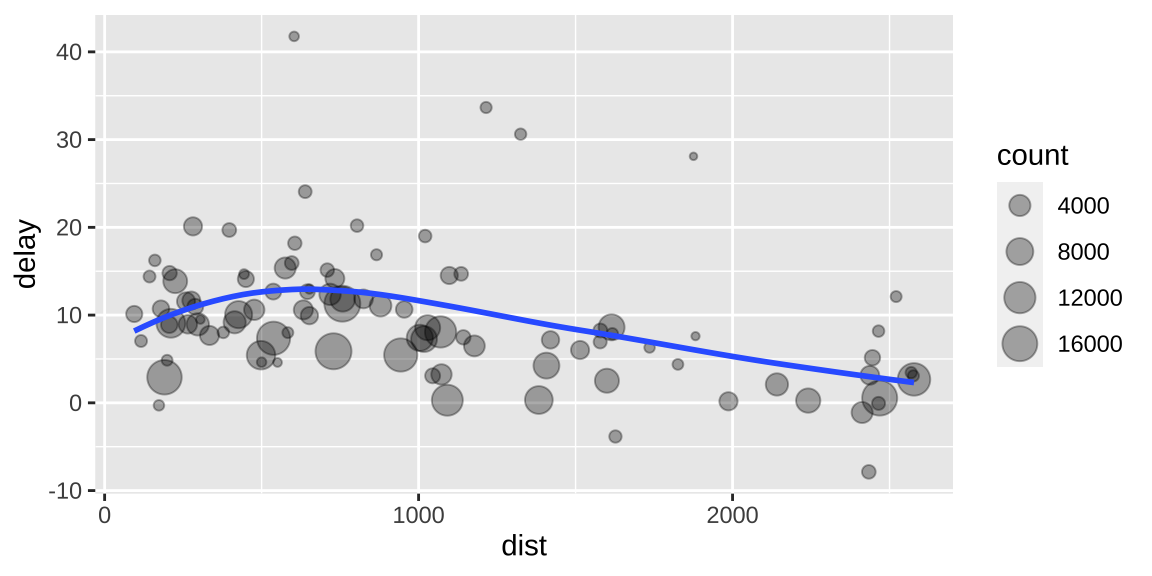
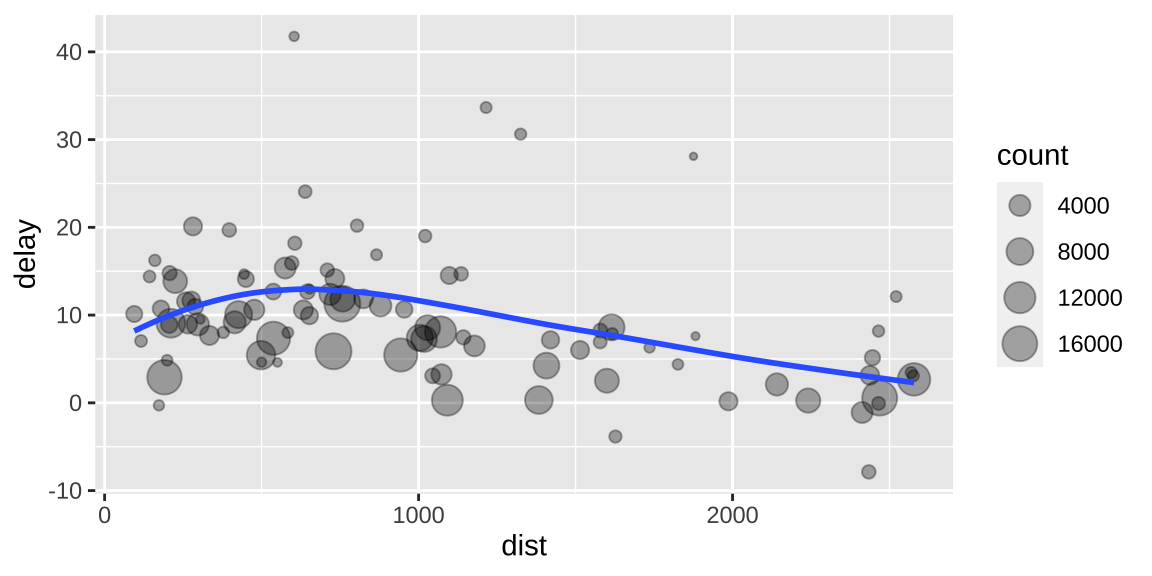
Rows: 200
Columns: 12
$ class <chr> "suv", "pickup", "suv", "suv", "suv", "compact", "minivan…
$ drv <chr> "r", "4", "4", "4", "4", "f", "f", "f", "4", "f", "f", "4…
$ year <dbl> 1999, 1999, 2008, 2008, 1999, 2008, 2008, 1999, 2008, 199…
$ displ <dbl> 5.4, 3.9, 4.7, 4.6, 5.7, 2.0, 3.3, 2.4, 3.7, 1.9, 2.0, 4.…
$ cty <dbl> 11, 13, 13, 13, 11, 22, 17, 18, 15, 33, 21, 12, 19, 16, 2…
$ fl <chr> "r", "r", "r", "r", "r", "p", "r", "r", "r", "d", "p", "r…
$ hwy <dbl> 17, 17, 17, 19, 15, 29, 24, 24, 19, 44, 29, 16, 25, 25, 3…
$ filename <fs::path> "data/unclean_files/1.csv", "data/unclean_files/1.cs…
$ model <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ trans <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ cyl <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ manufacturer <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…