Statistical Inference in Modern Way
Non-Parametric and Parametric Bootstrapping
Statistical inference in modern way: Nonparametric and parametric bootstrapping
Nonparametric Bootstrap: NPBS
통계학에서 표본은 잊을만하면 다시금 튀어나와 생각하게 만듭니다. 사실 영어로 통계학을 의미하는 Statistics에서 Statistic 자체가 모집단의 모수(parameters)와 대비되는 표본에서의 수치를 의미한다고 할 수 있으니까요. 여기서도 익숙지 않은 비모수 부트스트랩이라는 것을 다루기 전에, 표본에 대한 이야기를 조금 하고 넘어갈까 합니다.
우리는 모집단을 관측할 수 없기때문에 모집단의 특성을 파악하기 위해서 모집단의 제반을 고루 보여줄 수 있는 대표성이 있는 표본을 얻기를 원하고, 이때 어떠한 체계적인 편향(bias)가 개입되길 원치 않습니다. 대표성이 있는 표본을 뽑을 수 있는 표집방법 중 하나는 바로 무작위 추출입니다. 따라서 우리는 모집단으로부터 무작위로 추출된 표본을 기대합니다.
한편, 모집단에서 표본을 추출할 때, 뽑고 난 후 그 값이 다음 차례에서도 또 뽑힐 수 있는, 이른바 무작위 복원추출을 하게 된다면 우리는 모집단으로부터 또 다른 표본을 무수히 얻을 수 있을 것입니다. 즉, 여러 색의 공이 뒤섞여 담긴 항아리에서 10개의 공을 꺼낸 것이 우리의 표본이라고 할 때, 꺼낸 공을 다시 원래의 항아리에 집어넣는다면 또 10개의 공을 꺼낼 수 있고, 그렇게 우리는 무수히 많은 10개의 공들의 기록을 얻을 수 있을 것입니다. 비모수 부트스트랩은 이 지점에서 한 가지 질문으로부터 시작됩니다. 만약 우리가 모집단에서 표본을 무작위 복원추출하듯이 꺼낼 수 있다면, 혹시 표본으로부터 또 다른 표본을 무작위 복원추출한다면 어떻게 될까요?
기본 아이디어
우리가 알고싶은 것은 모집단의 특성입니다. 그러나 모집단을 관측하거나 혹은 모집단에 관한 완전한 데이터를 얻을 수 없기 때문에 우리는 모집단의 특성을 잘 반영할 것이라고 기대된 표본을 통해 모집단이 어떠할 것이라는 통계적인 추론을 하게 됩니다. 즉, 추론의 기저에는 표본이 모집단을 잘 대표하고 있다면 표본에서 우리가 관측한 분포, 특성들이 모집단에서도 그러할 것이라고 주장하는 것이 가능하다는 가정이 깔려 있습니다.
이론적으로 우리는 모집단에서 무수히 많은 표본을 추출할 수 있고, 우리는 이렇게 반복된 표본들로 연구를 반복할 수 있습니다. 그러나 모집단으로부터 표본을 추출하는 표집방법의 근본적인 문제로 동일한 모집단에서 뽑은 표본들이라고 할지라도 표본들 간에는 약간의 차이가 존재할 수 있습니다. 선형회귀모델을 한 번 생각해보겠습니다. 우리는 기본적으로 함수적 관계를 통해 어떠한 예측변수들이 종속변수와 관계를 맺을 것이라고 주장합니다. 그러나 약간씩 다른 표본의 자료들을 모델에 투입하는 순간, 당연히 결과로 추정되는 계수값들도 차이가 나게 될 것입니다. 우리는 이렇게 서로 다른 표본들로부터 얻은 통계치, 계수값들을 한 데 모아 그 분포를 그려볼 수 있습니다. 이것이 바로 표집분포입니다.
가우스-마르코프 가정에 따르면, 우리는 이렇게 한 데 그러모은 표본들로부터 나온 계수들의 기대값이 모집단 수준의 모수, 단 하나의 진실된 값과 동일할 것이라고 기대합니다. 그러나 현실적으로 모집단으로부터 수없이 많은 표본들을 얻는 것은 불가능합니다. 예를 들어, 정치학에서 흔히 사용되는 데이터셋인 POLITY IV를 생각해보겠습니다. POLITY IV는 어디까지나 측정가능한 민주주의 정치체제에 대한 제반 속성들을 수치화한 것입니다. 민주주의라고 하는 모집단을 의미하는 것은 아니죠. 어디까지나 표본입니다. 하지만 이 데이터셋 하나를 구축하는 데만도 엄청난 자원과 비용이 소요되었습니다. 네, 현실에서는 이렇게 표본 하나를 제대로 구하는 것도 쉽지 않습니다. 그러므로 사실 우리는 단 하나의 표본에서 나타나는 특성과 통계치를 이용해서 표집분포를 추정하고 있습니다. 이렇게 하기 위해서는 몇 가지 가정들이 충족되어야만 합니다. 예를 들어, 우리가 선형회귀모델을 단 하나의 표본만을 가지고 추정한다고 할 때, 오차항의 독립성과 정규분포가 가정되어야 합니다. 만약 그렇지 않다면 우리는 추정한 계수값이 일관되거나 편향되지 않았다고 하기 어려울 것입니다.
부트스트랩 방법은 표집분포를 추정하는 데 있어서 다른 접근법을 취합니다. 부트스트랩 방법은 대개 복원추출을 통해 모집단으로부터 얻은 \(n\)개의 관측치를 가진 표본으로부터 다시 \(n\)개의 관측치를 가진 표본을 뽑아냅니다. 즉, 표본에서 표본을 뽑습니다. 이렇게 재추출된 표본들은 원래 모집단에서 추출한 표본과 동일한 값을 지닐수도, 아닐수도 있습니다. 왜냐하면 무작위 복원추출을 했기 때문에 어떤 값은 중복되고 어떤 값은 재추출된 표본에는 포함되지 않을수도 있으니까요. 부트스트랩은 이 과정을 반복합니다. 그러고나면 우리는 모집단에서 얻은 단 하나의 표본으로부터 무수히 많은 재추출 표본들을 얻을 수 있게 됩니다.
왜 이런 방법을 사용할까요? 목적은 다르지 않습니다. 우리는 여전히 우리가 알 수 없고, 관측할 수 없는 모집단의 특성을 알고 싶습니다. 그 모집단의 특성을 알기 위해서는 그 특성의 확률분포를 알아야할텐데, 우리는 그 분포가 어떠할 것이라는 확신을 가질 수가 없습니다. 즉, 우리는 사전에 모집단의 확률분포가 어떠할 것이라고 알지 못합니다. 우리는 오직 관측된 표본 통계치들만을 가지고 모수를 추정할 뿐입니다. 한정된 데이터로 인한 불확실성은 우리의 추론을 제약합니다. 또한, 대부분의 통계방법들은 표본의 크기에 따라서 다른 결과들을 내어놓기도 합니다. 표본의 크기 자체가 커질수록 우리는 모수에 대한 더 안정적인 결과를 얻을 수 있을 것이라 기대합니다. 하지만 비용과 시간의 제약으로 인하여 표본 규모를 늘리기란 쉽지 않습니다. 작은 규모의 표본을 가지고 할 수 있는 대안이 없을까? 여기서 부트스트랩 방법이 시작된 것입니다. 부트스트랩 방법은 기본적으로 하나의 표본으로부터 수많은 부트스트랩 표본들을 추출함으로서 앞서의 문제들을 극복하고자 하며, 나아가 하나의 표본 특성을 부트스트랩 표본들로부터 얻은 표집분포로 추론하고, 나아가 그것을 모집단의 모수를 추론하는데까지 사용하고자 합니다.
부트스트랩 방법을 사용하게 되면 우리는 무수히 많은 부스트스랩 표본들을 하나의 표본으로부터 얻게 됩니다. 그리고 부트스트랩 표본들은 하나의 표본으로부터 무작위 복원추출을 한 결과물입니다. 이제 기본적인 논리가 이해가 가실 겁니다. 부트스트랩 표본들 \(\rightarrow\) 표본 \(\rightarrow\) 모집단으로 가는 경로인 것이죠. 부트스트랩 방법은 원 표본(original sample)과 동일한 규모의 표본으로 재추출하고, 부트스트랩 표본들로부터 얻은 표본 통계치의 분포를 표집분포로 사용합니다. 즉, 부트스트랩 방법은 원 표본을 일종의 모집단에 대한 대리(proxy)로 간주하고 무작위 반복 표집을 하는 것이죠. 이렇게 새로 뽑은 부트스트랩 표본은 흡사 원표본에 대한 ’하위 표본’으로 보이지만 정확하게는 ’하위 표본’은 아닙니다. 모집단에 대한 또 다른 표본이죠. 이것이 가능하기 위해서는 하나의 가정이 필요합니다. 바로 원 표본이 모집단을 대표할 수 있는 무작위 반복추출된 표본이어야 합니다. 어디까지나 원 표본이 잘 추출되었다면, 거기서 무작위로 반복추출해서 다시 만든 부트스트랩 표본들은 모집단에서 무작위 반복추출한 결과와 다르지 않을 것이라는 굉장히 강력한 무작위화(randomization)에 대한 믿음이 뒷받침하고 있습니다.
결과적으로 부트스트랩의 재표집 과정은 무수히 많은 표본들을 얻을 수 있고, 부트스트랩 표본들로부터 얻은 표본통계치들은 동일한 모집단에서 추출된 무작위 표본들 간의 차이(variability)를 추정하는 데 사용될 수 있습니다. 이러한 부트스트랩 표집분포를 이용해 우리는 실제 관측치를 이용한 신뢰구간 측정이나 가설검정을 수행할 수 있게 됩니다.
여기서 한 가지 착각하면 안 되는 것은 비모수 부트스트랩 방법이 결코 모집단의 분포에 대한 어떠한 가정을 하고 있는 것은 아니라는 점입니다. 우리는 작은 규모의 표본을 가지고 있을 때, 이 표본이 최소자승법을 사용하기 위한 가정들을 충족시키는지 여부를 알지 못하기 때문에 OLS의 추정 결과를 얻더라도 그것이 과연 BLUE인지를 검정할 방법이 없습니다. 하지만 부트스트랩 방법을 이용하면 이 문제를 시뮬레이션한 표집 분포를 이용해 해결할 수 있습니다. 이것이 소규모 표본을 이용할 때 표본 통계치의 신뢰도1가 낮아 생길 수 있는 문제들을 다룰 수 있는 부트스트랩의 장점입니다.
부트스트랩 방법의 장점은 우리가 작은 표본을 가지고 있거나 모집단의 분포를 모른다고 하더라도 모집단의 특성을 추정할 수 있도록 해준다는 것입니다. 시뮬레이션된 표집분포를 가지고 우리는 계수, 표준오차, 그리고 신뢰구간 등 기존에 추정하던 통계치들을 모두 추정할 수 있습니다. 또한 OLS가 회귀선을 그리는 방법을 부트스트랩 방법과 비교하자면, 부트스트랩 방법은 사전에 모집단의 분포가 어떠할 것이라고 가정을 하지 않기 때문에 모집단의 확률분포가 정규분포가 아니라고 가정하는 다른 여러 추정기법들과도 함께 사용될 수 있습니다.
개인적으로는 부트스트랩 방법은 대개 소규모 표본의 문제로 여러가지 어려움을 겪는 사회과학 분야의 경험연구에 있어서 특히나 유용한 대안이라고 생각합니다. 그러나 분명 부트스트랩 방법에도 한계는 있습니다. 바로 무작위화의 가정이 깨어질 경우입니다. 만약 우리가 가진 단 하나의 표본이 모집단으로부터 무작위 복원추출되었다고 할 근거가 충분하지 못하다면 어떻게 될까요? 원 표본이 편향된 순간, 부트스트랩 표본들도 모집단의 특성을 대표하는 것이 아니라 사실상 원 표본의 체계적 편향을 반영한 표본들이 되고 맙니다.
부트스트랩… 어디다 써먹지?
정리하자면 비모수 부트스트랩을 통해 우리는 표집분포를 얻을 수 있습니다. 그리고 이 표집분포에 대한 함수적 관계를 상정하는 것도 자유롭습니다. 분석적 접근법(analytic approach)에 따르면 모델 \(y = \beta_0 + \beta_1x + \beta2_z + \beta_3xz + \epsilon\)에서 상호작용을 나타내는 편미분 결과 \(\hat{\beta_1} + \hat{\beta_3}z\)의 표준오차, 즉 표본의 차이에 따라 그 상호작용 효과가 다르게 나타날 수 있는 변동성은 \(Var(\hat{\beta_1}) + z^2Var(\hat{\beta_3}) + 2z Cov(\hat{\beta_1}, \hat{\beta_3})\) 으로 나타납니다. 하지만 만약 우리가 \(g = 1, \cdots, G\)개의 부트스트랩 표본들을 추출할 수 있게 된다면, 그 부트스트랩 표본들로부터 얻은 \(\hat{\beta}_1^{(1)} + \hat{\beta}_3^{(1)}z, \cdots, \hat{\beta}_1^{(G)} + \hat{\beta}_3^{(G)}z\)를 가지고 요약통계를 보여주면 됩니다. 훨씬 간단하죠.
행렬 OLS를 통해 우리가 얻을 수 있는 예측값이 \(\hat{\textbf{y}} = \bar{\textbf{X}}\hat{\beta}\)이라는 것을 다시 떠올려보겠습니다. 부트스트랩 표본을 \(g=1,\cdots,G\)개 가졌다고 한다면 이 부트스트랩 표본들로부터 얻은 계수값은 \(K\times1\)의 벡터로 나타낼 수 있습니다: \(\hat{\beta}^{(g)}\). 따라서 하나의 부트스트랩 표본에서 얻어진 예측값은 \(\hat{\textbf{y}}^{(g)} = \bar{\textbf{X}}\hat{\beta}^{(g)}\)라고 할 수 있습니다. 그리고 \(G\)개의 부트스트랩 표본들을 이용해 알고 싶은 예측값에 대한 전체 부트스트랩 분포를 구할 수 있습니다. 간단히 말하면, \(x_1\) 변수에 대한 \(\hat{beta_1}\)은 부트스트랩 표본들 전체를 모델에 집어넣고 나온 \(\hat{\beta}^{(g)}\)의 분포로 나타낼 수 있다는 것입니다.
부트스트랩 표본들로부터 추정된 일련의 계수값들을 \(\hat{\textbf{b}} = (\hat{\beta}^{(1)} \cdots \hat{\beta}^{(G)})\)라고 하겠습니다.
그리고 부트스트랩 표본들에 모델을 적용하여 얻은 일련의 예측값들을 \(\hat{\textbf{Y}} = (\hat{y}^{(1)} \cdots \hat{y}^{(G)})\)라고 해보겠습니다.
\(\hat{\textbf{Y}} = \bar{\textbf{X}}\hat{\textbf{b}}\)는 우리가 관심을 가지는 특정한 \(M\)이라는 예측값 각각에 대한 \(G\)개의 부트스트랩 표본들이라고 할 수 있습니다.
부트스트랩 R로 보기: 비모수 부트스트랩의 추출횟수와 결과
실제 데이터를 가지고 부트스트랩 방법을 적용해보겠습니다. 논리대로라면 부트스트랩 표본의 추출 횟수가 증가할수록, 부트스트랩 표본을 통해 얻은 계수 추정치들은 우리가 표집분포를 이용해 도출한 분석적 접근법의 결과에 근사하게 될 것입니다.
비모수 부트스트랩 표본추출 횟수 변화에 따른 결과의 차이를 보겠습니다. 먼저 100번 부트스트랩을 할 경우입니다. 일단 100번 추출한 결과가 들어갈 빈 행렬을 만듭니다.
QOG <- ezpickr::pick(file =
"http://www.qogdata.pol.gu.se/data/qog_std_ts_jan20.dta")
QOG2 <- QOG |>
dplyr::filter(year==2015) |>
dplyr::select(ccode, p_polity2, wdi_trade,
wdi_gdpcapcon2010) |>
drop_na()
holder100 <- matrix(NA, 100)
model1 <- lm(log2(wdi_gdpcapcon2010) ~
1 + p_polity2 + wdi_trade, data=QOG2)함수를 만듭니다. i는 1부터 100까지를 의미합니다. ind는 전체 관측치(각 행의 번호) 중에서 QOG2와 동일한 표본규모로 표집됩니다. 그리고 sample() 함수는 replace 옵션이 TRUE이기 때문에 복원표집된 결과입니다.
이
ind가 헷갈리실 텐데, 뭐냐면 넘버링입니다. 매번 무작위로 넘버링이 나올거고 이 넘버링에 속하는 관측치들은 개별 부트스트랩 표본을 구성합니다.그 과정이
i번, 즉 1~100까지 반복되어 총 100개의 부트스트랩 표본이 생깁니다.이렇게 새로 부트스트랩 표본으로 모델을 분석해 나온 계수값만을 아까 만든 깡통행렬에 차곡차곡 하나씩 저장합니다.
for(i in 1:100){
ind <- sample(1:nrow(QOG2),
size=nrow(QOG2), replace=T)
mod <- lm(log2(wdi_gdpcapcon2010) ~
1 + p_polity2 + wdi_trade,
data=QOG2[ind,])
holder100[i,] <- coef(mod)[2]
}
head(holder100) [,1]
[1,] 0.09050045
[2,] 0.03295048
[3,] 0.10396144
[4,] 0.07086517
[5,] 0.03056143
[6,] 0.13485427이 다음에는 단순하게 추출 횟수만 바꾸어주면 되겠죠? 빠르게 가겠습니다.
## 1000 Bootstrapping
holder1000 <- matrix(NA, 1000)
for(i in 1:1000){
ind <- sample(1:nrow(QOG2),
size=nrow(QOG2), replace=T)
mod <- lm(log2(wdi_gdpcapcon2010) ~
1 + p_polity2 + wdi_trade,
data=QOG2[ind,])
holder1000[i,] <- coef(mod)[2]
}
## 10000 Bootstrapping
holder10000 <- matrix(NA, 10000)
for(i in 1:10000){
ind <- sample(1:nrow(QOG2),
size=nrow(QOG2), replace=T)
mod <- lm(log2(wdi_gdpcapcon2010) ~
1 + p_polity2 + wdi_trade,
data=QOG2[ind,])
holder10000[i,] <- coef(mod)[2]
}
## 100000 Bootstrapping
holder100000 <- matrix(NA, 100000)
for(i in 1:100000){
ind <- sample(1:nrow(QOG2),
size=nrow(QOG2), replace=T)
mod <- lm(log2(wdi_gdpcapcon2010) ~
1 + p_polity2 + wdi_trade,
data=QOG2[ind,])
holder100000[i,] <- coef(mod)[2]
}이렇게 계산된 각각의 100번, 1,000번, 10,000번, 100,000번의 부트스트래핑 결과로 얻어진 계수값들을 하나의 데이터로 만들어서 비교해보도록 하겠습니다. tidyverse 패키지의 tibble을 이용하여 하나의 데이터로 만들겠습니다. 일단 각각의 부트스트랩한 계수값 결과를 하나의 데이터로 만들어줍니다.
npbs <- bind_rows(
holder100 |>
as_tibble() |> mutate(NPBS = "100") |>
rename(Estimates = V1),
holder1000 |>
as_tibble() |> mutate(NPBS = "1000") |>
rename(Estimates = V1),
holder10000 |>
as_tibble() |> mutate(NPBS = "10000") |>
rename(Estimates = V1),
holder100000 |>
as_tibble() |> mutate(NPBS = "100000") |>
rename(Estimates = V1))각 부트스트랩 횟수별로 평균을 구해주겠습니다. 그리고 비교대상인 OLS의 민주주의 계수값 결과도 추가해주고요.
npbs <- npbs |> group_by(NPBS) |> mutate(
`NPBS Mean` = mean(Estimates, na.rm = T),
`OLS estimates` = coef(summary(model1))[2,1],
`OLS se` = coef(summary(model1))[2,2]
) |> ungroup()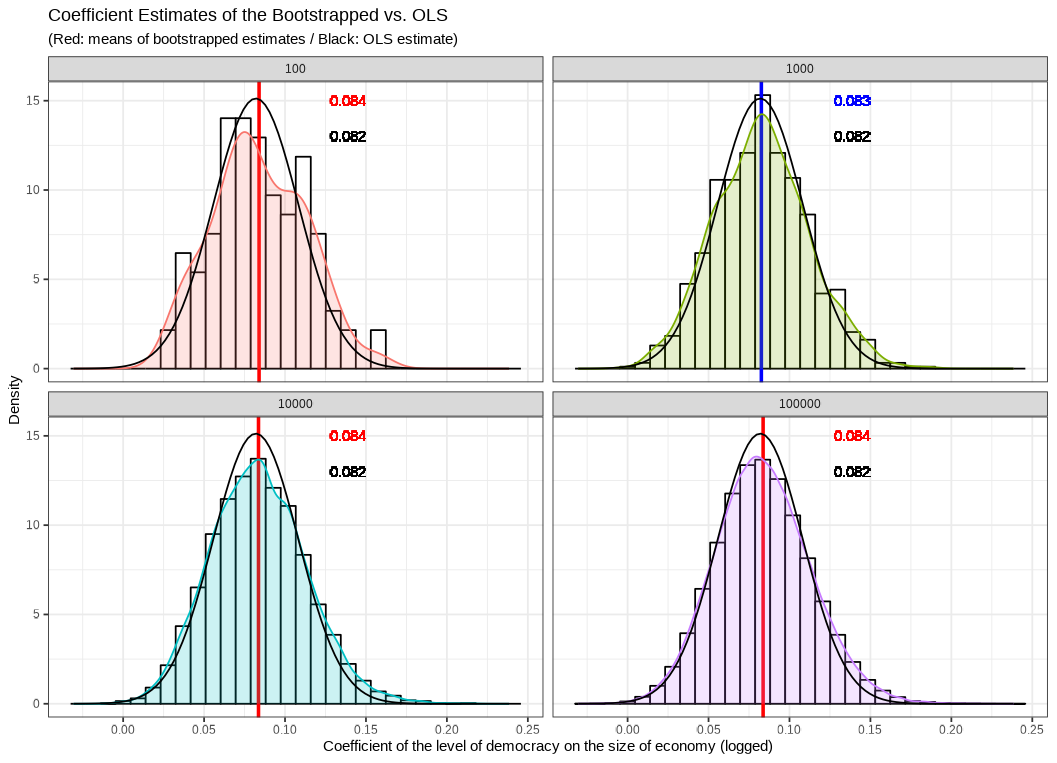
부트스트랩으로 얻은 회귀계수와 OLS로 추정한 회귀계수를 비교해보도록 하겠습니다. 각 패널은 부트스트랩 복원표본추출 횟수를 보여줍니다. 그리고 x-축은 회귀계수 값을, y-축은 밀도입니다. 좌측 상단의 패널은 부트스트랩 패널을 100번 추출했을 때의 결과입니다. 붉은 선이 부트스트랩으로 얻은 회귀계수의 평균이고 소수점 셋째 자리에서 0.084입니다. 그리고 붉은 색으로 표시된 분포와 히스토그램이 부트스트랩으로 얻은 계수 관측치들의 분포를 보여줍니다. 검정색 선으로 표시된 분포는 OLS 분석으로 얻은 회귀계수값을 평균으로 하고 표준오차를 표준편차로 하는 정규분포입니다. 말이 되죠? 왜냐면 OLS의 가우스-마르코프 가정이 충족된다면 OLS의 회귀계수는 BLUE일테니, 그렇게 얻은 회귀계수의 기대값인 평균은 모집단의 모수, \(\beta\)와 같을 것이고 표집분포에서의 표준편차는 표본추출로 인한 표본들 간에 나타날 수 있는 차이를 보여주는 표준오차로 나타나니까요.
일단 부트스트랩 표본추출 100회차를 보면 벌써 평균이 0.002밖에 차이가 안 납니다. 다만 분포 양상은 정규분포라고 하기 조금 힘듭니다. 아무래도 관측치가 100개밖에 없다보니 좀 삐뚤빼뚤합니다. 히스토그램만 봐도 그렇죠.
두 번째로는 부트스트랩을 1,000번 시뮬레이션한 결과입니다. 평균 차이는 뭐 여전히 조금 존재하기는 하지만 분포가 한층 더 정규분포에 비슷해진 것을 확인할 수 있습니다. 마찬가지로 나머지 하단의 두 패널들도 점점 분포 양상이 정규분포 모양으로 수렴하는 것을 확인할 수 있습니다. 즉, 이를 통해서 우리는 부트스트랩 표본 추출 횟수가 증가할수록 부트스트랩 표본들을 이용해 얻은 계수값들의 분포는 OLS 회귀계수의 정규분포에 근사한다는 것을 알 수 있습니다. 시뮬레이션이 분석적 접근법의 대안일 수 있다는 것이죠.
부트스트랩 R로 보기(2): 신뢰구간과 점추정치
챕터 4에서 “변수에 대한 심화”라는 항에서 Gelman (2008)2에 따라 변수를 표준화하되 \(b=1sd(x)\)가 아니라 \(b=2sd(x)\)로 표준화를 해준 적이 있습니다. 결과적으로 \(b=2sd(x)\)로 표준화했을 때, 표준화 이전 계수의 경향성과 표준화한 이후의 계수의 경향성이 비슷한 양상을 보인다는 것을 확인했습니다. 어차피 표준화의 결과로 실질적 변수의 효과가 다르게 나타나는 것은 아니니만큼 \(b=2sd(x)\) 표준화가 직관적인 이해까지 도울 수 있다는 제언을 한 적이 있습니다. 이번에는 당시의 분석을 비모수 부트스트랩을 이용해서 재현해보도록 하겠습니다.
기억을 되살려보면 \(y_i = \delta_0 + \delta_1x_i, \:\:i\leq n\)이라고 할 때, \(a = \frac{1}{n}\sum_i x_i\)이고 \(b=2sd(x)\)인 \(y_i = \lambda_0 + \lambda_1\frac{x_i-a}{b}\)를 추정하는 것이었습니다. \(x\)에 맞추어 재구성하면 결국 아래와 같은 모델이라는 것을 알 수 있죠.
\[ y = \lambda_0 + \lambda_1(\frac{x_i - \bar{x}}{2\times\sigma_x}) \]
이번에는 QoG 데이터셋의 1인당 GDP와 민주주의 수준을 이용해 분석해보겠습니다. 데이터를 고려해보면 제 모델은 아래와 같습니다.
\[ \text{경제규모}_i = \lambda_0 + \lambda_1\frac{(\text{민주주의 수준})-(\text{민주주의 수준의 평균})}{\text{민주주의 수준의 표준편차}\times2} \]
# Model with raw variable
model1 <- lm(log2(wdi_gdpcapcon2010) ~
1 + p_polity2 + wdi_trade, data=QOG2)
# 2sd Standardization
QOG2 <- QOG2 |>
mutate(
std.polity = p_polity2 - mean(p_polity2)/2*sd(p_polity2))
# New modeling
model.sd <- lm(log2(wdi_gdpcapcon2010) ~ std.polity, data=QOG2)
# Results
model.sd |> broom::tidy() |>
mutate_if(is.numeric, round, 3) |> knitr::kable()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 13.079 | 0.302 | 43.279 | 0.000 |
| std.polity | 0.087 | 0.028 | 3.107 | 0.002 |
# Model with raw variable (before 2sd Std.) for comparison
model2 <- lm(log2(wdi_gdpcapcon2010) ~ p_polity2, data=QOG2)
model2 |> broom::tidy() |>
mutate_if(is.numeric, round, 3) |> knitr::kable()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 11.919 | 0.210 | 56.820 | 0.000 |
| p_polity2 | 0.087 | 0.028 | 3.107 | 0.002 |
표준화를 했기 때문에 이제 예측변수는 측정단위에 따라 결과가 좌우되지는 않습니다. 즉, 변수가 여러개 있다면 표준화한 변수들의 효과들 간에는 상대적 비교가 가능합니다. 예를 들어, \(x_1\)이 \(x_2\)보다 \(y\)에 미치는 효과가 상대적으로 크다, 작다 등으로 해석이 가능하다는 얘기지요. 그것이 실질적인 효과와 직결되느냐는 조금 다른 문제입니다만 여하튼 표준화는 서로 분석단위가 \(kg\) 대 \(ml\) 등으로 상이한 변수들 간의 효과를 비교할 수 있도록 스케일링해주는 것입니다.
물론 여기서는 단 하나의 예측변수만을 사용하기 때문에 결과는 표준화된 예측변수—민주주의의 수준과 로그값을 취한 종속변수의 관계만을 보여줄 것입니다. 이 분석을 위하여 4,000번의 부트스트랩 복원표본추출을 해보도록 하겠습니다.
holder.std <- matrix(NA, 4000)
for(i in 1:4000){
ind <- sample(1:nrow(QOG2), size=nrow(QOG2), replace=T)
mod <- lm(log2(wdi_gdpcapcon2010) ~ std.polity, data=QOG2[ind,])
holder.std[i,] <- coef(mod)[2]
}어떤 방식으로 데이터를 구성했는지 조금 직관적으로 이해할 수 있게 단순하고 늘어지는 코드를 써보았습니다. 먼저 부트스트랩 결과입니다.
std.data1 <- data.frame(ID="Bootstrapped",
Low=quantile(holder.std, 0.025),
M=mean(holder.std),
High=quantile(holder.std, 0.975))부트스트랩은 이미 우리가 4000개의 관측치를 가지고 있기 때문에 이 관측치에서 왼쪽꼬리 2.5백분위와 우측꼬리 2.5백분위에 해당하는 값이 95% 신뢰구간의 기준값이 됩니다.
# OLS results
std.data2 <- data.frame(ID="OLS",
Low=coef(summary(model.sd))[2,1] -
1.96*coef(summary(model.sd))[2,2],
M=coef(summary(model.sd))[2,1],
High=coef(summary(model.sd))[2,1] +
1.96*coef(summary(model.sd))[2,2])
std.data <- rbind(std.data1, std.data2)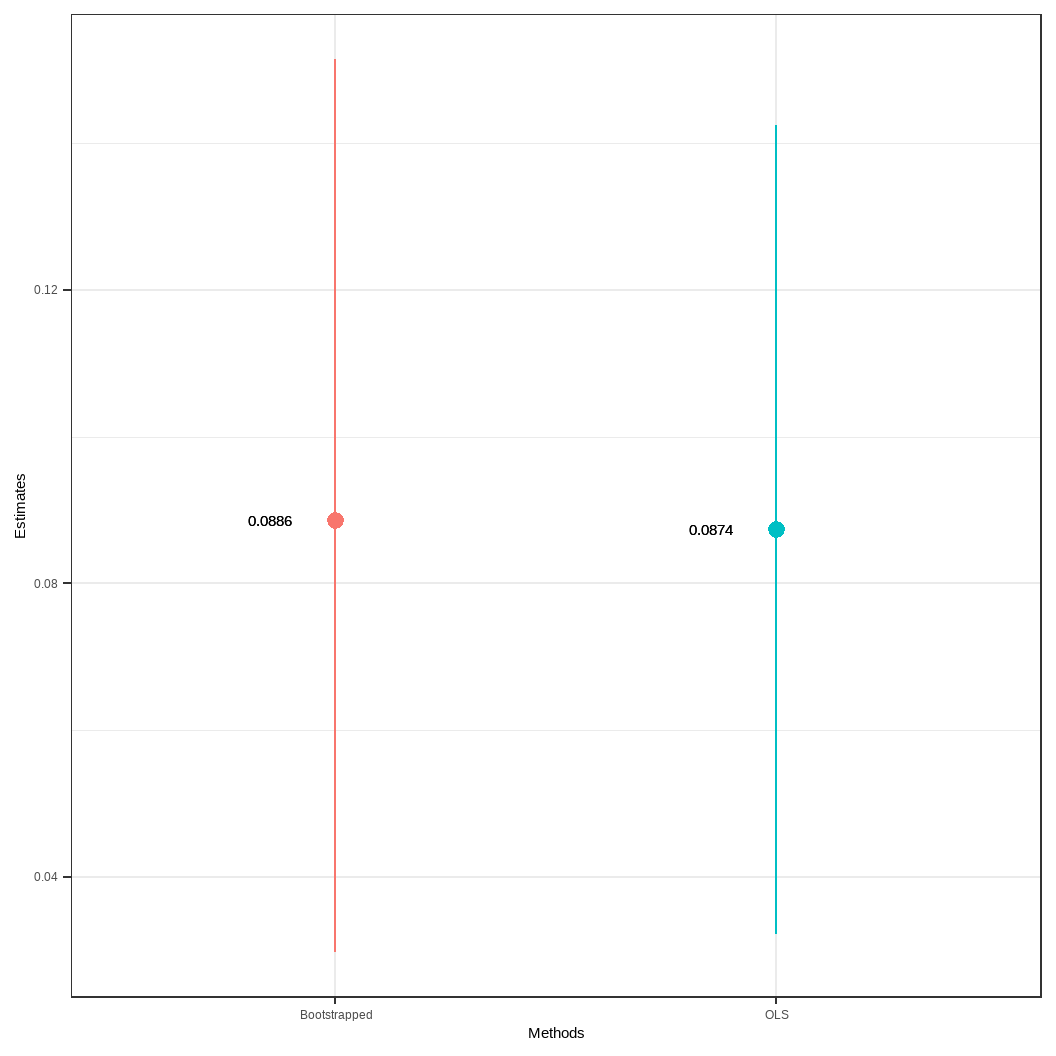
자, 어떤가요? 부트스트랩 표본추출로 구한 계수 추정치와 OLS 추정치의 95% 신뢰구간 결과입니다. 보시다시피 부트스트랩 결과가 조금 큰 계수값과 넓은 신뢰구간을 가지고 있지만 두 계수 추정치는 매우 근사하고 이 차이는 실질적인 분석을 수행하는 데 있어서 무시할만합니다. 뭐 이렇게 말하면 조금 위험할수도 있지만요. 하지만 부트스트랩의 평균과 표준편차가 OLS의 분석적 결과인 계수 추정치와 표준오차 계산을 통한 신뢰구간보다 조금 과대추정되었더라도 부트스트랩 결과는 그 나름의 장점이 있습니다. 우리는 실질적으로 계수값들의 관측치를 통해 분포를 가지고 있기 때문에 그 분포를 이용해 원하는 값을 보여줄 수 있기 때문입니다. 게다가 부트스트래핑은 표본 규모가 작더라도 시도할 수 있기 때문에 어떤 부분에서는 OLS에 대해 상대적 이점이 있다고도 할 수 있습니다.
Parametric Bootstrapping: We came, we saw, we CLARIFYed
이 섹션에서는 비모수 부트스트랩을 넘어 이제 모수적 부트스트랩(parametric bootstrap), 흔히 정치학에서는 AJPS 2000년의 Gary King과 Michael Tomz, 그리고 Jason Wittenberg 논문으로 유명한 Clarify에 대해 살펴보도록 하겠습니다.
여기까지 오셨다면 이제는 신뢰구간이란 무엇인지, 그리고 표집분포란 대체 무엇인지에 대해서 더 명확하게 이해하셨을 것이라 기대합니다. 그리고 앞선 챕터 7을 통해 비모수 부트스트랩까지 다루었기 때문에 굉장히 기초적이지만 이른바 시뮬레이션에 대한 내용도 접해보았습니다.
간단히 복습하는 의미에서 비모수 부트스트랩에 대해 이야기해 보겠습니다. 우리는 모집단에 대해서 알고 싶어합니다. 사회과학, 특히 정치학을 예로 든다면 우리는 민주화에 대해 연구할 때, 민주화의 모집단—모든 민주화에 대해 보편적으로 찾아볼 수 있는 특성을 알기를 원합니다. 하지만 과거의 모든 사례들을 우리가 다 안다고 할 수 없고, 앞으로 일어날 모든 일들을 관측할 수는 없습니다. Karl Popper가 말한 검은 백조의 비유(김웅진 2011: 53)처럼, 우리는 모집단을 결코 완벽하게 관측할 수 없습니다. 우리가 여태까지 관측한 모든 백조가 희다고 한들, 세상 어딘가 검은 백조가 존재할 확률이 0이 아닌 것이죠. 따라서 모집단은 관측불가능하고, 얻을 수 없는 것이라고 해도 무방합니다.
하지만 우리는 모집단에 대해 알고 싶습니다. 그래서 통계학에서는 표본을 이용해 모집단에 대해 추론하는 방법을 사용합니다. 우리의 표본이 모집단으로부터 무작위로 추출되어 수집되었을 때, 우리는 표본이 모집단을 대표할 것이라고 기대합니다. 이때 무작위란 모집단으로부터 추출될 확률이 모든 관측치에 걸쳐 동일하다는 것을 의미합니다.
비모수 부트스트랩은 여기서 한 발 더 나아가 만약 우리가 모집단으로부터 무작위로 반복추출하여 구성한 표본을 가지고 있다고 할 때, 그 표본으로부터 또 무작위 반복추출하여 부트스트랩 표본들을 구성할 경우, 그 부트스트랩 표본들이 모집단으로부터 무작위 추출된 것과 다르지 않다는 논리에 바탕을 두고 있습니다. 즉, 비모수 부트스트랩은 무작위화(randomization)에 대한 강력한 믿음을 전제하고 있습니다.
비모수 부트스트랩을 통해 얻는 것 (1)
비모수 부트스트랩을 통해 우리는 표집분포에 대해 어떠한 함수이든 상관없이 그 전체의 분포에 대한 추정값을 얻을 수 있습니다. 예를 들어, \(y = \beta_0 + \beta_1x + \beta-2z + \beta3_xz\)라는 상호작용항을 포함한 회귀모델이 있다고 합시다. 이때, 우리가 관심있는 것은 과연 변수들 간 상호작용이 존재하는지를 보여주는 \(\frac{\partial y}{\partial x} = \beta_1 + \beta_3z\)일 것입니다.
비모수 부트스트랩을 이용하면, 일단 우리는 \(g = 1, \cdots, G\)번의 재표집 과정을 거쳐 얻어진 부트스트랩 표본들을 이용해 동일한 모델을 적용해 표본 별 추정값을 재추정하면 그만입니다. 따라서 우리는 1번 부트스트랩 표본부터 \(G\)번 부트스트랩 표본에 이르기까지 \(\hat{\beta_1}^{(1)} + \hat{\beta_3}^{(1)}z, \cdots, \hat{\beta_1}^{(G)} + \hat{\beta_3}^{(G)}z\)라는 결과들을 얻게 됩니다. 남은 것은 이렇게 얻은 부트스트랩 표본들의 추정치 벡터를 평균, 표준편차, 히스토그램, 신뢰구간 등의 다양한 방법을 통해 요약하여 보여주는 일입니다.
비모수 부트스트랩을 통해 얻는 것 (2)
이번에는 OLS를 생각해보겠습니다. \(\bar{\textbf{X}}\)가 \(M\)개의 행과 \(K\)개의 열을 가지고 있는 행렬이라고 하겠습니다. 데이터셋을 생각해보시면 편합니다. 이 행렬은 \(M\)개의 ID와 \(K\)개의 변수를 가진 데이터셋이라는 의미입니다. 우리는 이 행렬을 가지고 개별 관측치들 각각에 대해서 예측변수들의 수준이 변화할 때, 종속변수의 값이 어떻게 변화하는지를 확인할 수 있습니다.
\(g = 1, \cdots, G\)의 부트스트랩 표본들을 데이터로부터 얻었다고 하겠습니다. 그 부트스트랩 표본들을 가지고 원래의 데이터와 동일한 OLS 모델을 적용할 경우, 우리는 \(K\times 1\)에 해당하는 벡터: \(\hat{\beta}^{(G)}\)를 얻게 됩니다. 하나의 부트스트랩 표본에 우리는 \(M\)개의 예측값을 얻을 수 있습니다: \(\hat{\textbf{y}}^{(g)} = \bar{\textbf{X}}\hat{\beta}^{(g)}\).
데이터로부터 얻은 \(G\)개의 부트스트랩 표본들을 가지고 우리는 관심을 가지고 있는 예측값 각각에 대한 전체 부트스트랩 분포를 구할 수 있습니다.
부트스트랩 표본들로부터 얻은 계수값들을 \(\hat{\textbf{b}} = (\hat{\beta}^{(1)} \cdots\hat{\beta}^{(G)})\)라고 하겠습니다.
마찬가지로 부트스트랩 표본들로부터 얻은 예측값을 \(\hat{\textbf{Y}} = \hat{\textbf{y}}^{(1)}\cdots\hat{\textbf{y}}^{(G)}\)라고 하겠습니다.
이때, \(\hat{\textbf{Y}} = \bar{\textbf{X}}\hat{\textbf{b}}\)는 우리가 알고 싶어하는 \(M\)이라는 예측값 각각에 대한 \(G\)개의 부트스트랩 표본들의 결과를 보여줍니다. 따라서 \(\hat{\textbf{Y}}\)는 \(M\times G\)의 행렬로 나타납니다.
비모수 부트스트랩을 통해 얻는 것 (3)
매번 부트스트랩 표본 추출을 해서 원하는 예측값을 저장하기보다, 그냥 \(g \leq G\)일 때, \(\hat{\beta}^{(g)}\)를 저장하면 됩니다. 간단하게 말하면, 부트스트랩으로 얻은 계수 추정치들만 가지고 있으면 된다는 얘기입니다. 그러면 그 계수 추정치, \(\hat{\textbf{b}}\)를 우리가 원하는 부트스트랩 표본의 행렬(\(K\times G\))에 대입하여 계산하기만 하면 됩니다. 새롭게 다시 부트스트랩 과정을 반복할 필요 없이 이미 얻은 이 계수의 벡터를 이용해 자유롭게 예측값의 변화를 추적할 수 있습니다. 예를 들어, \(x_1\)과 \(x_2\)가 각각 성별과 소득이라고 할 때, 여성과 최저소득자로 고정해서 예측값을 구하고 싶다면? 다른 변수들은 부트스트랩 표본에서 그대로 놔두고 부트스트랩 표본에서 해당 두 열의 값만 각각 여성과 초저소득자에 해당하는 값으로 고정한 뒤, 이미 구한 계수의 행렬과 계산해주면 됩니다.
모수적 부트스트랩
자, 비모수 부트스트랩을 복습해보았습니다. 이제부터는 챕터 8의 주제인 모수적 부트스트랩에 대해 살펴보겠습니다. 다시 표집분포에 대한 이야기로 돌아가 보겠습니다. OLS에서 표집분포란 우리가 얻을 수 있는 모든 가능한 추정치 \(\hat{\beta}\)가 \((\beta, \hat{\sigma}^2(X'X)^{-1})\)을 따르는 정규분포를 가진다는 것을 의미합니다. OLS가 BLUE를 산출할 수 있는 가정들을 만족시킨다면 말이죠. 그런데 문제는 우리가 \(\beta\)를 모른다는 것입니다. \(\beta\)는 모집단의 모수, 우리가 진정 알고자 하는 모집단에서의 관계를 보여주는 것이니까요.
King, Tomz, 그리고 Wittenberg (2000, 이하 King et al. (2000))는 왜 우리가 OLS를 통해 추정해낸 “최고의 선형관계를 보여주는 편향되지 않은 효율적인 추정값”(Best Linear Unbiased Estimator)인 \(\hat{\beta}\)를 사용할 것을 제안합니다. King et al. (2000)에 따르면, 시뮬레이션을 통해 구할 수 있는 모든 계수값은 OLS 계수 추정치를 평균으로 하고 표준오차에 따라 정규분포를 이룰 것이라고 기대할 수 있습니다: \(\tilde{\beta} ~ N(\hat{\beta}, \hat{\sigma}^2(X'X)^{-1})\). 만약 이같은 관계가 성립한다면 우리는 이 정규분포로부터 원하는 값을 자의적으로 선택해서 보여줄 수 있고, \(\tilde{\beta}\)에 대해 어떤 함수적 관계에 상관없이 계산을 할 수 있게 됩니다.
평균과 불확실성을 추정하기
실제 모델을 통해서 한 번 생각해보도록 하겠습니다. 이 모델은 임금수준과 교육수준, 그리고 그 두 변수의 상호작용을 통해 범죄율을 설명할 수 있다는 내용을 담고 있습니다. 정확히는 임금수준이 범죄율에 미치는 효과가 교육수준에 따라 조건적으로 나타날 것이라고 기대한다고 합시다.
\[ \text{범죄율} = \beta_0 + \beta_1\text{임금수준} + \beta_2{교육수준} + \beta_3(임금수\times교육수준) \]
여기서 우리가 관심있는 것은 바로 관찰된 교육 수준의 값이 평균일 때, 임금 수준의 변화에 따른 기대값이라고 할 수 있습니다.
모든 교육수준 관측치에 대해 임금 수준을 고임금(\(\overline{\text{임금}}\))과 저임금(\(\underline{\text{임금}}\))의 저임금으로 벡터화해보겠습니다.
\(g = 1, \cdots. G\)라고 할 때, 다음과 같이 단계대로 진행합니다.
\(\tilde{\beta}^{(g)} ~ N(\hat{\beta}, \hat{\sigma}^2(X'X)^{-1})\)의 분포를 따르는 \(\tilde{\beta}^{(g)}\)를 추출합니다.
교육수준 변수로부터 \(PE^{(g)}\)를 무작위로 추출합니다.
\(\mu \overline{\text{임금}}^{(g)} = \tilde{\beta_0}^{(g)} + \tilde{\beta_1}^{(g)}\overline{\text{임금}} + \tilde{\beta_2}^{(g)}\text{교육수준}^{(g)} + \tilde{\beta_3}^{(g)}(\overline{\text{임금}}\times\text{교육수준}^{(g)})\)을 계산합니다.
\(\mu \underline{\text{임금}}^{(g)} = \tilde{\beta_0}^{(g)} + \tilde{\beta_1}^{(g)}\underline{\text{임금}} + \tilde{\beta_2}^{(g)}\text{교육수준}^{(g)} + \tilde{\beta_3}^{(g)}(\underline{\text{임금}}\times\text{교육수준}^{(g)})\)을 계산합니다.
\(\mu \overline{\text{임금}}^{(g)}\)과 \(\mu \underline{\text{임금}}^{(g)}\) 값을 저장해줍니다.
자, 그러면 이제 두 개의 벡터, \(\mu \overline{\text{임금}}^{(g)}\)과 \(\mu \underline{\text{임금}}^{(g)}\)를 가지게 되었습니다. 이 두 벡터를 요약해서 보여주기만 하면 됩니다. 그러면 우리는 임금이 매우 낮을 때와 임금이 매우 높을 때의 범죄율의 차이를 분포를 통해 직관적으로 확인할 수 있습니다. 이 방법이 효율적인 이유는 위의 4번과 5번에서처럼 \(\tilde{\beta}\)의 \(G\)개의 추출 결과를 가지고 그냥 \(\tilde{\textbf{b}}\)의 행렬과 결합한 뒤 계산만 해주면 되기 때문입니다. 아니면 그냥 바로 구한 \(\tilde{\beta}\) 행렬을 요약해서 보여줘도 되구요.
King et al. (2000)
이 파트에서는 King et al. (2000)의 주장과 제안을 간단하게 정리 및 소개하도록 하겠습니다. 나아가 그들이 (1) 왜 이런 논문을 썼는지, (2) 예측값(predicted values)와 기대값(expected values)의 차이점이 무엇인지, 그리고 1차 차분(first difference)이란 무엇인지, (3) 베이지안 접근법에 대해서 King et al. (2000)이 무어라 말하고 있는지 등에 대해 살펴보겠습니다.
Title: Making the Most of Statistical Analyses: Improving Interpretation and Presentation
이 논문의 제목은 우리가 통계 분석을 통해 얻을 수 있는 결과들의 특성에 대해 좀 더 숙고할 필요가 있다는 King et al. (2000)의 제안을 드러낸다고 할 수 있습니다. 이들은 연구자들이 단지 복잡한 통계분석의 결과를 날것 그대로 보고하지만 말고, 그것의 의미를 제대로 전달할 수 있는 방식으로 보고할 책임이 있다고 주장하고 있습니다. King et al. (2000)에 따르면, 사회과학자들은 통계분석 결과로부터 “가용한 정보의 모든 장점을 거의 취하지 못하고” 있습니다(King et al. 2000: 347). 달리 말하면, 당시 King et al. (2000)이 정치학 분야의 통계방법을 이용한 경험연구들을 살펴보았을 때, 통계 결과를 보여주고 해석하는 방식이 실질적으로 그 결과를 이해하는 데 충분한 정보를 제공하지 못하고 있었다는 것을 의미합니다. 물론 지금은 이 논문이 작성된지 20년이 흘렀고, King et al. (2000) 이후로도 많은 발전과 변화가 있었습니다.
King et al. (2000)은 독자가 통계학적 훈련을 받지 않은 이라고 할지라도 연구자들은 그들이 읽을 수 있고, 이해할 수 있는 방식으로 통계 결과를 제시할 책임이 있다고 강조합니다. 또한 통계적 유의성이 실질적 유의성과 같은 것일고 할 수는 없기 때문에 우리는 연구 결과로 나타난 통계 결과의 실질적 의미가 무엇인지에 대해 통계적 바탕을 가지지 못한 다른 사회과학자 또는 논문을 읽을 일반 독자들과 공유하는 방법을 숙고해야 한다는 것입니다.
이들은 또 통계 방법이 가지는 두 가지 불확실성에 대해 인정해야만 한다고 언급하고 있습니다. 바로 추정결과의 불확실성(estimation uncertainty)과 본연적 불확실성(fundamental uncertainty)입니다. 이 두 불확실성으로 인해 통계적 결과는 가능한 한 많은 정보를 제공해야만 합니다. 단지 효과의 규모, 방향, 그리고 유의성만 보여줄 것이 아니라 우리가 추정해낸 이 효과가 얼마나 불확실한지 역시도 보여주어야 한다는 것입니다. 이를 위해서 King et al. (2000: 350)은 우리가 관심을 가지고 있는 예측값, 기대값, 그리고 1차 차분값이라는 점 추정치에 대해 더 많은 정보를 제공할 수 있을 것으로 기대하는 시뮬레이션에 기반한 접근법을 제안하고 있습니다.
King et al. (2000)이 말하는 예측값은 시뮬레이션 결과로 얻은 예측값을 의미합니다. 통계적 시뮬레이션은 표본 추출 횟수에 따라 수많은 시뮬레이션 표본을 산출할 수 있습니다. 이는 우리가 가지고 있는 통계 모델을 가지고 수없이 시뮬레이션을 돌려 시뮬레이션 결과값들을 가질 수 있다는 것을 의미합니다. 따라서 예측값은 이 시뮬레이션 결과로 가지게 된 벡터들로 계산된 결과입니다. 만약 우리가 예측값을 계산한다고 하면, 시뮬레이션으로 얻은 계수 값에 각 변수에서 하나의 관측치씩을 대입하여 하나의 결과값을 얻게 됩니다. 이것이 바로 예측값입니다. \(y_1 = \beta_0 + \beta_1\times(x_1=1) + \beta_2\times(x_2=3) + \beta_3\times\{(x_1=1)\times(x_2=3)\}\)에서 결과로 나타난 이 \(y_1\)가 각각의 변수에 특정 값들을 대입했을 때, 우리가 얻을 수 있는 예측값입니다.
한편 기대값은 예측값의 변동성을 평균화한, 결과값의 평균값이라고 할 수 있습니다. 따라서 우리는 기대값이 예측값의 변동성의 평균을 취하기 때문에, 예측값이 기대값보다 더 큰 분산을 가질 것이라고 생각할 수 있습니다.
그리고 두 기대값 사이의 차이를 우리는 1차 차분값이라고 합니다. 연구자들은 예측변수들의 설정을 다르게 함으로써 서로 다른 두 개의 기대값을 얻는 알고리즘을 사용합니다(King et al. 2000: 351). 어려울 것은 없습니다. 이 전 파트에서 다른 변수인 교육수준은 똑같이 넣고 임금 수준만 고임금, 저임금으로 나누어서 결과의 변화를 살펴보았던 것이 바로 이런 설정입니다. 1차 차분값은 다른 변수들이 통제되었을 때, 우리가 관심을 가지고 있는 주요 변수의 변화가 결과에 미치는 효과를 보여준다고 할 수 있습니다. 따라서 우리는 이 알고리즘을 반복하면 1차 차분값의 분포를 얻을 수 있습니다. 이 분포를 이용해 우리는 1차 차분값에 대한 추정값과 표준오차를 구할 수 있게 됩니다. 모수적 부트스트랩에서 수많은 부트스트랩 표본들을 이용해 각각의 1차차분값들을 모아 분포를 보여주는 것과 같은 논리입니다.
King et al. (2000)은 베이지안 접근법에 대해서도 하나의 대안적 접근법으로 평가하고 있습니다. 이들은 베이지안 접근법이 중심극한정리나 정규성 가정과 같은 제약에서 상대적으로 자유롭다는 점에서 더 설명력 있는 결과를 제시할 수 있다고 제안합니다. 하지만 King et al. (2000)이 논문을 작성하던 시점에서는 베이지안 접근법을 기존의 통계적 기법들에 적용하기 어려웠기 때문에, 이들은 상대적으로 용이한 시뮬레이션 기반의 접근법을 사용할 것을 제안하고 있습니다.
2020년 7월 현재, 이 논문은 구글 스칼라에서 약 4,100여 명이 넘는 학자들에 의해 인용되고 있습니다. 물론 인용하는 이들이 모두 King et al. (2000)의 주장과 제언을 수용하는 이들ㅇ은 아닐 것입니다만, 적어도 이들의 주장이 한 번쯤 연구문제를 적실하게 풀어나가는 방법을 고민할 때, 되새겨볼만한 의미를 가진 논문이라는 것을 시사한다고 생각합니다.
Practice the King et al. (2000)!
머리 아픈 논문을 살펴보았으니, 이제 데이터를 이용해서 모델을 만들고 King et al. (2000)의 제안에 따라 그들의 논문에 있는 Figure 1과 같은 방식으로 결과를 재현해보도록 하겠습니다. 두 가지 그래프를 그려야 합니다. 이를 위해서 일단 추정해야 할 모델은 일반적인 형태로 다음과 같은 구조를 가지고 있다고 가정해보겠습니다.
\[ y = \beta_0 + \beta_1x + \beta_2z + \beta_3xz + \beta_4w + \beta_5m + \beta_6mw \]
하나의 그래프는 \(x\)와 \(z\)에 초점을 맞춘 것이어야 하고, 다른 하나는 \(m\)과 \(w\)의 관계를 보여주어야 하는 것이라고 하겠습니다. 먼저 QoG 데이터셋의 2015년도 자료를 통해서 변수들을 다음과 같이 모델링 해보겠습니다.
\[ \begin{aligned} \text{경제규모} =&\beta_0 + \beta_1\text{무역개방성} + \beta_2\text{민주주의} + \beta_3(\text{무역개방성}\times\text{민주주의})\\ +&\beta_4\text{농지 비율} + \beta_5\text{노령인구비율} +\beta_6(\text{농지비율}\times\text{노령인구비율}) \end{aligned} \]
나중에야 R의 Zelig 패키지나 STATA의 Clarify를 이용할 수 있겠지만, 여기서는 기본적인 논리를 이해하며 코딩을 전개하고자 하기 때문에 좀 원시적인(?) 방식으로 코드를 짜보도록 하겠습니다.
pacman::p_load(ezpickr, mvtnorm, tidyverse)
QOG2 <- QOG |>
dplyr::filter(year == 2015) |>
dplyr::select(ccode, wdi_gdpcapcon2010, p_polity2, wdi_trade,
wdi_pop1564, wdi_agedr, wdi_araland) |> drop_na()데이터를 불러와 주었으니 이제는 모델을 만들어야겠죠? 단위의 문제가 있으니 종속변수인 경제규모의 측정지표, 1인당 GDP는 로그값을 취하도록 하겠습니다.
model1 <- lm(log2(wdi_gdpcapcon2010) ~ wdi_trade + p_polity2 +
I(wdi_trade * p_polity2) + wdi_araland + wdi_agedr +
I(wdi_araland * wdi_agedr), data=QOG2)
model1 |> broom::tidy() |>
mutate_if(is.numeric, round, 3) |>
knitr::kable()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 16.851 | 0.715 | 23.576 | 0.000 |
| wdi_trade | 0.005 | 0.003 | 1.579 | 0.117 |
| p_polity2 | 0.075 | 0.039 | 1.922 | 0.057 |
| I(wdi_trade * p_polity2) | 0.000 | 0.000 | 0.602 | 0.548 |
| wdi_araland | -0.054 | 0.029 | -1.845 | 0.067 |
| wdi_agedr | -0.084 | 0.010 | -8.705 | 0.000 |
| I(wdi_araland * wdi_agedr) | 0.001 | 0.000 | 1.131 | 0.260 |
일단 회귀분석 결과를 summary를 통해 살펴보면 상호작용들 모두 유의미하지 않는 것으로 나타나네요. 뭐 어쩔 수 없습니다. 그렇다고 하더라도 이 작업이 무의미하지는 않으니까요.
제가 관심이 있는 것은 변수들 간의 상호작용입니다. 먼저 \(x\), \(z\)에 해당하는 변수, 무역개방성과 민주주의의 관계를 살펴보도록 하겠습니다.
set.seed(19891224)
beta_draws <- rmvnorm(n=1000, mean = coef(model1), sigma=vcov(model1))
head(beta_draws) (Intercept) wdi_trade p_polity2 I(wdi_trade * p_polity2) wdi_araland
[1,] 17.23158 -0.001321063 0.04673637 0.0005194318 -0.01716309
[2,] 18.52625 -0.002157919 0.04129964 0.0008712935 -0.07170068
[3,] 17.03413 0.001507908 0.01122512 0.0006596835 -0.05526781
[4,] 18.07822 0.004928456 0.03685346 0.0006261671 -0.09405449
[5,] 16.52870 0.007434208 0.10491406 -0.0002519455 -0.01721839
[6,] 16.53057 0.005413327 0.13277980 -0.0001899500 -0.04771521
wdi_agedr I(wdi_araland * wdi_agedr)
[1,] -0.08118915 -0.00002071477
[2,] -0.09922753 0.00064049587
[3,] -0.08193179 0.00068112845
[4,] -0.10168630 0.00130281394
[5,] -0.07824166 -0.00012395073
[6,] -0.08377743 0.00047608418rmvnorm은 다변량 정규분포(multivariate normal distribution)의 무작위 추출을 가능하게 하는 함수입니다. 위의 코드에 따르면 평균을 모델의 각 계수값으로 하고 각 계수들 간의 분산-공분산을 표준편차로 하는 분포로부터 각각의 계수값들의 1000회 추출한 시뮬레이션 분포를 beta_draws라는 객체에 저장하라는 내용입니다. 자세한 내용은 다루지 않겠습니다만, 간단하게 이야기하면 추정된 OLS 계수를 평균으로 하는 분포에서 시뮬레이션된 분포를 뽑되, 그 표준편차를 계수들 간의 공분산 즉, 계수들 간에 상관을 일종의 표준오차로 고려하여 추출하라는 것입니다.
이렇게 1000개에 해당하는 시뮬레이션된 계수값을 얻었으니, 이제는 우리가 관심을 가지고 있는 변수의 범위를 설정해주어야겠죠? 높은 수준의 무역개방성과 낮은 수준의 무역개방성을 보여주기 위하여 상위 15%에 해당하는 값과 하위 15%에 해당하는 값을 quantile 함수를 이용하여 벡터화 하였습니다. 이를 trade라는 별도의 객체에 저장하겠습니다. 또한 민주주의의 수준이 변화함에 따라 이 서로 다른 수준의 무역개방성이 경제규모에 미치는 효과를 탐색해야하기 때문에 민주주의 수준의 변화도 벡터화하여 포함하여 줍니다. POLITY2는 -10부터 10까지 1의 간격을 가진 변수기 때문에 그대로 반영해서 백터화하였습니다.
trade <- quantile(QOG2$wdi_trade, c(0.15, 0.85))
trade 15% 85%
45.28606 121.64338 democracy <- c(seq(-10, 10, by=1))
democracy [1] -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8
[20] 9 10그리고 나서 이제는 \(\bar{\textbf{X}}\)를 \(\underline{\text{무역개방성}}\)과 \(\overline{\text{무역개방성}}\)에 해당하도록 만들어줍니다. 무역개방성과 민주주의를 제외한 나머지 모든 변수들이 평균값을 가진다고 할 때, 무역개방성의 수준 차이가 민주주의 수준의 변화에 따라 어떻게 경제규모에 영향을 미치는지 살펴보겠습니다.
# Low level of trade openness
LowTrade <- cbind(1, trade[1],
democracy,
I(trade[1] * democracy),
mean(QOG2$wdi_araland), mean(QOG2$wdi_agedr),
I(mean(QOG2$wdi_araland) * mean(QOG2$wdi_agedr)))
# High level of trade openness
HighTrade <- cbind(1, trade[2],
democracy,
I(trade[2] * democracy),
mean(QOG2$wdi_araland), mean(QOG2$wdi_agedr),
I(mean(QOG2$wdi_araland) * mean(QOG2$wdi_agedr)))나머지는 \(\hat{\textbf{Y}} = \bar{\textbf{X}}\hat{\textbf{b}}\)에 대한 항렬계산을 R 코드로 구현하는 것입니다.
LowTrade.ME <- t(LowTrade %*% t(beta_draws))
LT.mean <- apply(LowTrade.ME, 2, mean)
LT.se <- apply(LowTrade.ME,2,
quantile, c(0.025, 0.975))
HighTrade.ME <- t(HighTrade %*% t(beta_draws))
HT.mean <- apply(HighTrade.ME, 2, mean)
HT.se <- apply(HighTrade.ME, 2,
quantile, c(0.025, 0.975))
LT <- data.frame(Democracy=democracy,
Group = "Low Trade",
Mean=LT.mean, Lower=LT.se[1,], Upper= LT.se[2,])
HT <- data.frame(Democracy=democracy,
Group = "High Trade",
Mean=HT.mean, Lower=HT.se[1,], Upper= HT.se[2,])
Trade <- bind_rows(LT, HT)
Trade |>
ggplot(aes(x=Democracy, y=Mean, color=Group, shape=Group)) +
geom_point() +
geom_pointrange(aes(y = Mean, ymin = Lower, ymax = Upper)) +
scale_x_continuous(breaks = democracy)+
theme(axis.text.x = element_text(vjust=0.5)) +
labs(#title="Economy Size (logged) by the Level of Democracy",
x="Level of Democracy", y="Economy Size (logged)",
caption="Vertical bars indicate 95-percent confidence intervals") +
theme_bw() + theme(legend.position = "bottom")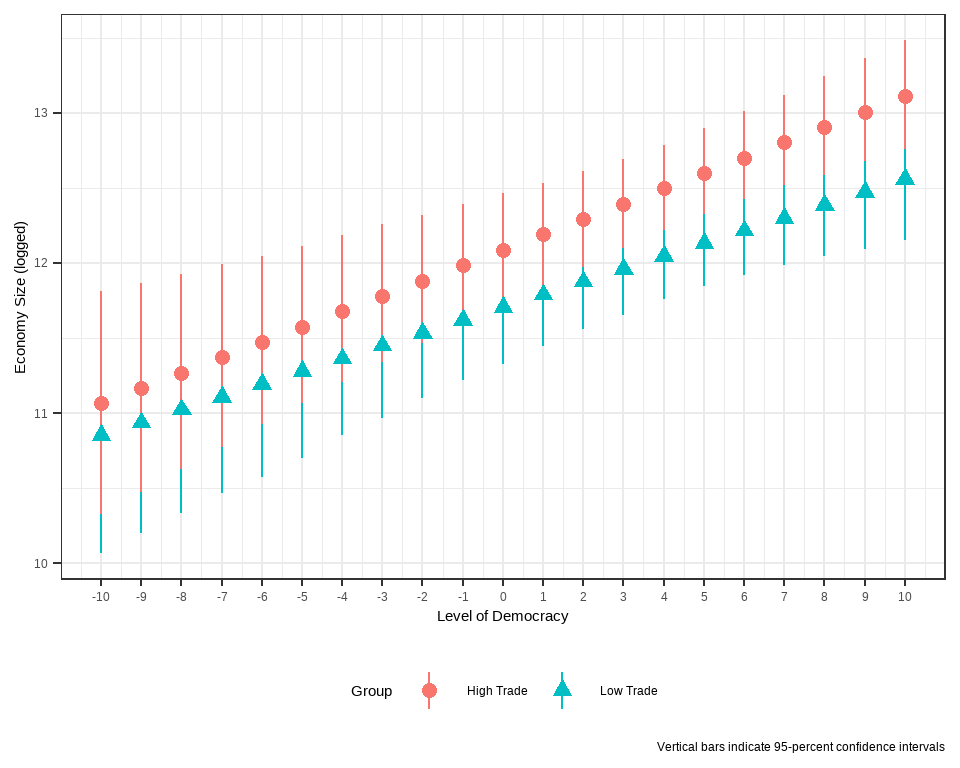
상호작용 변수가 유의미하지 않은 것을 쉽게 이해할 수 있습니다. 왜냐면 민주주의 수준이 변화하는 전 구간에 걸쳐서 높은 수준의 무역개방성과 낮은 수준의 무역개방성이 경제규모에 미치는 효과가 모두 중첩됩니다. 즉, 두 효과가 통계적으로 유의하게 차이난다고 볼 수 있는 경험적 근거가 충분치 않기 때문에 우리는 두 효과가 서로 같다(다르지 않다)라는 영가설을 기각할 수 없게 됩니다.
이번에는 농지 비율과 노령인구비율의 관계를 살펴볼 것인데요, 똑같습니다. 이번에는 농지비율의 변화에 따라 높은 수준과 낮은 수준의 노령인구비율이 경제규모에 미치는 효과의 변화를 살펴볼 것입니다. 다만, POLITY2와 다르게 농지 비율은 1 단위로 변화하지는 않습니다. 따라서 저는 summary 함수를 이용해 농지 비율 변수의 척도를 확인하고, 최소값부터 최대값까지를 포함할 수 있는 범주를 설정하고 5라는 단위로 인터벌을 가지게끔 하였습니다.
age <- quantile(QOG2$wdi_agedr, c(0.15, 0.85))
age 15% 85%
44.20432 82.99981 summary(QOG2$wdi_araland) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.1685 5.1514 12.3059 16.1934 23.0050 59.4011 agriland <- c(seq(0, 60, by = 5))여기서 중요한 점은 예측변수의 행렬을 만들 때, 나중에 행렬곱셈을 해줄 시뮬레이션된 계수값들의 순서는 OLS 분석에 투입된 변수 순서와 같다는 것입니다. 이를 고려해서 변수를 조작해주어야 합니다.
LowAge <- cbind(1, mean(QOG2$wdi_trade), mean(QOG2$p_polity2),
I(mean(QOG2$wdi_trade) * mean(QOG2$p_polity2)),
agriland, age[1],
I(agriland * age[1]))
HighAge <- cbind(1, mean(QOG2$wdi_trade), mean(QOG2$p_polity2),
I(mean(QOG2$wdi_trade) * mean(QOG2$p_polity2)),
agriland, age[2],
I(agriland * age[2]))
LowAge.ME <- t(LowAge %*% t(beta_draws))
LA.mean <- apply(LowAge.ME, 2, mean)
LA.se <- apply(LowAge.ME, 2,
quantile, c(0.025, 0.975))
HighAge.ME <- t(HighAge %*% t(beta_draws))
HA.mean <- apply(HighAge.ME, 2, mean)
HA.se <- apply(HighAge.ME, 2,
quantile, c(0.025, 0.975))
LA <- data.frame(Arable=agriland,
Group = "Low Age Dependency",
Mean=LA.mean, Lower=LA.se[1,], Upper= LA.se[2,])
HA <- data.frame(Arable=agriland,
Group = "High Age Dependency",
Mean=HA.mean, Lower=HA.se[1,], Upper= HA.se[2,])
Age <- bind_rows(LA, HA)
Age |>
ggplot(aes(x=Arable, y=Mean, color=Group, shape=Group)) +
geom_point() +
geom_pointrange(aes(y = Mean, ymin = Lower, ymax = Upper)) +
scale_x_continuous(breaks = agriland) +
theme(axis.text.x = element_text(vjust=0.5)) +
labs(#title="Economy Size (logged) by the Level of Arable land",
x="Arable land (% of land area)", y="Economy Size (logged)",
caption="Vertical bars indicate 95-percent confidence intervals") +
theme_bw() +
theme(legend.position = "bottom",
legend.text=element_text(size=8.5))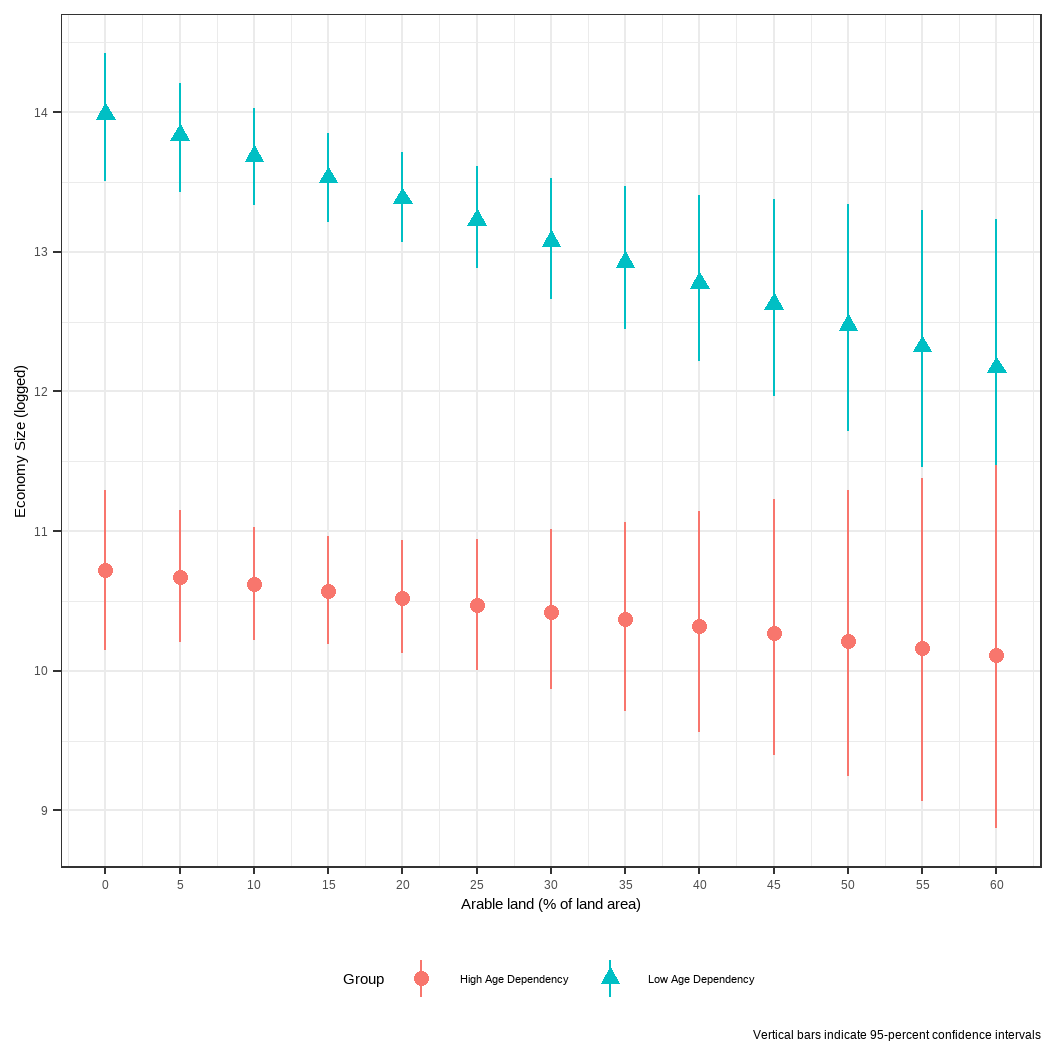
어라? 여기서 재밌는 결과가 나옵니다. 틀림없이 농지 비율과 노령인구비율의 상호작용항은 통계적 유의성이 없는 것으로 나타났는데, 그래프는 농지 비율이 낮은 경우에는 낮은 수준의 노령인구비율이 경제규모에 미치는 효과가 높은 수준의 노령인구비율보다 더 높게 나타났습니다. 단, 이러한 차이는 농지 비율이 증가할수록 점차 수렴하여 종래에는 두 효과가 통계적으로 유의미한 차이를 보이지 않는 다는 것을 보여주었습니다.
이 결과가 보여주는 바는 명확합니다. 사실 OLS 결과표에서 상호작용항에 대한 계수값은 저 모든 효과를 뭉뚱그려서 평균 효과를 보여주는 것에 불과합니다. 아마도 노령인구비율이 고만고만한 차이를 보이는 중간 지점의 국가들에서는 저러한 효과가 눈에 보이지 않게 혼재되어 있을 수 있습니다. 하지만, 적어도 우리는 데이터를 통해서 1차 차분값의 결과가 저러한 정보를 내재하고 있다는 것을 보여줄 수 있고, 나아가 실질적인 함의를 도출하며 독자로 하여금 분석의 의의를 이해하는 데 도움을 줄 수 있습니다.
비모수 부트스트랩 vs. 모수적 부트스트랩
마지막으로 챕터 7과 여기 챕터 8에서 각각 다루었던 비모수 부트스트랩과 모수적 부트스트랩의 이론적 차이에 대해서 간단하게 얘기해보고자 합니다. 이 둘의 차이는 모집단의 분포를 가정하느냐, 혹은 가정하지 않느냐에 좌우된다고 할 수 있습니다. 비모수 부트스트랩이 모집단의 분포를 가정하지 않습니다. 비모수 부트스트랩을 사용해 우리는 하나의 표본(원 표본)으로부터 무수히 많은 수의 부트스트랩 표본을 추출할 수 있습니다. 이 부트스트랩 표본에 속하게 될 관측치들은 원 표본으로부터 모두 동일한 확률로 추출됩니다. 즉, 무작위로 추출됩니다. 비모수 부투스트랩은 부스트스랩 포본들을 통해 얻은 표본 통계치들의 분포를 표집분포로 활용합니다. 따라서 비모수 부트스트랩을 이용할 경우, 우리는 OLS의 고전적인 가정들에 굳이 집착할 필요가 없습니다. 반복된 표집을 통해 우리는 반복 추출된 부트스트랩 표본들의 통계치들의 분포를 직접 관측할 수 있기 때문에 오차분산의 정규성 등과 같은 가정을 할 필요가 없습니다. 부트스트랩하고, 표집을 반복하면 우리는 바로 \(\hat{\beta}\)의 분포를 얻을 수 있으니까요.
한편, 모수적 부트스트랩은 우리가 얻은 표본이 알려지지 않은 모수를 가진, 알려진 분포로부터 얻어졌다고 가정합니다. 모수적 부트스트랩에 따르면 우리는 원 표본이 특정한 분포를 따르는 모집단으로부터 추출되었다고 가정합니다. 따라서 우리는 특정한 부포를 가정하는 통계 기법과 방법을 이용하여 표본을 가지고 모집단의 모수를 추정할 수 있습니다. 만약 우리가 모집단이 어떠한 분포를 따른다는 가정 하에서 표본이 뽑혔다고 가정한다면, 우리가 표본으로부터 얻은 추정값 역시 어떠한 분포를 가정했을 때, 그리고 모수가 가질 것으로 여겨지는 조건들을 충족했을 때 신뢰할만한 것이라고 여길 수 있다는 것입니다. 예를 들어, OLS 추정치가 BLUE라고 주장할 수 있다고 하겠습니다. 그렇다면 우리는 이 계수추정치에 모수적 부트스트랩을 적용하기만 하면 됩니다. 중심극한정리에 따라, 부트스트랩 표본 추출 횟수가 증가할수록 OLS 계수값을 평균으로 취하는 표집분포는 정규 분포에 점차 근사할 것이기 때문입니다. 모수적 부트스트랩을 통해 우리는 OLS 추정결과에 대해 분석적 결과(analytic results)에 비해서 더 풍부한 정보를 가진 수치들을 얻을 수 있습니다.
만약 우리가 부트스트랩 표본 추출 횟수를 많이 할 수 있다고 한다면, 모수적 부트스트랩과 비모수 부트스트랩은 표본 규모가 작더라도 유사한 결과를 제공할 것입니다. 그러나 부트스트랩 표본 추출 횟수가 감소하거나 표본의 분포가 매우 한 쪽으로 치우쳐져 있다거나 극단적인 값들을 많이 포함하고 있다면, 이 두 부트스트랩 방법을 통해 얻은 결과는 꽤 다를 수 있습니다.
Footnotes
여기서의 신뢰도란 reliability로 모집단에서 다른 표본을 추출해 동일한 모델을 돌리더라도 우리가 처음에 얻은 결과가 재생산될 것이라는 개념입니다. 화살 과녁에 비유하자면 내가 쏜 10발의 화살이 모두 원하는 장소에 적중하는 것은 정확하고 적실한 개념을 사용했다하여 타당성(validity)이 충족되었다고 하고, 10점은 아니지만 10개의 화살이 쏠 때마다 7점이면 7점, 8점이면 8점에 고루 모여있는 것을 다음 결과 역시 어떻게 나올지 신뢰할만하다 하여 신뢰도(reliability)가 높다고 합니다.↩︎
Gelman, Andrew. 2008. “Scaling Regression Inputs by Dividing by Two Standard Deviations.” Statistics in Medicine 27: 2865-73.↩︎