# 필요한 패키지를 로드합니다
library(tidyverse)
library(tidyr)Improving Converting Data Frames between Long and Wide Formats
From Wide to Long
많은 데이셋들이 엑셀과 같은 스프레드시트 프로그램에서 생성되거나 정리됩니다. 이러한 프로그램은 데이터를 쉽게 입력하고 시각적으로 검토할 수 있도록 최적화되어 있습니다. 그 결과, 사람들은 잘 정돈되지 않은 데이터를 작성하는 경향이 있습니다. 예를 들면, 표를 병합하거나 표의 여러 줄을 중첩된 헤더(header)로 설정하는 것 등의 문제입니다. 구체적으로 정돈되지 않은 데이터(untidy data)라고 하면 다음의 세 가지 원칙 중 하나를 위반한 경우를 생각해볼 수 있습니다(Wickham, 2014):
각 열이 각 변수를 형성합니다.
각 관측치가 각 행을 형성합니다.
변수와 관측치의 단위는 표의 형태로 나타낼 수 있습니다.
정돈되지 않은 데이터셋에서는 물리적 레이아웃이 데이터가 가져야할 실질적인 의미(혹은 정보)와 유기적으로 연계되지 않는다고 말할 수도 있습니다(Neo, 2020).
동료로부터 다음과 같은 데이터셋을 받았다고 가정해봅시다. A와 B는 3주 동안 한 주에 얼마나 자주 달렸는지 표시했다고 할 때, w-1에서 w-3 열은 1주에서 3주 각각의 달리기를 빈도를 나타냅니다:
(running_data <- tribble(
~person, ~group, ~`w-1`, ~`w-2`, ~`w-3`,
"John", "a", 4, NA, 2,
"Marie", "a", 2, 7, 3,
"Jane", "b", 3, 8, 9,
"Peter", "b", 1, 3, 3))# A tibble: 4 × 5
person group `w-1` `w-2` `w-3`
<chr> <chr> <dbl> <dbl> <dbl>
1 John a 4 NA 2
2 Marie a 2 7 3
3 Jane b 3 8 9
4 Peter b 1 3 3이 데이터 프레임은 모든 열이 변수를 나타내는 것은 아니기 때문에 정돈된 데이터셋이라고 하기 어렵습니다. Wickham (2014: 3)에 따르면 변수는 “여러 단위에서 동일한 기본 속성(예: 고도, 온도, 지속 시간)을 측정하는 모든 값”을 포함합니다. 그러나 데이터 프레임에서 열 w-1, w-2 및 w-3은 열에는 나타나지 않는 주(week)의 값을 나타냅니다. 이 데이터 프레임을 깔끔하게 표현하면 다음과 같습니다:
running_data |>
pivot_longer(
cols = `w-1`:`w-3`,
names_to = "week",
values_to = "value"
)# A tibble: 12 × 4
person group week value
<chr> <chr> <chr> <dbl>
1 John a w-1 4
2 John a w-2 NA
3 John a w-3 2
4 Marie a w-1 2
5 Marie a w-2 7
6 Marie a w-3 3
7 Jane b w-1 3
8 Jane b w-2 8
9 Jane b w-3 9
10 Peter b w-1 1
11 Peter b w-2 3
12 Peter b w-3 3이 시간에는 데이터 프레임을 목적에 맞게 변형하기 위한 pivot_longer(), pivot_wider() 함수를 살펴볼 것입니다. 즉, 데이터를 필요에 따라 그 형태를 변형하여 데이터 프레임을 길게 만드는 방법(long-form), 넓게 만드는 방법(wide-form)으로 만드는 방법을 학습합니다.
데이터 프레임은 행의 수를 늘리고 열의 수를 줄이면 길어집니다(
pivot참조). 따라서 정돈되지 않은 데이터셋을 정리하면 기본적으로 데이터셋이 길어지게 됩니다.다음 섹션에서는 깔끔하지 않은 데이터를 정리하고
pivot_longer()를 사용하여 데이터를 긴 형태로 만드는 몇 가지 일반적인 사용 사례를 살펴보겠습니다. 사용 사례는 주로 Wickham (2014)에서 차용하였습니다:열 헤더가 변수 이름이 아닌 하나의 변수가 될 수 있는 값일 경우입니다. 예를 들어, 변수명이 “1주차”부터 “20주차”까지 주차별로 있다고 할 때, 사실 이 변수명들은 “주차”라는 이름으로 1부터 20까지의 값을 갖는 정보로 변환될 수 있습니다.
여러 개의 변수가 하나의 열에 저장되는 경우입니다.
변수가 행과 열에 모두 저장된 경우입니다.
Column Headers Are Values of One Variable, Not Variable Names
running_data 데이터셋에서 이미 이 문제가 존재하는 것을 확인한 바 있습니다. 즉, 종종 데이터셋에는 변수명이 아닌 값을 나타내는 열이 포함되어 있습니다:
running_data |> colnames()[1] "person" "group" "w-1" "w-2" "w-3" 이 데이터 프레임을 더 길고(longer) 깔끔하게(tidy) 만들려면 pivot_longer에 이 네 가지 파라미터(parameters)에 대한 인수(arguments)를 지정해야 합니다:
data: 길게 만들 데이터 프레임columns: 더 긴 형식으로 변환해야 하는 열입니다.names_to: 열의 이름을 포함할 새 열의 이름입니다.values_to: 열 내부의 값을 포함할 새 열의 이름입니다.
즉, 원래의 데이터 프레임에서 옆으로 늘어져 있는 열을 그러모아 하나의 변수로 치환하는 과정입니다. 함수를 실행하고 결과가 어떻게 표시되는지 확인해 보겠습니다:
running_data |>
pivot_longer(
cols = `w-1`:`w-3`,
names_to = "week",
values_to = "value"
)# A tibble: 12 × 4
person group week value
<chr> <chr> <chr> <dbl>
1 John a w-1 4
2 John a w-2 NA
3 John a w-3 2
4 Marie a w-1 2
5 Marie a w-2 7
6 Marie a w-3 3
7 Jane b w-1 3
8 Jane b w-2 8
9 Jane b w-3 9
10 Peter b w-1 1
11 Peter b w-2 3
12 Peter b w-3 3![]()
기존의 데이터 프레임에는 20개의 값이 있었지만, 길게 변환한 데이터 프레임에는 48개의 값이 있습니다. 값의 수가 두 배 이상 늘어났습니다. 그 이유는 week 열에서 이전 열 이름(w-1, w-2 등)을 배치하고 person 및 group 열의 값도 그에 따라 복제했기 때문입니다.
week 열의 접두사를 제거하면 이 코드를 더욱 개선할 수 있습니다. 예를 들어, w-1은 1로 표시되어야 합니다.
running_data |>
pivot_longer(
cols = `w-1`:`w-3`,
names_to = "week",
values_to = "value",
names_prefix = "w-")# A tibble: 12 × 4
person group week value
<chr> <chr> <chr> <dbl>
1 John a 1 4
2 John a 2 NA
3 John a 3 2
4 Marie a 1 2
5 Marie a 2 7
6 Marie a 3 3
7 Jane b 1 3
8 Jane b 2 8
9 Jane b 3 9
10 Peter b 1 1
11 Peter b 2 3
12 Peter b 3 3![]()
변수 week가 숫자형이 아닌 문자형 변수라는 것을 알 수 있습니다. names_to 열의 데이터 유형을 변환하려면 names_transform 파라미터를 사용할 수 있습니다:
running_data |>
pivot_longer(
cols = `w-1`:`w-3`,
names_to = "week",
values_to = "value",
names_prefix = "w-",
names_transform = as.double)# A tibble: 12 × 4
person group week value
<chr> <chr> <dbl> <dbl>
1 John a 1 4
2 John a 2 NA
3 John a 3 2
4 Marie a 1 2
5 Marie a 2 7
6 Marie a 3 3
7 Jane b 1 3
8 Jane b 2 8
9 Jane b 3 9
10 Peter b 1 1
11 Peter b 2 3
12 Peter b 3 3마찬가지로 values_transform을 사용하여 values_to 열의 데이터 유형을 변환할 수 있습니다. 여기서는 정수형 변수를 요인형으로 변환해보도록 하겠습니다:
running_data |>
pivot_longer(
cols = `w-1`:`w-3`,
names_to = "week",
values_to = "value",
names_prefix = "w-",
values_transform = as.factor)# A tibble: 12 × 4
person group week value
<chr> <chr> <chr> <fct>
1 John a 1 4
2 John a 2 <NA>
3 John a 3 2
4 Marie a 1 2
5 Marie a 2 7
6 Marie a 3 3
7 Jane b 1 3
8 Jane b 2 8
9 Jane b 3 9
10 Peter b 1 1
11 Peter b 2 3
12 Peter b 3 3 다음은 열 헤더가 값을 나타내는 또 다른 예제입니다:
relig_income# A tibble: 18 × 11
religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` `$75-100k`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Agnostic 27 34 60 81 76 137 122
2 Atheist 12 27 37 52 35 70 73
3 Buddhist 27 21 30 34 33 58 62
4 Catholic 418 617 732 670 638 1116 949
5 Don’t k… 15 14 15 11 10 35 21
6 Evangel… 575 869 1064 982 881 1486 949
7 Hindu 1 9 7 9 11 34 47
8 Histori… 228 244 236 238 197 223 131
9 Jehovah… 20 27 24 24 21 30 15
10 Jewish 19 19 25 25 30 95 69
11 Mainlin… 289 495 619 655 651 1107 939
12 Mormon 29 40 48 51 56 112 85
13 Muslim 6 7 9 10 9 23 16
14 Orthodox 13 17 23 32 32 47 38
15 Other C… 9 7 11 13 13 14 18
16 Other F… 20 33 40 46 49 63 46
17 Other W… 5 2 3 4 2 7 3
18 Unaffil… 217 299 374 365 341 528 407
# ℹ 3 more variables: `$100-150k` <dbl>, `>150k` <dbl>,
# `Don't know/refused` <dbl>$10k에서 Don't know/Refused에 해당하는 열들은 소득 변수들입니다. 이 변수들의 값은 개인의 특정 소득을 보고한 빈도라고 이해하면 됩니다. 이 데이터 프레임을 길게, 깔끔하게 정리해 보겠습니다:
relig_income |>
pivot_longer(
cols = `<$10k`:`Don't know/refused`,
names_to = "income",
values_to = "freq")# A tibble: 180 × 3
religion income freq
<chr> <chr> <dbl>
1 Agnostic <$10k 27
2 Agnostic $10-20k 34
3 Agnostic $20-30k 60
4 Agnostic $30-40k 81
5 Agnostic $40-50k 76
6 Agnostic $50-75k 137
7 Agnostic $75-100k 122
8 Agnostic $100-150k 109
9 Agnostic >150k 84
10 Agnostic Don't know/refused 96
# ℹ 170 more rows다시 말하지만, 깔끔한 데이터 프레임에는 깔끔하지 않은 데이터 프레임(18*11 = 198)보다 더 많은 값(180*3 = 540)이 있습니다. 그렇다면 왜 처음에 데이터 프레임은 198개의 깔끔하지 않은 형태로 저장되었던 것일까요? 일반적으로 사용하는 스프레드시트 소프트웨어는 데이터의 특성 상 데이터 입력 당시 540개보다 198개의 값으로 작업하는 것이 더 쉬웠기 때문입니다. 하지만 R을 이용한 데이터 분석에서는 깔끔한 데이터를 구축하는 것이 더 중요합니다.
마지막으로, 또 다른 예입니다. 데이터셋 billboard 에는 2000년의 상위 빌보드 순위가 포함되어 있습니다:
billboard# A tibble: 317 × 79
artist track date.entered wk1 wk2 wk3 wk4 wk5 wk6 wk7 wk8
<chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 Pac Baby… 2000-02-26 87 82 72 77 87 94 99 NA
2 2Ge+her The … 2000-09-02 91 87 92 NA NA NA NA NA
3 3 Doors D… Kryp… 2000-04-08 81 70 68 67 66 57 54 53
4 3 Doors D… Loser 2000-10-21 76 76 72 69 67 65 55 59
5 504 Boyz Wobb… 2000-04-15 57 34 25 17 17 31 36 49
6 98^0 Give… 2000-08-19 51 39 34 26 26 19 2 2
7 A*Teens Danc… 2000-07-08 97 97 96 95 100 NA NA NA
8 Aaliyah I Do… 2000-01-29 84 62 51 41 38 35 35 38
9 Aaliyah Try … 2000-03-18 59 53 38 28 21 18 16 14
10 Adams, Yo… Open… 2000-08-26 76 76 74 69 68 67 61 58
# ℹ 307 more rows
# ℹ 68 more variables: wk9 <dbl>, wk10 <dbl>, wk11 <dbl>, wk12 <dbl>,
# wk13 <dbl>, wk14 <dbl>, wk15 <dbl>, wk16 <dbl>, wk17 <dbl>, wk18 <dbl>,
# wk19 <dbl>, wk20 <dbl>, wk21 <dbl>, wk22 <dbl>, wk23 <dbl>, wk24 <dbl>,
# wk25 <dbl>, wk26 <dbl>, wk27 <dbl>, wk28 <dbl>, wk29 <dbl>, wk30 <dbl>,
# wk31 <dbl>, wk32 <dbl>, wk33 <dbl>, wk34 <dbl>, wk35 <dbl>, wk36 <dbl>,
# wk37 <dbl>, wk38 <dbl>, wk39 <dbl>, wk40 <dbl>, wk41 <dbl>, wk42 <dbl>, …열을 살펴보면 변수가 아닌 변화하는 주의 값을 가지는 열 이름이 무려 76개(wk1~wk76)나 됩니다:
billboard |> colnames() [1] "artist" "track" "date.entered" "wk1" "wk2"
[6] "wk3" "wk4" "wk5" "wk6" "wk7"
[11] "wk8" "wk9" "wk10" "wk11" "wk12"
[16] "wk13" "wk14" "wk15" "wk16" "wk17"
[21] "wk18" "wk19" "wk20" "wk21" "wk22"
[26] "wk23" "wk24" "wk25" "wk26" "wk27"
[31] "wk28" "wk29" "wk30" "wk31" "wk32"
[36] "wk33" "wk34" "wk35" "wk36" "wk37"
[41] "wk38" "wk39" "wk40" "wk41" "wk42"
[46] "wk43" "wk44" "wk45" "wk46" "wk47"
[51] "wk48" "wk49" "wk50" "wk51" "wk52"
[56] "wk53" "wk54" "wk55" "wk56" "wk57"
[61] "wk58" "wk59" "wk60" "wk61" "wk62"
[66] "wk63" "wk64" "wk65" "wk66" "wk67"
[71] "wk68" "wk69" "wk70" "wk71" "wk72"
[76] "wk73" "wk74" "wk75" "wk76" 이 데이터 프레임은 이전 예제보다 훨씬 크지만 동일한 함수와 파라미터를 사용하여 길게 변환하여 깔끔하게 정리할 수 있습니다:
billboard |>
pivot_longer(
cols = contains("wk"),
names_to = "week",
values_to = "value",
names_prefix = "^wk",
names_transform = as.double)# A tibble: 24,092 × 5
artist track date.entered week value
<chr> <chr> <date> <dbl> <dbl>
1 2 Pac Baby Don't Cry (Keep... 2000-02-26 1 87
2 2 Pac Baby Don't Cry (Keep... 2000-02-26 2 82
3 2 Pac Baby Don't Cry (Keep... 2000-02-26 3 72
4 2 Pac Baby Don't Cry (Keep... 2000-02-26 4 77
5 2 Pac Baby Don't Cry (Keep... 2000-02-26 5 87
6 2 Pac Baby Don't Cry (Keep... 2000-02-26 6 94
7 2 Pac Baby Don't Cry (Keep... 2000-02-26 7 99
8 2 Pac Baby Don't Cry (Keep... 2000-02-26 8 NA
9 2 Pac Baby Don't Cry (Keep... 2000-02-26 9 NA
10 2 Pac Baby Don't Cry (Keep... 2000-02-26 10 NA
# ℹ 24,082 more rowsMultiple Variables Are Stored in Columns
앞에서는 열에 사용된 열이 단일 변수의 모든 값을 나타낸다고 가정할 수 있었기 때문에 상대적으로 이해하기가 쉬웠습니다. 즉, 열 하나가 곧 변수 하나를 온전히 보여준다고 생각한 것입니다. 하지만 항상 그런 것은 아닙니다.
anscombe x1 x2 x3 x4 y1 y2 y3 y4
1 10 10 10 8 8.04 9.14 7.46 6.58
2 8 8 8 8 6.95 8.14 6.77 5.76
3 13 13 13 8 7.58 8.74 12.74 7.71
4 9 9 9 8 8.81 8.77 7.11 8.84
5 11 11 11 8 8.33 9.26 7.81 8.47
6 14 14 14 8 9.96 8.10 8.84 7.04
7 6 6 6 8 7.24 6.13 6.08 5.25
8 4 4 4 19 4.26 3.10 5.39 12.50
9 12 12 12 8 10.84 9.13 8.15 5.56
10 7 7 7 8 4.82 7.26 6.42 7.91
11 5 5 5 8 5.68 4.74 5.73 6.89이 데이터 프레임을 길게 변환해보도록 하겠습니다. x는 x축의 값을 나타내고 y는 y축의 값을 나타냅니다. 즉, 열 이름은 x와 y라는 두 개의 변수를 나타냅니다. pivot_longer 논리를 이 데이터셋에 적용하더라도 우리는 x와 y라는 별개의 정보를 각각 포착할 수 없습니다:
anscombe |>
pivot_longer(
cols = x1:y4,
names_to = "axis",
values_to = "value")# A tibble: 88 × 2
axis value
<chr> <dbl>
1 x1 10
2 x2 10
3 x3 10
4 x4 8
5 y1 8.04
6 y2 9.14
7 y3 7.46
8 y4 6.58
9 x1 8
10 x2 8
# ℹ 78 more rowsnames_to에 두 개의 새 변수 열을 만들려면 .value와 names_pattern 이라고 하는 파라미터들을 사용해야 합니다:
![]()
여기서 가장 모호한 요소는 .value입니다. .value의 기능을 이해하기 위해 먼저 names_pattern에 대해 설명하겠습니다.
names_pattern은 정규표현식(regular expression)을 받습니다. 정규 표현식의 세계에서는 괄호로 묶인 것을 그룹이라고 합니다. 그룹을 사용하면 함께 속하는 문자열의 일부를 캡처할 수 있습니다.이 예에서 첫 번째 그룹(
.{3})은 문자열의 처음 세 글자를 포함합니다.두 번째 그룹(
.{1})에는 이 문자열의 네 번째 문자가 포함되어 있습니다.
names_to의 벡터 길이가names_pattern에 정의된 그룹 수와 같다는 것을 알 수 있습니다.즉, 이 벡터의 요소는 그룹을 나타냅니다.
첫 번째 그룹을 보면
one과two라는 두 개의 서로 다른 요소가 있습니다..value는 이 두 요소를 담기 위한 자리를 마련하는 파라미터입니다. 각 요소에 대해 정규표현식에 캡처된 텍스트로 새 열이 생성됩니다.
(anscombe_tidy <- anscombe |>
pivot_longer(
cols = x1:y4,
names_to = c(".value", "number"),
names_pattern = "([xy])(\\d+)"))# A tibble: 44 × 3
number x y
<chr> <dbl> <dbl>
1 1 10 8.04
2 2 10 9.14
3 3 10 7.46
4 4 8 6.58
5 1 8 6.95
6 2 8 8.14
7 3 8 6.77
8 4 8 5.76
9 1 13 7.58
10 2 13 8.74
# ℹ 34 more rows위에서 사용된 정규표현식에 대해 간단한 설명을 하자면, names_pattern에 투입된 정규표현식에는 두 개의 그룹이 있습니다: "([xy])(\\d+)".
첫 번째 그룹(
([xy]))은 문자x또는y를 캡처합니다.두 번째 그룹(
(\\d+))은 하나 이상의 숫자를 캡처합니다.
이제 깔끔한 데이터를 확보했으므로 Anscombe 데이터셋을 이용해 자료를 시각화할 수 있습니다:
anscombe_tidy |>
ggplot(aes(x = x, y = y)) +
geom_point() +
facet_wrap(vars(number))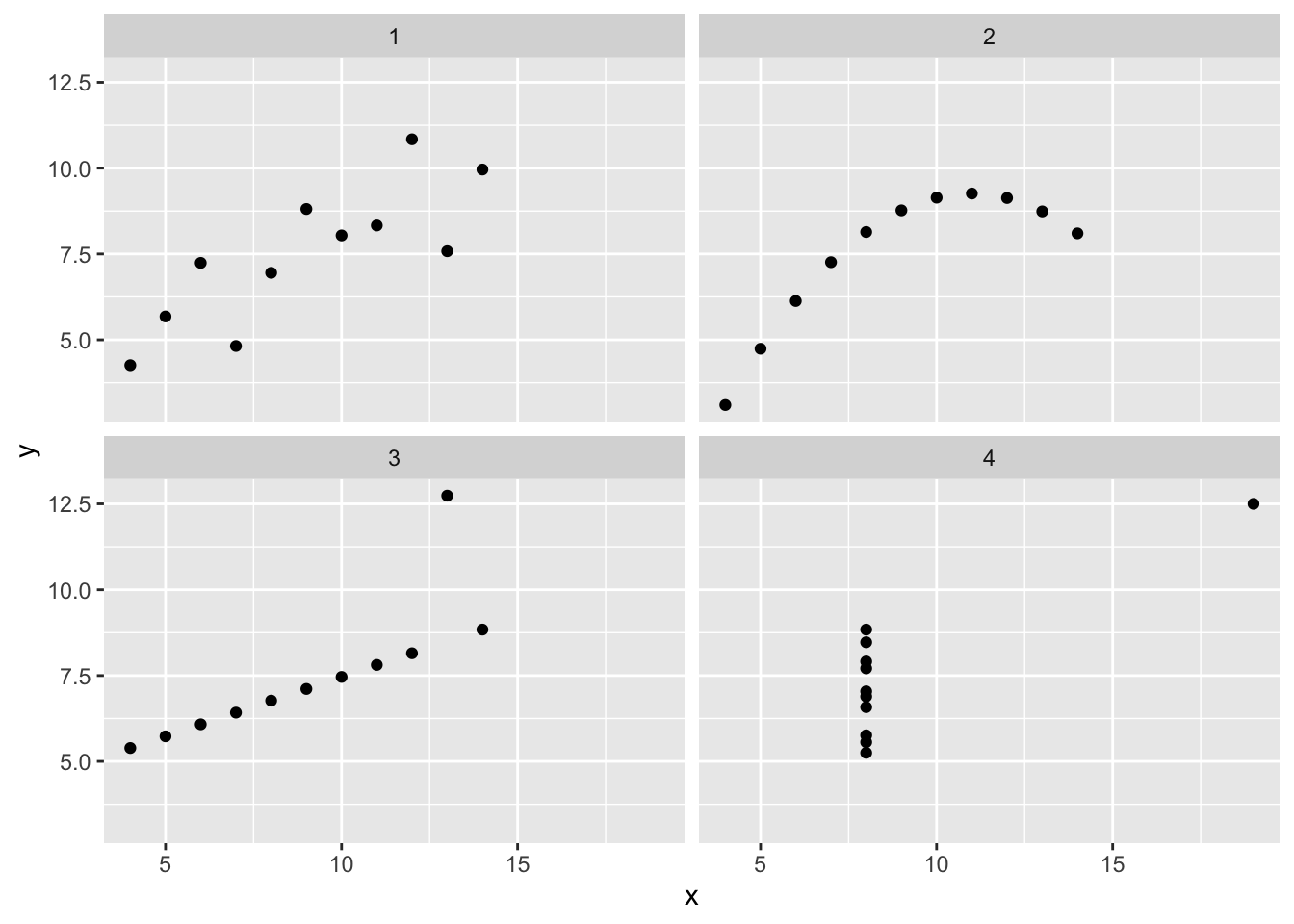
이 데이터는 동일한 기술통계값(예: 평균, 표준 편차)을 갖지만 시각적으로 서로 다른 것처럼 보이는 네 가지 데이터셋을 나타냅니다(Anscombe Quartet).
Multiple Variables Are Stored in One Column
다른 예제를 살펴보겠습니다. who 데이터셋은 세계보건기구에서 제공합니다. 이 데이터셋은 국가, 연도 및 인구 별로 결핵 확진 사례를 기록합니다. 인구 그룹은 성별과 연령입니다. 사례는 네 가지 유형으로 분류됩니다: rel = relapse, sn = negative lung smear, sp = positive lung smear, ep = extrapulmonary.
who# A tibble: 7,240 × 60
country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 new_sp_m3544
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghani… AF AFG 1980 NA NA NA NA
2 Afghani… AF AFG 1981 NA NA NA NA
3 Afghani… AF AFG 1982 NA NA NA NA
4 Afghani… AF AFG 1983 NA NA NA NA
5 Afghani… AF AFG 1984 NA NA NA NA
6 Afghani… AF AFG 1985 NA NA NA NA
7 Afghani… AF AFG 1986 NA NA NA NA
8 Afghani… AF AFG 1987 NA NA NA NA
9 Afghani… AF AFG 1988 NA NA NA NA
10 Afghani… AF AFG 1989 NA NA NA NA
# ℹ 7,230 more rows
# ℹ 52 more variables: new_sp_m4554 <dbl>, new_sp_m5564 <dbl>,
# new_sp_m65 <dbl>, new_sp_f014 <dbl>, new_sp_f1524 <dbl>,
# new_sp_f2534 <dbl>, new_sp_f3544 <dbl>, new_sp_f4554 <dbl>,
# new_sp_f5564 <dbl>, new_sp_f65 <dbl>, new_sn_m014 <dbl>,
# new_sn_m1524 <dbl>, new_sn_m2534 <dbl>, new_sn_m3544 <dbl>,
# new_sn_m4554 <dbl>, new_sn_m5564 <dbl>, new_sn_m65 <dbl>, …who |> colnames() [1] "country" "iso2" "iso3" "year" "new_sp_m014"
[6] "new_sp_m1524" "new_sp_m2534" "new_sp_m3544" "new_sp_m4554" "new_sp_m5564"
[11] "new_sp_m65" "new_sp_f014" "new_sp_f1524" "new_sp_f2534" "new_sp_f3544"
[16] "new_sp_f4554" "new_sp_f5564" "new_sp_f65" "new_sn_m014" "new_sn_m1524"
[21] "new_sn_m2534" "new_sn_m3544" "new_sn_m4554" "new_sn_m5564" "new_sn_m65"
[26] "new_sn_f014" "new_sn_f1524" "new_sn_f2534" "new_sn_f3544" "new_sn_f4554"
[31] "new_sn_f5564" "new_sn_f65" "new_ep_m014" "new_ep_m1524" "new_ep_m2534"
[36] "new_ep_m3544" "new_ep_m4554" "new_ep_m5564" "new_ep_m65" "new_ep_f014"
[41] "new_ep_f1524" "new_ep_f2534" "new_ep_f3544" "new_ep_f4554" "new_ep_f5564"
[46] "new_ep_f65" "newrel_m014" "newrel_m1524" "newrel_m2534" "newrel_m3544"
[51] "newrel_m4554" "newrel_m5564" "newrel_m65" "newrel_f014" "newrel_f1524"
[56] "newrel_f2534" "newrel_f3544" "newrel_f4554" "newrel_f5564" "newrel_f65" 이 데이터 프레임에서 주요 변수인 type, cases, age 그리고 gender는 개별 열 이름에 포함되어 있습니다. new_sp_m1524 열을 예로 들어 보겠습니다. sp는 폐 도말 양성인 유형(a positive lung smear)을 나타내고, m은 남성, 1524는 15~24세 연령 그룹을 나타냅니다.
이 데이터 프레임의 또 다른 문제는 열 이름 서식이 지정되지 않았다는 것입니다. 일부 열에서는 new 뒤에 밑줄이 있지만(new_sp_m3544) 있지만, 그렇지 않은 열도 있습니다(newrel_m2534).
여기에서 이 데이터 프레임을 pivot_longer로 어떻게 정리할 수 있는지 살펴보도록 하겠습니다.
(who_cleaned <- who |>
pivot_longer(
cols = new_sp_m014:newrel_f65,
names_pattern = "new_?([a-z]{2,3})_([a-z])(\\d+)",
names_to = c("type", "sex", "age"),
values_to = "cases") |>
mutate(
age = case_when(
str_length(age) == 2 ~ age,
str_length(age) == 3 ~ str_replace(age, "(^.)", "\\1-"),
str_length(age) == 4 ~ str_replace(age, "(^.{2})", "\\1-"),
TRUE ~ age)
)
)# A tibble: 405,440 × 8
country iso2 iso3 year type sex age cases
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan AF AFG 1980 sp m 0-14 NA
2 Afghanistan AF AFG 1980 sp m 15-24 NA
3 Afghanistan AF AFG 1980 sp m 25-34 NA
4 Afghanistan AF AFG 1980 sp m 35-44 NA
5 Afghanistan AF AFG 1980 sp m 45-54 NA
6 Afghanistan AF AFG 1980 sp m 55-64 NA
7 Afghanistan AF AFG 1980 sp m 65 NA
8 Afghanistan AF AFG 1980 sp f 0-14 NA
9 Afghanistan AF AFG 1980 sp f 15-24 NA
10 Afghanistan AF AFG 1980 sp f 25-34 NA
# ℹ 405,430 more rowspivot_longer부터 시작하겠습니다. 이전 예제와의 주요 차이점은 names_pattern에 대한 정규식이 더 복잡하다는 것입니다. 이 정규식은 세 개의 그룹을 캡처합니다. 각 그룹은 새 열로 변환됩니다.
• 첫 번째 그룹([a-z]{2,3})은 케이스 유형을 나타내는 열로 변환됩니다.
• 두 번째 그룹([a-z])은 gender 열로 변환됩니다.
• 세 번째 그룹(\\d+)은 age로 변환됩니다.
정규표현식에서 밑줄을 선택 사항으로 만들어 new_? 문제를 해결한 방법은 다음과 같습니다.
(who_tidy_first_step <- who |>
pivot_longer(
cols = new_sp_m014:newrel_f65,
names_pattern = "new_?([a-z]{2,3})_([a-z])(\\d+)",
names_to = c("type", "sex", "age"),
values_to = "cases"
))# A tibble: 405,440 × 8
country iso2 iso3 year type sex age cases
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan AF AFG 1980 sp m 014 NA
2 Afghanistan AF AFG 1980 sp m 1524 NA
3 Afghanistan AF AFG 1980 sp m 2534 NA
4 Afghanistan AF AFG 1980 sp m 3544 NA
5 Afghanistan AF AFG 1980 sp m 4554 NA
6 Afghanistan AF AFG 1980 sp m 5564 NA
7 Afghanistan AF AFG 1980 sp m 65 NA
8 Afghanistan AF AFG 1980 sp f 014 NA
9 Afghanistan AF AFG 1980 sp f 1524 NA
10 Afghanistan AF AFG 1980 sp f 2534 NA
# ℹ 405,430 more rows다음으로 age 열을 정리해야 합니다.
014 → 0-14
1524 → 15-24
65 → 65
이 변환은 mutate 및 case_when을 사용하여 수행할 수 있습니다:
(who_tidy_second_step <- who_tidy_first_step |>
mutate(
age = case_when(
str_length(age) == 2 ~ age,
str_length(age) == 3 ~ str_replace(age, "(^.)", "\\1-"),
str_length(age) == 4 ~ str_replace(age, "(^.{2})", "\\1-"),
TRUE ~ age)
)
)# A tibble: 405,440 × 8
country iso2 iso3 year type sex age cases
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan AF AFG 1980 sp m 0-14 NA
2 Afghanistan AF AFG 1980 sp m 15-24 NA
3 Afghanistan AF AFG 1980 sp m 25-34 NA
4 Afghanistan AF AFG 1980 sp m 35-44 NA
5 Afghanistan AF AFG 1980 sp m 45-54 NA
6 Afghanistan AF AFG 1980 sp m 55-64 NA
7 Afghanistan AF AFG 1980 sp m 65 NA
8 Afghanistan AF AFG 1980 sp f 0-14 NA
9 Afghanistan AF AFG 1980 sp f 15-24 NA
10 Afghanistan AF AFG 1980 sp f 25-34 NA
# ℹ 405,430 more rows데이터 프레임의 크기가 상당하다는 것을 알 수 있습니다(행 405,440개, 열 8개). 그러나 대부분의 값은 NA, 결측치(missing values)입니다. 다행히도 values_drop_na 파라미터를 TRUE로 설정하여 이러한 NA를 쉽게 제거할 수 있습니다:
(who_cleaned_small <- who |>
pivot_longer(
cols = new_sp_m014:newrel_f65,
names_pattern = "new_?([a-z]{2,3})_([a-z])(\\d+)",
names_to = c("type", "sex", "age"),
values_to = "cases",
values_drop_na = TRUE) |>
mutate(
age = case_when(
str_length(age) == 2 ~ age,
str_length(age) == 3 ~ str_replace(age, "(^.)", "\\1-"),
str_length(age) == 4 ~ str_replace(age, "(^.{2})", "\\1-"),
TRUE ~ age)
)
)# A tibble: 76,046 × 8
country iso2 iso3 year type sex age cases
<chr> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan AF AFG 1997 sp m 0-14 0
2 Afghanistan AF AFG 1997 sp m 15-24 10
3 Afghanistan AF AFG 1997 sp m 25-34 6
4 Afghanistan AF AFG 1997 sp m 35-44 3
5 Afghanistan AF AFG 1997 sp m 45-54 5
6 Afghanistan AF AFG 1997 sp m 55-64 2
7 Afghanistan AF AFG 1997 sp m 65 0
8 Afghanistan AF AFG 1997 sp f 0-14 5
9 Afghanistan AF AFG 1997 sp f 15-24 38
10 Afghanistan AF AFG 1997 sp f 25-34 36
# ℹ 76,036 more rows이 데이터 프레임의 행의 수는 76,046개에 불과합니다. 81% 감소했습니다. 이제 이 데이터 프레임이 있으므로 시간 경과에 따른 사례 수의 변화를 추적할 수 있습니다:
who_cleaned_small |>
ggplot(aes(x = year, y = cases)) +
stat_summary(
fun = sum,
geom = "line") +
facet_wrap(vars(type))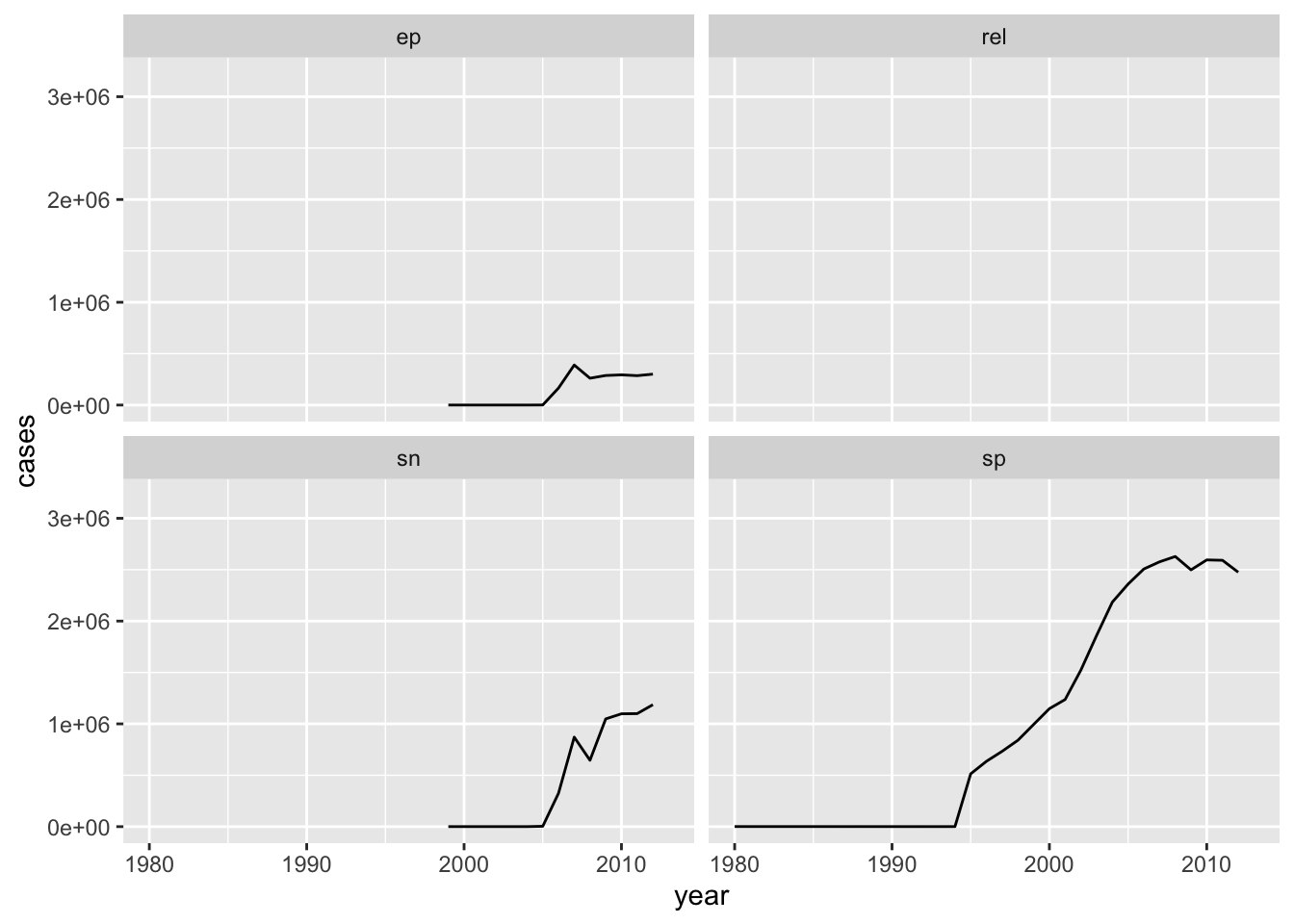
Variables Are Stored in Both Rows and Columns
마지막 예제에서는 변수가 열과 행 모두에 저장되는 경우를 살펴보도록 하겠습니다.
weather_data <- tribble(
~id, ~year, ~month, ~element, ~d1, ~d2, ~d3, ~d4, ~d5, ~d6,
"MX17004", 2010, 1, "tmax", NA, NA, NA, NA, NA, NA,
"MX17004", 2010, 1, "tmin", NA, NA, NA, NA, NA, NA,
"MX17004", 2010, 2, "tmax", NA, 27.3, 24.1, NA, NA, NA,
"MX17004", 2010, 2, "tmin", NA, 14.4, 14.4, NA, NA, NA,
"MX17004", 2010, 3, "tmax", NA, NA, NA, NA, 32.1, NA,
"MX17004", 2010, 3, "tmin", NA, NA, NA, NA, 14.2, NA,
"MX17004", 2010, 4, "tmax", NA, NA, NA, NA, NA, NA,
"MX17004", 2010, 4, "tmin", NA, NA, NA, NA, NA, NA,
"MX17004", 2010, 5, "tmax", NA, NA, NA, NA, NA, NA,
"MX17004", 2010, 5, "tmin", NA, NA, NA, NA, NA, NA) |>
mutate(across(d1:d6, as.numeric))이 데이터 프레임은 멕시코의 기상 관측소에서 수집한 온도 데이터를 보여줍니다(Wickham, 2014, 10f). 매일 최고 기온과 최저기온에 대해 기록하고 있는데, d1부터 d31은 날짜를, 그 외에 year와 month는 달을 나타냅니다. 이 데이터 프레임에서 눈에 띄는 점은 변수인 date가 행과 열에 분산되어 있다는 것입니다. date 변수는 한 열에 있어야 하므로 이 데이터는 깔끔하지 않습니다. 이 문제를 해결하려면 두 가지 작업을 수행해야 합니다.
- 데이터 프레임을 더 길게 만들어야 합니다.
date열을 만들어야 합니다.
weather_data_cleaned <- weather_data |>
pivot_longer(
cols = d1:d6,
names_to = "day",
names_prefix = "d",
values_to = "value",
values_drop_na = TRUE) |>
unite(
col = date,
year, month, day,
sep = "-") |>
mutate(
date = as.Date(date, format = "%Y-%m-%d")) |> print()# A tibble: 6 × 4
id date element value
<chr> <date> <chr> <dbl>
1 MX17004 2010-02-02 tmax 27.3
2 MX17004 2010-02-03 tmax 24.1
3 MX17004 2010-02-02 tmin 14.4
4 MX17004 2010-02-03 tmin 14.4
5 MX17004 2010-03-05 tmax 32.1
6 MX17004 2010-03-05 tmin 14.2pivot_longer의 파라미터는 이미 익숙할 것입니다. 데이터 프레임을 d1~d6 열로 더 길게 만듭니다. 이러한 열 값에서 names_prefix를 사용하여 접두사를 제거하고 NA가 포함된 행을 삭제합니다.
두 번째 단계는 date 열을 만드는 것입니다.
From Long to Wide
많은 경우, 데이터셋을 깔끔하게 만들기 위해서 넓은 형태의 데이터를 긴 형태로 변환하고는 한다고 언급했습니다. 깔끔한 데이터는 데이터 분석 도구에서 처리하도록 최적화되어 있기 때문입니다. 결과적으로, 긴 데이터 프레임은 짧은 데이터 프레임보다 더 많은 값을 가지며 R로 분석하기가 더 쉽습니다.
하지만 때로 데이터 프레임을 긴 형태에서 넓은 형태로 만들고 싶을 때도 있습니다. 예를 들어, 데이터 프레임이 넓을수록 사람이 더 쉽게 읽을 수 있다는 것입니다(엑셀 스프레드시트처럼).
다음 절들에서는 pivot_wider를 사용하는 사례들을 다루어볼 것입니다. 모든 사례에는 몇 가지 공통점이 있습니다. 열의 수를 늘리고 행의 수를 줄임으로써 데이터 프레임을 확장(from long to wide)한다는 것입니다.
How to Use pivot_wider (The Simplest Example)
fish_encounters 데이터 프레임에는 하류에서 이러한 스테이션을 통과하는 물고기의 양을 모니터링하고 기록하는 다양한 스테이션에 대한 정보가 포함되어 있습니다.
fish_encounters# A tibble: 114 × 3
fish station seen
<fct> <fct> <int>
1 4842 Release 1
2 4842 I80_1 1
3 4842 Lisbon 1
4 4842 Rstr 1
5 4842 Base_TD 1
6 4842 BCE 1
7 4842 BCW 1
8 4842 BCE2 1
9 4842 BCW2 1
10 4842 MAE 1
# ℹ 104 more rows이 데이터 프레임에는 세 개의 열이 있습니다. fish는 특정 어종의 식별변수입니다. station은 측정한 스테이션의 이름입니다. seen은 이 스테이션에서 물고기를 보았는지(보았을 경우 1) 또는 보지 못했는지(보지 못했을 경우 NA)를 나타냅니다.
이 데이터 프레임을 넓게 만들어 가독성이 좋은 표로 나타내고 싶다고 합시다. pivot_wider 함수를 사용하고 주요 파라미터에 인수를 제공해주면 됩니다.
id_cols: 이 열은 관측값의 식별변수입니다. 이러한 열 이름은 데이터 프레임에서 변경되지 않습니다. 해당 값은 변환된 데이터 프레임의 행을 형성합니다. 기본적으로names_from및values_from에 지정된 열을 제외한 모든 열은id_cols가 됩니다.names_from: 이 열은 더 넓은 형식으로 변환됩니다. 해당 값은 열로 변환됩니다.names_from에 둘 이상의 열을 지정하는 경우 새로 생성되는 열 이름은 열 값의 조합이 됩니다.values_from: 이 열의 값은names_from을 사용하여 생성된 열의 값으로 넘어갑니다.
(fish_encounters_wide <- fish_encounters |>
pivot_wider(
id_cols = fish, # 이 행은 새로운 데이터셋에서도 그대로 남습니다.
names_from = station, # 이 열의 값은 새로운 변수의 이름으로 넘어갑니다.
values_from = seen # 이 열의 값은 새롭게 만들어진 각 변수의 값으로 넘어갑니다.
)
)# A tibble: 19 × 12
fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE MAW
<fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 4842 1 1 1 1 1 1 1 1 1 1 1
2 4843 1 1 1 1 1 1 1 1 1 1 1
3 4844 1 1 1 1 1 1 1 1 1 1 1
4 4845 1 1 1 1 1 NA NA NA NA NA NA
5 4847 1 1 1 NA NA NA NA NA NA NA NA
6 4848 1 1 1 1 NA NA NA NA NA NA NA
7 4849 1 1 NA NA NA NA NA NA NA NA NA
8 4850 1 1 NA 1 1 1 1 NA NA NA NA
9 4851 1 1 NA NA NA NA NA NA NA NA NA
10 4854 1 1 NA NA NA NA NA NA NA NA NA
11 4855 1 1 1 1 1 NA NA NA NA NA NA
12 4857 1 1 1 1 1 1 1 1 1 NA NA
13 4858 1 1 1 1 1 1 1 1 1 1 1
14 4859 1 1 1 1 1 NA NA NA NA NA NA
15 4861 1 1 1 1 1 1 1 1 1 1 1
16 4862 1 1 1 1 1 1 1 1 1 NA NA
17 4863 1 1 NA NA NA NA NA NA NA NA NA
18 4864 1 1 NA NA NA NA NA NA NA NA NA
19 4865 1 1 1 NA NA NA NA NA NA NA NA조금 더 보기 좋게 만드려면 새롭게 만들어지는 데이터 프레임의 변수 이름 앞에 접두사를 붙이도록 하는 것입니다.
fish_encounters |>
pivot_wider(
id_cols = fish,
names_from = station,
values_from = seen, # 새롭게 만들어진 열에 접두사 붙이기
names_prefix = "station_")# A tibble: 19 × 12
fish station_Release station_I80_1 station_Lisbon station_Rstr
<fct> <int> <int> <int> <int>
1 4842 1 1 1 1
2 4843 1 1 1 1
3 4844 1 1 1 1
4 4845 1 1 1 1
5 4847 1 1 1 NA
6 4848 1 1 1 1
7 4849 1 1 NA NA
8 4850 1 1 NA 1
9 4851 1 1 NA NA
10 4854 1 1 NA NA
11 4855 1 1 1 1
12 4857 1 1 1 1
13 4858 1 1 1 1
14 4859 1 1 1 1
15 4861 1 1 1 1
16 4862 1 1 1 1
17 4863 1 1 NA NA
18 4864 1 1 NA NA
19 4865 1 1 1 NA
# ℹ 7 more variables: station_Base_TD <int>, station_BCE <int>,
# station_BCW <int>, station_BCE2 <int>, station_BCW2 <int>,
# station_MAE <int>, station_MAW <int>또 다른 방법은 names_glue 를 사용하는 것입니다:
fish_encounters |>
pivot_wider(
id_cols = fish,
names_from = station,
values_from = seen,
names_glue = "station_{station}")# A tibble: 19 × 12
fish station_Release station_I80_1 station_Lisbon station_Rstr
<fct> <int> <int> <int> <int>
1 4842 1 1 1 1
2 4843 1 1 1 1
3 4844 1 1 1 1
4 4845 1 1 1 1
5 4847 1 1 1 NA
6 4848 1 1 1 1
7 4849 1 1 NA NA
8 4850 1 1 NA 1
9 4851 1 1 NA NA
10 4854 1 1 NA NA
11 4855 1 1 1 1
12 4857 1 1 1 1
13 4858 1 1 1 1
14 4859 1 1 1 1
15 4861 1 1 1 1
16 4862 1 1 1 1
17 4863 1 1 NA NA
18 4864 1 1 NA NA
19 4865 1 1 1 NA
# ℹ 7 more variables: station_Base_TD <int>, station_BCE <int>,
# station_BCW <int>, station_BCE2 <int>, station_BCW2 <int>,
# station_MAE <int>, station_MAW <int>names_glue는 중괄호가 있는 문자열을 받습니다. 중괄호 안에는 names_from에 해당하는 열을 넣습니다. 중괄호 안에 지정된 변수의 값들이 새로운 변수명으로 가게 되고, 그 변수명들이 names_glue에서 지정한대로 변하게 됩니다.
How to Use pivot_wider to Calculate Ratios/Percentages
미국 주에 거주하는 미국 거주자의 임대료 및 소득에 대한 다음 데이터셋을 얻었다고 합시다:
us_rent_income# A tibble: 104 × 5
GEOID NAME variable estimate moe
<chr> <chr> <chr> <dbl> <dbl>
1 01 Alabama income 24476 136
2 01 Alabama rent 747 3
3 02 Alaska income 32940 508
4 02 Alaska rent 1200 13
5 04 Arizona income 27517 148
6 04 Arizona rent 972 4
7 05 Arkansas income 23789 165
8 05 Arkansas rent 709 5
9 06 California income 29454 109
10 06 California rent 1358 3
# ℹ 94 more rowsvariable 변수에는 income과 rent 의 두 가지 값이 포함됩니다. 실제 예상 임대료와 예상 소득이 estimate 변수에 저장됩니다. income 값은 평균 연간 소득을 나타냅니다. rent 값은 평균 월 소득을 나타냅니다. moe는 이러한 값의 오차 범위를 나타냅니다.
분명히 이 데이터 프레임은 income과 rent 따로 두 열로 있어야 하므로 정돈된 상태가 아닙니다. 여러 주에 거주하는 사람들이 소득의 몇 퍼센트를 임대료로 남겼는지 알아보고 싶다고 할 때, 차선책은 mutate와 case_when 및 lead 를 조합하여 코딩하는 것입니다:
us_rent_income |>
dplyr::select(-moe) |>
mutate( # 연간 소득과 임대료의 중앙값을 표준화
estimate = case_when(
variable == "income" ~ estimate,
variable == "rent" ~ estimate * 12),
lead_estimate = lead(estimate),
rent_percentage = (lead_estimate / estimate) * 100
)# A tibble: 104 × 6
GEOID NAME variable estimate lead_estimate rent_percentage
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 01 Alabama income 24476 8964 36.6
2 01 Alabama rent 8964 32940 367.
3 02 Alaska income 32940 14400 43.7
4 02 Alaska rent 14400 27517 191.
5 04 Arizona income 27517 11664 42.4
6 04 Arizona rent 11664 23789 204.
7 05 Arkansas income 23789 8508 35.8
8 05 Arkansas rent 8508 29454 346.
9 06 California income 29454 16296 55.3
10 06 California rent 16296 32401 199.
# ℹ 94 more rows우리가 찾고 있던 백분율은 rent_percentage 열에서 찾을 수 있습니다. 이 값은 두 가지를 알려줍니다: 사람들이 이전 소득 대비 몇 퍼센트의 임대료를 유지하고 있는지, 그리고 소득 대비 임대료가 몇 퍼센트인지입니다. 하지만 이 데이터셋은 필요한 정보가 추가되었을 뿐, 여전히 “정돈되지 않은” 데이터셋입니다. 이 접근 방식의 또 다른 문제점은 lead와 관련된 가정을 한다는 것입니다. variable 열에서 소득과 임대료 값이 번갈아 나타난다고 가정하기 때문에 lead를 사용할 수 있습니다. 하지만 과연 그런지 전체 데이터를 확인할 수 없고, 만약 관측치 중 일부가 그 규칙을 따르지 않는다면 lead 함수는 잘못된 결과를 산출할 것입니다. 따라서 최선책은 데이터 프레임을 넓게 변환하고 그 데이터셋에서 백분율을 계산하는 것입니다:
us_rent_income |>
pivot_wider(
id_cols = c(GEOID, NAME),
names_from = "variable",
values_from = "estimate") |>
mutate(
rent = rent * 12,
percentage_of_rent = (rent / income) * 100)# A tibble: 52 × 5
GEOID NAME income rent percentage_of_rent
<chr> <chr> <dbl> <dbl> <dbl>
1 01 Alabama 24476 8964 36.6
2 02 Alaska 32940 14400 43.7
3 04 Arizona 27517 11664 42.4
4 05 Arkansas 23789 8508 35.8
5 06 California 29454 16296 55.3
6 08 Colorado 32401 13500 41.7
7 09 Connecticut 35326 13476 38.1
8 10 Delaware 31560 12912 40.9
9 11 District of Columbia 43198 17088 39.6
10 12 Florida 25952 12924 49.8
# ℹ 42 more rows이 접근 방식에는 세 가지 장점이 있습니다.
- 깔끔한 데이터셋을 얻을 수 있습니다.
income과rent의 값이 서로 교차하면서 배치되어 있다는 가정에 의존하지 않습니다.- 인지적으로 덜 까다롭습니다. 각 열에 변수가 포함되어 있으므로 해당 값이 무엇을 나타내는지 직관적으로 확인할 수 있습니다. 한 값을 다른 값으로 나누고 100을 곱하기만 하면 됩니다.
How to Deal with Multiple Variable Names Stored in a Column
다음의 정돈되지 않은 데이터셋을 한 번 봅시다.
(overnight_stays <- read_csv("data/etrm_03h.csv",
locale = locale(encoding= "latin1")))# A tibble: 4 × 153
variable `zona geográfica` categoría `día de la semana` `2011-01` `2011-02`
<chr> <chr> <chr> <chr> <dbl> <dbl>
1 Entradas C.A. de Euskadi Total Total 120035 140090
2 Pernoctaci… C.A. de Euskadi Total Total 212303 246950
3 Grado de o… C.A. de Euskadi Total Total 27.2 33.5
4 Grado de o… C.A. de Euskadi Total Total 35.6 43.6
# ℹ 147 more variables: `2011-03` <dbl>, `2011-04` <dbl>, `2011-05` <dbl>,
# `2011-06` <dbl>, `2011-07` <dbl>, `2011-08` <dbl>, `2011-09` <dbl>,
# `2011-10` <dbl>, `2011-11` <dbl>, `2011-12` <dbl>, `2012-01` <dbl>,
# `2012-02` <dbl>, `2012-03` <dbl>, `2012-04` <dbl>, `2012-05` <dbl>,
# `2012-06` <dbl>, `2012-07` <dbl>, `2012-08` <dbl>, `2012-09` <dbl>,
# `2012-10` <dbl>, `2012-11` <dbl>, `2012-12` <dbl>, `2013-01` <dbl>,
# `2013-02` <dbl>, `2013-03` <dbl>, `2013-04` <dbl>, `2013-05` <dbl>, …이 데이터 프레임에는 바스크 지방의 호텔 시설에 대한 지역별, 카테고리(집계), 요일 및 월별 입장객, 숙박일수 및 점유율에 대한 데이터가 포함되어 있습니다. variable 변수에 문제가 있다는 것을 눈치채셨을 것입니다. variable에는 실제 변수의 이름들이 문자열로 포함되어 있습니다. 이 네 개의 값은 그 자체로 개별 열의 이름으로 나뉘어져야 합니다. 또한 date 열의 값도 여러 열에 분산되어 있습니다:
overnight_stays |>
colnames() |> head(n = 20) [1] "variable" "zona geográfica" "categoría" "día de la semana"
[5] "2011-01" "2011-02" "2011-03" "2011-04"
[9] "2011-05" "2011-06" "2011-07" "2011-08"
[13] "2011-09" "2011-10" "2011-11" "2011-12"
[17] "2012-01" "2012-02" "2012-03" "2012-04" 이 데이터 프레임을 깔끔하게 만들려면 pivot_longer와 pivot_wider를 함께 써야 합니다. 먼저 date 변수를 만들어 데이터 프레임을 길게 변환해 줍시다:
(overnight_stays_longer <- overnight_stays |>
pivot_longer(
cols = matches("\\d{4}-\\d{2,}"),
names_to = "date",
values_to = "value")
)# A tibble: 596 × 6
variable `zona geográfica` categoría `día de la semana` date value
<chr> <chr> <chr> <chr> <chr> <dbl>
1 Entradas C.A. de Euskadi Total Total 2011-01 120035
2 Entradas C.A. de Euskadi Total Total 2011-02 140090
3 Entradas C.A. de Euskadi Total Total 2011-03 177734
4 Entradas C.A. de Euskadi Total Total 2011-04 218319
5 Entradas C.A. de Euskadi Total Total 2011-05 207706
6 Entradas C.A. de Euskadi Total Total 2011-06 225072
7 Entradas C.A. de Euskadi Total Total 2011-07 273814
8 Entradas C.A. de Euskadi Total Total 2011-08 277775
9 Entradas C.A. de Euskadi Total Total 2011-09 239742
10 Entradas C.A. de Euskadi Total Total 2011-10 217931
# ℹ 586 more rows하지만 variable에 저장된 네 개의 변수 이름은 고유한 열이어야 합니다. 따라서 pivot_wider 로 데이터를 다시 넓게 변환해줍니다:
(overnight_stays_tidy <- overnight_stays_longer |>
pivot_wider(
names_from = variable,
values_from = value)
)# A tibble: 149 × 8
`zona geográfica` categoría `día de la semana` date Entradas Pernoctaciones
<chr> <chr> <chr> <chr> <dbl> <dbl>
1 C.A. de Euskadi Total Total 2011-… 120035 212303
2 C.A. de Euskadi Total Total 2011-… 140090 246950
3 C.A. de Euskadi Total Total 2011-… 177734 316541
4 C.A. de Euskadi Total Total 2011-… 218319 403064
5 C.A. de Euskadi Total Total 2011-… 207706 381320
6 C.A. de Euskadi Total Total 2011-… 225072 416376
7 C.A. de Euskadi Total Total 2011-… 273814 534680
8 C.A. de Euskadi Total Total 2011-… 277775 607178
9 C.A. de Euskadi Total Total 2011-… 239742 462017
10 C.A. de Euskadi Total Total 2011-… 217931 410032
# ℹ 139 more rows
# ℹ 2 more variables: `Grado de ocupación por plazas` <dbl>,
# `Grado de ocupación por habitaciones` <dbl>이제 데이터 프레임이 정돈되었으므로 데이터를 제대로 분석할 수 있습니다. 예를 들어, 시간 경과에 따른 숙박 횟수를 그래프로 그릴 수 있습니다:
overnight_stays_tidy |>
mutate(
date = lubridate::ym(date)) |>
ggplot(aes(x = date, y = Pernoctaciones)) +
geom_line()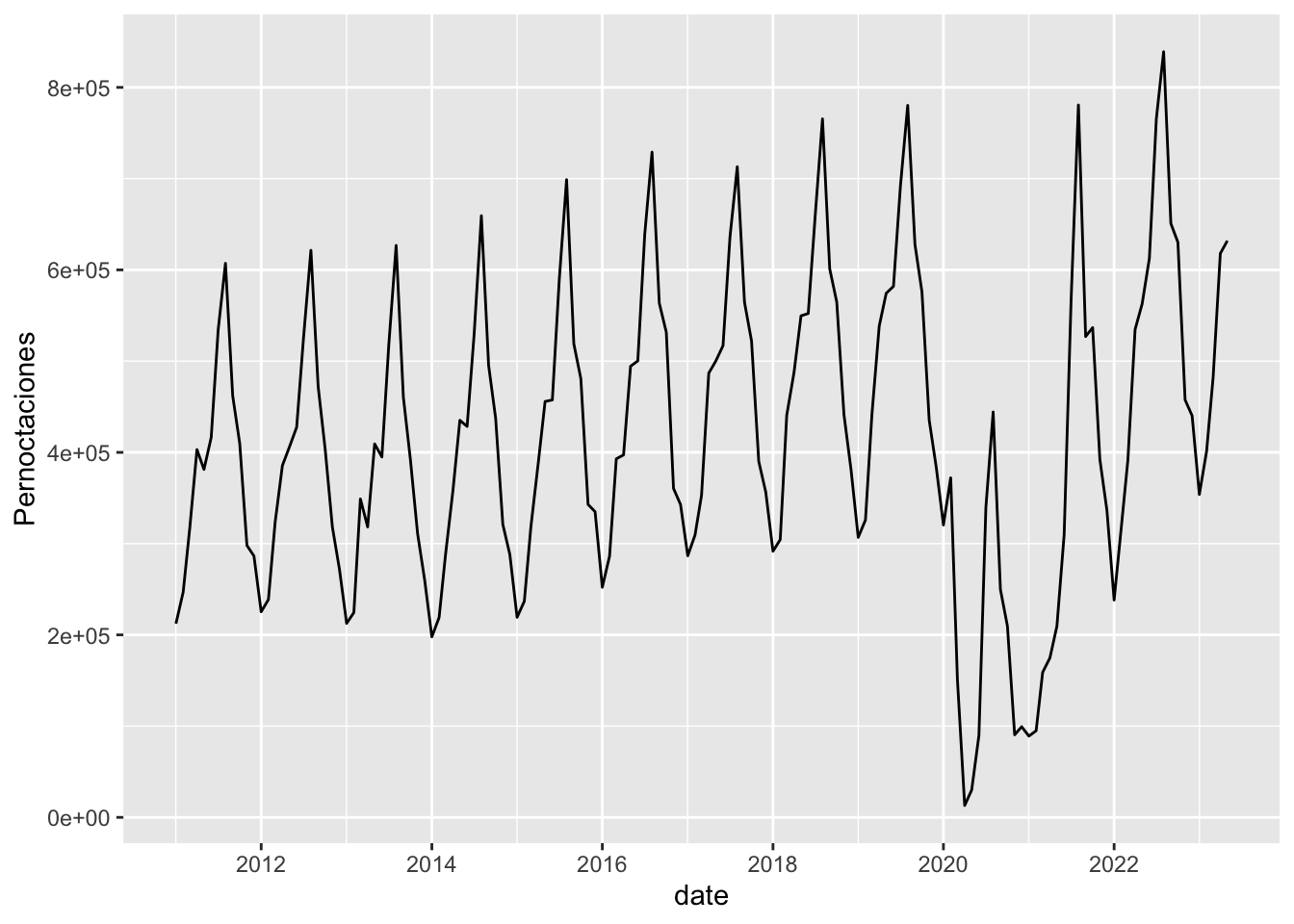
2020년 코로나19 팬데믹의 시작과 각 연도의 계절별 추세를 명확하게 확인할 수 있습니다.