고 할 수 있고, 그 표집분포를 바탕으로 우리는 얼마나 많은 표본이 영가설의 기대에 부합하는 통계치를 가지는지, 전체 표본에서 그러한 표본의 비율을 \(\alpha\)라고 나타냅니다. 따라서 흔히 사용하는 유의수준 0.05라는 기준은 이런 맥락에서 보자면 “100번의 반복 추출된 표본 중에서 5개의 표본의 표본평균이 영가설의 기대를 포함하고 있을 경우”를 말한다고 할 수 있습니다. 그러면 \(\alpha\)는 조금 더 직관적으로 이해할 수 있습니다.
\(\alpha\)는 표집분포에 있어서 일종의 꼬리확률(tail probability)이라고 생각할 수 있습니다.
신뢰구간은 우리가 일반적으로 모수가 그 사이에 존재할 것이라고 기대하는 구간입니다.
반복해서 추출한 표본들에 대해 95%의 신뢰구간은 100번 추출한 표본의 \(\hat{\beta_k}\) 중에서 95개의 표본이 모수 \(\beta_k\)를 포함한다고 기대할 수 있습니다.
신뢰구간 구하기
표집분포로부터 우리는 \(\frac{\hat{\beta_k}-\beta_k}{se(\hat{\beta})} \sim N(0,1)\)이라는 것을 알 수 있습니다. 이건 t죠. 풀어서 말하자면 표본들을 통해 얻은 통계치들과 모수와의 차이를 표집 과정에서 나타날 수 있는 오차로 나누어준 값의 분포를 구할 수 있다는 겁니다. 일종의 표준화 작업을 해주었으니 분포는 평균 0을 갖는 정규분포로 수렴하게 될 것입니다. 여기서 평균이 0이라는 얘기는 어떤 표본에서 얻은 통계치가 완벽하게 모수의 값과 일치한다는 얘기겠죠?
95%의 신뢰구간을 양측꼬리확률로 생각해보겠습니다. 표집분포로 얘기해보자면 1000개의 표본 중 950개는 신뢰구간에 모수의 값을 포함하고 있지만 50개는 포함하지 않는 표본이라는 얘기일 것입니다. 그런데 이때 \(\hat{\beta_k}\)는 모수보다 매우 커서 신뢰구간에 모수의 값을 포함하지 않을 수도 있고, 모수보다 매우 작아서 그럴 수도 있습니다. 즉, 분포의 좌측과 우측 모두에서 모수를 포함하지 않을 확률을 더해서 5%라는 것입니다. 그렇다면 이를 분위(quantiles)로 보면 1000개의 표본에서 얻은 \(\hat{\beta_k}\)를 작은 값부터 큰 값까지 일렬로 줄을 세운다고 할 때, 제일값이 작은 통계치를 가진 표본부터 25번째로 작은 표본까지와 975번째로 작은 표본부터 마지막 표본까지가 이 5%에 해당할 것입니다. 그렇다면 기준점은? 25번째 표본에 해당하는 값과 975번째에 해당하는 값이겠죠(2.5th Quantile, 97.5th Quantile)? 이미 본 적이 있습니다. 정규분포에서 해당하는 확률을 가지는 t값은 $$1.96입니다. 그렇다면 우리는 95% 신뢰구간을 이론적으로는 평균에서 $\(1.96\)$표준오차를 통해, 만약 1000개의 표본이 있다면 2.5분위와 97.5분위에 해당하는 값을 기준으로 삼을 수 있을 것입니다. 99%의 신뢰구간도 마찬가지일 것입니다. 정리하자면 신뢰구간은 이론적으로 표본평균과 표준오차를 알고 있다면 다음과 같이 구할 수 있을 것입니다.
\[ \begin{align} \text{95% 신뢰구간}:&[\hat{\beta_k} - 1.96 \times se(\hat{\beta_k}),\;\;\;\; \hat{\beta_k} + 1.96 \times se(\hat{\beta_k})].\\ \text{99% 신뢰구간}:&[\hat{\beta_k} - 2.58 \times se(\hat{\beta_k}),\;\;\;\; \hat{\beta_k} + 2.58 \times se(\hat{\beta_k})]. \end{align} \]
여기까지는 앞서 살펴보았던 NHST의 과정과 크게 다르지 않습니다. 그런데 주목해야할 것은 우리가 아까 \(\beta_k\)와 \(\hat{\beta_k}\), 그리고 \(Var(\hat{\beta_k})\) 간의 관계를 일종의 분포로 보여주었던 가정입니다.
과연 실제로도 무수히 많은 표본을 뽑았을 때, 이론적 기대와 같은 분포가 나타날까?
만약 \(\beta_k\)가
OLS의 가정인 Gaus-Markov 가정을 충족시켜 얻어낸BLUE라고 한다면, 그래서 우리가 \(\hat{\beta}_k \sim N(\hat{\beta}_k, Var(\hat{\beta}_k))\)라고 할 수 있다면? 이러한 조건을 가진 분포에서 실제로 표집분포처럼 표본을 추출해서 이론적으로 설정된 신뢰구간이 아닌 정말로 2.5분위와 97.5분위에 해당하는 값을 통해 신뢰구간을 보여줄 수 있지 않을까요? 아니, 나아가 보다 구체적으로 \(\hat{\beta_k}\)의 분포를 직접적으로 보여줄 수 있지 않을까요?
Footnotes
불편추정량을 의미합니다. Best Unbiased Linear Estimator.↩︎
다만 이것은 통계적 진단일 뿐입니다. 극단적인 값을 지니는 이른바 이탈치(outliers)에 대한 처치를 어떻게 할 것인가는 연구자의 관점에 좌우됩니다. 자세한 논의는 김웅진. 2016. “Deviant Case in the Social Scientific Generalization: A Methodological Discourse on the Analytic Conventions for Detecting Deviance.” 21세기정치학회보. 26권 4호, pp. 49-66. 또는 김웅진. 2016. “사회과학적 개념의 방법론적 경직성 : 국소성과 맥락성의 의도적 훼손.” 국제지역연구. 19권 4호, pp. 3-22.를 읽어보시기 바랍니다.↩︎
여기서 \(c\)는 결정적 기준값, critical value를 의미합니다.↩︎