Ordinary Least Squares II
Working with interactions in your regression
Working with interactions in your regression
상호작용(Interactions)
일반적으로 우리가 다중선형회귀모델을 수립한다고 할 때, \(y = \alpha + \beta x + \gamma z + \nu\)라고 할 수 있을 것입니다. 이때, \(y\)에 대한 \(x\)의 효과는 무엇으로 알 수 있을까요? \(\partial y/\partial x\)겠죠? 그리고 위의 식에서는 \(\beta\)일겁니다. 그런데 만약 \(\partial y/\partial x\)가 \(\beta + \gamma z\)라면 어떻게 될까요? \(\partial y/\partial x = \beta + \gamma z\)인 경우를 상정해보겠습니다. 이 경우 \(\beta\)의 의미는 무엇일까요?
자, 상호작용을 보다 명시적으로 보여주는 회귀모델을 만들어보겠습니다. \[y = \alpha + \beta x + \tau xz + \gamma z + \nu\] 이 회귀모델에서 \(\beta\)는 무엇을 의미할까요? 상호작용이란 \(y\)에 대한 \(x\)의 효과가 본질적으로 \(z\)라는 변수와 밀접하게 연관되어 있는 경우를 말합니다. 따라서 \(z=0\)인 경우를 제외하면, \(x\)에 대한 계수값은 결코 그 자체로 그대로 해석될 수 없습니다. 왜냐하면 \(x\)의 계수값은 \(z\)의 값에 따라 조건적으로 변화할테니까요. 상호작용에 대한 이론적인 검토는 다음 장에서 이어서 하도록 하고, 여기서는 기본적인 내용들을 간단한 R 예제와 함께 살펴보도록 하겠습니다. \(y = \beta_0 + \beta_1x + \beta_2x^2 + \beta_3z + u\)의 형태를 취하는 회귀모델이 있다고 해보겠습니다.
사용할 데이터는 언제나와 같이 Quality of Government에서 가져오며 2016년 데이터입니다.
library(ezpickr)
library(tidyverse)
QOG <-
ezpickr::pick(file = "http://www.qogdata.pol.gu.se/data/qog_bas_ts_jan21.dta")
QOG.s <-QOG %>%
dplyr::select(ccode, cname, year, wdi_agedr,
wdi_trade, wdi_gdpcapcon2010,
wdi_fdiin, wdi_pop1564) %>%
dplyr::filter(year==2016) %>% drop_na()
rm(QOG)QOG 데이터셋에서 국가코드, 국가명, 연도, 노령화 지수, 무역 개방성, 1인당 GDP, 해외직접투자유입량(FDI inflow), 노동가능인구에 해당하는 변수들을 따로 선별하여 서브셋을 만들고, 결측치를 제외하였습니다. 그리고 1인당 GDP가 무역 개방성, 무역 개방성의 제곱항, 그리고 노령화 지수와 각각 관계를 맺고 있다는 선형회귀모델을 구축하였습니다.
model <- lm(wdi_gdpcapcon2010 ~
wdi_trade + I(wdi_trade^2) + wdi_agedr,
data=QOG.s)
model %>% broom::tidy() %>%
mutate_if(is.numeric, ~ round(., 3)) %>%
knitr::kable()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 38520.843 | 7330.614 | 5.255 | 0.000 |
| wdi_trade | -129.653 | 69.676 | -1.861 | 0.065 |
| I(wdi_trade^2) | 0.819 | 0.211 | 3.885 | 0.000 |
| wdi_agedr | -362.454 | 80.055 | -4.528 | 0.000 |
구체적으로 위의 모델은 2010년도 미 달러 고정으로 측정된 2016년도의 1인당 GDP가 각 국가의 무역 개방성과 노령화 지수와 관계가 있다는 것을 보여주고 있습니다. 모델에서 무역 개방성은 국내 총생산에서 재화 및 서비스의 수출입의 총합이 차지하는 비율로 측정되었으며, 노령화 지수는 노동가능인구 대비 65세 이상 인구의 비율을 의미합니다. 이 회귀모델은 다중회귀모델의 형태를 취하고 있으므로(\(y = \beta_0 + \beta_1x + \beta_2x^2 + \beta_3z + u\)), 우리는 \(y\)(1인당 GDP)의 변화량이 \(x\)(무역 개방성)와 \(z\)(노령화지수)에 의해 설명된다고 진술할 수 있습니다.
그러나 이 모델은 동시에 \(x\)와 \(x^2\)을 포함하고 있습니다. 이는 \(x\)의 \(y\)에 대한 한계효과(marginal effect)가 \(\beta_1\) 뿐 아니라 \(\beta_2\)에 의해서도 영향을 받는다는 것을 의미합니다. \(x\)를 기준으로 편미분을 해보면, \(\frac{\partial y}{\partial x} = \beta_1 + 2\beta_2x\)가 되기 때문입니다. 정리하자면, 이 모델은 \(y\)의 변화량이 \(x\)와 \(z\)에 의해 설명될 수는 있지만, \(x\)와는 그 관계가 선형적일 것이라고 볼 수는 없다는 것을 의미합니다. 그러면 이 모델의 각각의 계수들(coefficients)을 해석해보겠습니다.
상수항(절편; intercept): \(\hat{\beta_0}\)는 PRF의 \(\beta_0\)의 추정치이자 \(x\)와 \(z\) 모두가 0일 경우의 \(y\)의 값입니다.
기울기(slopes)
\(\hat{\beta_1}\)는 PRF의 \(\beta_1\)의 추정치이자 \(x^2\)와 \(z\)로 설명될 수 있는 변화량을 제외한 \(y\)와 \(x\) 간의 관계를 보여줍니다. \(\hat{\beta_1}\)의 표준오차는 PRF를 추정하기 위해 우리가 수없이 표본들을 뽑아 PRF에 대응하는 SRF를 만들었을 때, 표본의 차이로 인해 각 SRF에서 나타날 \(\hat{\beta^i_1}\)들의 표집분포의 표준편차를 의미합니다.
\(\hat{\beta_2}\)는 PRF의 \(\beta_2\)에 대한 추정치를 의미하며, 순수하게 \(x\)와 \(z\)에 의해 설명되는 \(y\)의 변화량을 제외하고 \(x^2\)로 설명되는 \(y\)의 변화량에 대한 관계를 보여줍니다. 마찬가지로 그 표준오차는 PRF를 추정하기 위한 SRF에서 도출되는 \(\hat{\beta^i_2}\)의 표집분포의 표준편차를 보여줍니다.
\(\hat{\beta_3}\)는 \(x^2\)과 \(x\)로 설명되는 \(y\)의 변화량을 제외하고 \(y\)와 \(z\) 간의 관계를 보여주며, 그 표준오차는 \(\hat{\beta^i_3}\)의 표집분포의 표준편차라고 할 수 있습니다.
앞서 말했다시피 \(\hat{\beta_0}\)는 \(x\)와 \(z\)가 0일 경우의 \(y\) 값, 절편을 의미합니다. 이 값은 고정되어 있으므로 우리는 상수항이라고도 합니다. 이론적으로 변수인 \(y\)는 오직 다른 변수로만 설명할 수 있습니다. 따라서 우리는 기울기들에 좀 더 초점을 맞출 필요가 있습니다.
그런데 이 모델에서 우리는 \(\hat{\beta_1}\), \(\hat{\beta_2}\), 그리고 \(\hat{\beta_3}\)를 직접적으로 비교할 수 없습니다. 왜냐하면 \(\hat{\beta_3}\)는 \(y\)와 \(z\) 간 관계를 선형으로 상정하고 있지만 \(y\)와 \(x\)는 비선형성을 보여주고 있고, 특히 \(x^2\)과 \(y\)의 관계를 보여주는 계수는 그 자체로 설명될 수 없고 \(\beta_1\)에 의존적인 값이기 때문입니다. 따라서 이 모델이 다중선형회귀모델의 형태를 취하고 있다고 하더라도 \(\hat{\beta_1}\), \(\hat{\beta_2}\), \(\hat{\beta_3}\)의 세 계수들은 직접적으로 비교되기는 어렵습니다. 또한 \(\hat{\beta_1}\), \(\hat{\beta_2}\)는 \(x\)로 다시 써볼 수 있는데, 다시 한 번 말하지만 \(\hat{\beta_1}\) 또는 \(\hat{\beta_2}\)는 단독으로는 의미가 없습니다.
상호작용항이 흥미로운 이유는 무엇일까요? 우리가 이차항(quadratic term)을 포함시키고, \(\hat{\beta_1}\)과 \(\hat{\beta_2}\)를 구했다고 할 때, 단적으로 말하면 \(\hat{\beta_1}\)과 \(\hat{\beta_2}\) 그 자체의 값에는 크게 신경쓰실 필요가 없습니다. 만약 단순선형회귀모델이었다거나 다중선형회귀모델이었다면 \(\hat{\beta_1}\)과 \(\hat{\beta_2}\)가 \(x\)의 한 단위 변화와 관계된 \(y\)의 변화를 체계적으로, 일관되게 보여줄 것으로 기대하기 때문에 관심을 가질 필요가 있습니다.
그러나 이차항, 혹은 상호작용항을 모델에 포함한다면, \(x\)에 따른 \(y\)의 변화는 \(\frac{\partial y}{\partial x} \approx \hat{\beta_1} + 2\hat{\beta_2}x\)로 나타낼 수 있고, 이는 \(x\)의 \(y\)에 대한 한계효과가 “변할 수도 있고,” “비선형적일 수도 있다는 것”을 의미합니다. 따라서 \(\hat{\beta_1}\)과 \(\hat{\beta_2}\) 그 자체는 \(x\)와 \(y\)의 관계에 대해서 거의 말해주는 것이 없습니다. \(\hat{\beta_1}, \hat{\beta_2}\)의 값과 그 크기보다는 \(x\)와 \(y\)의 비선형적 관계의 방향성을 보여줄 수도 있는 부호에 관심을 가지는 것이 더 나을 것입니다. 또한, 우리는 \(x\)에 대한 서로 다른 값들 간 한계 효과의 차이에 초점을 맞춰야 합니다. 예를 들어, \(x\)의 최소값과 최대값 간 한계효과를 비교함으로써 우리는 \(y\)의 변화 양상을 포착할 수 있기 때문입니다.
즉, 상호작용은 선형회귀모델에서 한 변수의 종속변수에 대한 효과가 상수(constants)가 아니라 변수(variables)일 경우를 어떻게 이해하느냐의 문제라고 할 수 있습니다.
상호작용의 유무 비교
일반적인 가산적(additive) 선형회귀모델과 상호작용을 전제하고 있는 선형회귀모델을 각각 구성해보도록 하겠습니다.
\[ \begin{aligned} \text{상호작용이 없는 경우: }y&= \alpha +\beta x + \gamma z+ \nu\\ \text{상호작용이 있는 경우: }y&= \alpha +\beta x + \tau xz + \gamma z+ \nu \end{aligned} \]
자, 두번째의 식이 맨 처음의 식과 달라진 부분이 보이시나요? 위의 식에서 \(\beta\)는 무엇을 의미할까요? 과연 우리가 \(x\)에 대한 \(y\)의 효과를 맨 처음의 식에서와 같이 \(\beta\)만을 가지고 충분히 이해할 수 있을까요?
바로 위의 식에서는 \(y\)에 대한 \(x\)의 효과를 \(\beta\)로만 이해할 수 없습니다. 정확히는 \(y\)에 대한 \(x\)의 효과는 근본적으로 제3의 변수, \(z\)와 얽혀 있습니다. 따라서 이때 우리는 \(y\)에 대한 \(x\)의 효과를 \(\beta\) 그 자체로만 가지고 해석할 수 없습니다. 만약 \(z\)가 0일 경우에만 \(x\)와 \(y\)의 관계에서 \(\beta\)가 단독으로 의미를 가지게 됩니다. \(z\)가 0이면 위의 식에서 \(\tau xz\)라는 항이 아예 사라지게 되니 고려할 필요가 없게 되는 것입니다.
상호작용의 이해: Brambor et al. (2006)
정치학 분야에서 상호작용에 관한 방법론을 다룰 때, 거의 필수적으로 읽고 넘어가는 논문을 간단하게 한 번 살펴보고자 합니다. Brambor, Golder, 그리고 Clark이 2006년도에 저술한 ‘’Understanding Interaction Models: Improving Empirical Analyses’‘이라는 제목의 논문입니다. 우리말로는’‘상호작용 모델의 이해: 경험적 분석의 개선’’ 정도로 이해할 수 있겠네요.
이 논문의 요지는 간단합니다. 상호작용항(interaction term)을 다중선형회귀모델에 투입하여 변수들이 종속변수에 대해 상호작용하여 미치는 영향을 살펴보고자 하는 이른바 상호작용 모델의 연구가설은 ‘조건적인 가설’(conditional hypotheses)을 가지게 됩니다. 즉, 서로 상호작용하는 변수들은 각자에 대하여 ‘의존적인’ 관계에 놓이게 된다는 것이죠.
Brambor et al. (2006) 은 이와 같은 상호작용항의 존재는 사실 다중선형회귀모델을 구성하는 Gaus-Markov 가정 중 변수들 간의 독립성에 해당하는 부분을 침해하는 것이기 때문에 이에 대한 조심스러운 접근이 필요함에도 불구하고 상호작용 모델을 사용하는 연구들이 고민없이 두 변수를 단순히 곱한 채 모델에 투입하는 등의 행태를 보이고 있다고 지적합니다.1
Brambor et al. (2006) 은 곱셈을 통해 만들어낸 상호작용항을 이용한 경험적 분석을 개선할 수 있는 몇 가지 방법들을 제안합니다. 이들은 정치학 분야에서 조건적 가설을 사용한 몇몇 연구들이 상호작용 모델을 구성하는 데 있어서 오류를 범해 그 연구결과로부터 도출된 추론이 잘못되었다는 사실을 지적합니다. 과학적 연구란 항상 ‘정답을 보여주는’ 연구가 아니라 어디까지나 ‘반증가능한’ 연구를 의미한다는 것을 생각해볼 때, 그리 놀라운 일은 아닙니다. 오히려 굉장히 정치학 분야에서 과학적 연구의 순기능이 작동한 사례라고 볼 수도 있을 것 같습니다.
Brambor et al. (2006) 의 핵심적인 주장—즉, 상호작용 모델을 이용한 경험적 연구의 개선방안은 크게 네 가지 정도로 정리해볼 수 있습니다.
첫째, 조건적 가설을 수립하고 그것을 경험적으로 분석하는 데에는 상호작용 모델이 요구된다.
둘째, 상호작용 모델을 사용할 때, 반드시 구성요소가 되는 변수들의 항(constitutive terms, 이하 구성항)을 모델에 모두 투입해야 한다. 예를 들어, \(x\), \(xz\), \(z\) 라는 세 예측변수들로 \(y\)를 설명하고자 할 때, 우리의 관심사가 상호작용의 관계, 즉 \(xz\)의 효과라고 하더라도 그 상호작용항을 이루는 \(x\)와 \(z\)의 각 변수 또한 모델에 투입해주어야 한다는 얘기입니다.
셋째, 구성항들은 기존의 다중선형회귀모델의 가산적 관계(additive relationship)에서 예측변수들을 다루듯 해석하기가 어렵다는 것입니다. 여기서 가산적 관계란 ‘+’, OR로 이루어진 관계로 각 변수들 간의 관계는 독립적이라는 가정이 성립된다는 것을 의미합니다. 그러나 위에서 잠깐 살펴보았던 것처럼 상호작용항의 경우에는 \(x\)의 \(y\)에 대한 효과가 \(z\)에 조건적이고, 반대로 \(z\)의 \(y\)에 대한 효과도 \(x\)에서 자유롭지 못하죠. 따라서 각 변수들이 서로 독립적일 것이라는 기대가 가능했던 기존의 다중선형회귀모델과는 달리 상호작용 모델에서 구성항들의 의미는 직관적으로 해석하기가 까다롭습니다.
마지막으로 넷째, 연구자들은 반드시 실질적으로 유의미한 한계효과(marginal effects)와 표준오차를 계산해야 한다고 제안합니다 (Brambor et al. 2006, 64).
논문의 저자들은 그들의 주장을 이해하기 쉽게 \(Y = b_0 + b_1 X + b_2 Z + b_3 XZ + \epsilon\)이라는 모델을 통해 풀어 나갑니다.
왜 조건적 가설을 수립하고 검증하기 위해서는 상호작용 모델을 사용해야만 하는가?
이론적으로 가산적 관계를 상정한 선형 모델은 각각의 예측변수들이 서로 독립적으로 종속변수와 관계를 맺고 있을 것이라고 봅니다. 이는 선형 모델의 경우 각 예측변수에 대해 조건적 가설이 아닌 독립적 가설을 수립하고 있다고 이해할 수 있습니다. 논문에 보시면 흔히, “다른 조건들이 모두 일정할 때, \(x\)의 \(y\)에 대한 효과는 어떠할 것이다” 라는 형태의 진술을 가설로 사용하는 것이 그러합니다. 다른 조건들이 모두 일정하다는 얘기는 다중선형회귀모델에서 우리가 관심을 가지고 있는 \(x\) 이외의 다른 모든 변수들을 상수로 고정하였을 때, \(x\)가 \(y\)에 미치는 부분적 효과(partial effect)만을 보겠다는 것이고, 이것이 이 챕터 맨 처음에 제시하였던 식에서의 \(\beta\)라고 이해할 수 있습니다.
그러나 여기서는 정치학이라고도 할 수 있겠습니다만 사회과학 제분야의 경우 어떠한 맥락 혹은 조건의 효과를 고려하는 것이 모델링에 주요한 영향을 미치기 때문에 상호작용항을 포함한 모델을 생각해보아야 하는 경우가 생길 때가 많습니다.
예를 들어, 한국의 선거정치 속에 나타나는 계급투표에 대해 관심이 있다고 해보겠습니다. 이때, 기존 연구들의 주요 가설은 소득 수준에 따라 돈 많은 사람은 세금 많이 떼기 싫고 기득권 층일테니 보수정당을 지지할 것이라고 기대하고, 반대로 돈 없는 사람은 복지지출 등을 제고하기를 기대하며 진보정당에 투표할 가능성이 클 것이라고 해보겠습니다.
이때, 나의 연구가설은 이러한 계급적 투표가 실제 선거에서 정당 선택으로 이어지는 관계가 개별 유권자들의 정치적 세련도, 혹은 정치지식 수준에 따라 달라진다는 조건적 가설일 수 있습니다. 왜냐하면 돈이 없더라도 정치지식 수준이 높은 사람들의 경우 특정 정책에 대한 이해도가 더 높아 정당 선호가 달라질 수 있으니까요. 다양한 논의가 가능하겠지만 일단 이런 맥락에서 사회과학 분야에서 상호작용 모델은 상당히 빈번하게 논의됩니다.
마찬가지로 Brambor et al. (2006) 도 조건적 가설의 사례를 하나 제시하는데, 그들이 제시하는 가설은 조금 더 통계적이라고 해야할까요, 도식적입니다. 실제 연구문제를 바탕으로 한 가설은 아닙니다. 일단 조건적 가설이라고 보기 어려운 경우를 한 번 보겠습니다.
그들은 “\(Z\)라는 조건이 존재할 때, \(X\)의 한 단위 증가가 \(Y\)와 관계를 가지고, \(Z\)라는 조건이 부재할 경우에는 \(X\)와 \(Y\) 간의 관계 또한 성립되지 않을 것이다”라는 가설을 제시합니다. 즉, 여기서 \(Z\)라는 변수는 특정 조건의 존재 여부를 보여주므로 이항변수(binary variable)이라고 할 수 있겠죠? 만약 우리가 이항변수 \(Z\)를 성별이라고 한다면, 이 성별 변수의 계수값은 \(Y\)에 있어서 남성과 여성일 경우 각기 다른 절편값으로 해석할 수 있을 겁니다. 남성이 1, 여성이 0이라고 한다면
\[ \begin{aligned} \text{여성}: Y&= b_0 + b_1X + b_2(Z=0) + \epsilon\\ &= b_0 + b_1X + \epsilon \\ \text{남성}: Y&= b_0 + b_1X + b_2(Z=1) + \epsilon\\ &= b_0 + b_1X + b_2 + \epsilon \end{aligned} \]
이때 이 두 식의 차이는 \(b_2\), 상수로 나타납니다. 따라서 이 경우에는 조건적 가설이라고 부르기가 어렵습니다.
왜 상호작용 모델에 모든 구성항을 다 포함해야할까?
그렇다면 왜 상호작용 모델에 모든 구성항을 다 포함해야만 할까요? 그리고 상호작용 모델에서의 구성항과 일반 가산적 관계의 선형 모델에서의 예측변수 간의 차이는 무엇일까요?
상호작용 모델(\(Y = b_0 + b_1X + b_2Z + b_3XZ + \epsilon\))에서 구성항을 제외한다면, 우리는 \(Y = b_0 + b_1XZ + \epsilon\)라는 모델을 생각해볼 수 있습니다. 구성항을 제외해도 말이 된다라는 얘기는 위의 \(Y = b_0 + b_1X + b_2Z + b_3XZ + \epsilon\)이 \(Y = b_0 + b_1XZ + \epsilon\)의 모델과 다르지 않다라는 주장을 해야한다는 것을 의미합니다. 이때, 만약 구성항을 제외한 모델이 타당하다면,
\(Z\)가 평균적으로 \(Y\)에 미치는 효과가 존재하지 않다거나
\(X\)가 0일 때, \(Z\)가 \(Y\)에 미치는 효과가 없다
라고 주장할 수 있어야만 합니다. 다시 말하면, 첫째로 \(Z\)가 평균적으로 \(Y\)에 미치는 효과가 없다는 얘기는 사실상 비체계적 요인으로서 \(Y\)에 평균적으로 체계적 변화를 가져오는 요인이 \(X\) 뿐이라고 주장하던가(이 경우 본질적으로 해당 모형의 함의는 \(Y = b_0 + b_1X + \epsilon\)과 다를 바 없게 됨), 혹은 \(X\)가 0일 때, \(b_1XZ\) 항이 제거되면서 절편값인 \(b_0 + \epsilon\)만 남게 되어 두 번째 주장이 타당하다고 말할 수 있어야 합니다. 그러나 위의 두 주장은 가설로서 거의 정당화되기 어렵습니다 (Brambor et al. 2006, 66). 왜냐하면 \(Y = b_0 + b_1X + b_2Z + b_3XZ + \epsilon\)에서 \(b_2\)는 상호작용 모델에서 \(X\)가 0일때의 \(Z\)가 \(Y\)에 미치는 효과를 보여주기 때문에, 이는 \(Z\)가 평균적으로 \(Y\)에 미치는 효과가 존재않다는 것을 보여주어야 하는 것과 배치됩니다. 마찬가지로 \(Z\)의 \(Y\)에 대한 평균적인 효과가 0이라고 하더라도 \(b_2\)가 반드시 0이라는 보장도 없습니다. \(X\)가 0일 때, \(Z\)가 \(Y\)에 대해 가지는 효과가 전혀 없다(\(b_2 = 0\))고 미리 전제하는 것보다는, \(b_2\)가 0이 아닐 수도 있을 가능성을 먼저 생각해보는 것이 더 많은 경우의 수를 제공합니다 (Brambor et al. 2006, 66). 다시 말해, 선험적으로 구성항을 제외하는 분석은 \(b_2\)가 0이 아니라면 우리가 관심을 가지고 있는 모수의 추정치를 왜곡하여 잘못된 추론을 도출하게 할 수 있습니다 (Brambor et al. 2006, 68).
위에서 언급한 바와 같이, \(X\)에 대한 계수, \(b_1\)와 \(Z\)에 대한 계수 \(b_2\)는 일반적인 가산적 관계의 모델(\(Y =b_0 + b_1X + b_2Z + \epsilon\))의 \(X\)와 \(Z\)의 계수들과는 다릅니다. 가산 모델에서 \(b_2\)는 \(Z\)의 \(Y\)에 대한 평균적인 효과를 보여줍니다. 그러나 상호작용 모델에서 \(b_2\)는 \(X\)에 따라 조건적으로 변화하는 \(Z\)의 \(Y\)에 대한 효과를 보여줍니다.
왜 실질적으로 유의미한 한계효과와 표준오차를 보여주어야 하는가?
상호작용 모델에 있어서 각 예측변수들이 종속변수에 미치는 효과를 제대로 보여주기 위해서 Brambor et al. (2006) 은 실질적으로 유의미한 한계효과와 표준오차를 함께 제시해야 한다고 주장하고 있습니다. 그 이유는 상호작용항의 효과가 일정하지 않기 때문(not constant)입니다. 상호작용 모델(\(Y = b_0 + b_1X + b_2Z + b_3XZ + \epsilon\))에서 \(X\)의 한 단위 증가와 관계된 \(Y\)의 변화분을 살펴보기 위해 편미분을 할 경우, 우리는 아래와 같은 식을 얻게 됩니다.
\[ \frac{\partial Y}{\partial X} = b_1+ b_3 Z \]
위의 식은 상호작용 모델에서 \(X\)의 \(Y\)에 대한 효과가 \(Z\) 변수의 값에 따라서 조건적으로 변화한다는 것을 의미합니다 (Brambor et al. 2006, 73). 따라서 상호작용항의 계수는 직접적으로 해석될 수는 없습니다. 그 값이 \(Z\)에 따라 변화하니까요. 우리는 계수의 부호나 통계적 유의성에 대해서는 이야기할 수 있지만 실질적으로 그 효과의 크기 등에 대해서는 계수만 보고는 대답할 수 없게 됩니다.
때문에 \(Z\)에 의해 조건적으로 변화하는 \(Y\)에 대한 \(X\)의 효과를 살펴보기 위해서는 \(X\)의 \(Y\)에 대한 한계효과를 계산할 필요가 있습니다. 한계효과는 \(Z\)의 조건 하에서 \(X\)의 한 단위 변화가 평균적으로 얼마만큼의 \(Y\)의 변화와 관계되는지를 보여줍니다. 또한 한계효과의 표준오차는 그렇게 계산된 한계효과가 얼마나 확실한지를 보여줍니다. 한계효과의 표준오차가 가지는 함의는 일반적으로 선형회귀모델의 계수값과 표준오차 간의 관계와 비슷하다고 이해하셔도 무방합니다. 그 한계효과가 통계적으로 유의미한 효과인지를 보여주는 것이니까요.
정리하자면 Brambor et al. (2006) 의 함의는 다음과 같습니다.
상호작용 모델이라고 하더라도 상호작용항뿐만 아니라 모든 구성항을 포함시켜 분석해야 한다.
“\(Z\)를 상수로 고정한다(=통제한다)”는 것은 \(Z\)가 0이라는 것과 같은 의미가 아니다.
모델 내에 존재하는 두 구성항의 곱으로 상호작용항을 만들었기 때문에 다중공선성(multicollinearity)이 발생할 수 있다.2
상호작용항의 계수는 \(\frac{\partial Y}{\partial X} = b_1+ b_3 Z\)로 나타낼 수 있고, 이때 상호작용의 계수가 편미분을 하더라도 \(Z\)라는 새로운 변수에 의해 조건적으로 변화할 수 있다는 것을 알 수 있다. 따라서 상호작용항의 계수를 직접적으로 일반선형회귀모델의 계수처럼 해석하기는 어렵다.
그렇다면 한 번 실제 데이터를 통해 분석해보도록 하겠습니다.
상호작용항의 이해: 경험적 분석
4개의 연속형 변수(\(x\), \(z\), \(y\), \(w\))를 가지고 다음과 같은 형태의 모델을 추정하고자 한다고 합시다: \(y = \gamma + \eta x + \alpha z + \mu xz + \beta w\). \(x\)와 \(z\)의 상호작용항이 포함되었으니 위의 식에서 \(x\)와 \(z\)의 효과를 단순히 \(\eta\)와 \(\alpha\)를 가지고 해석할 수는 없을 것입니다. 따라서 여기서는 \(x\)와 \(z\)의 변화에 따라서 각각 \(z\)와 \(x\)가 \(y\)에 대해 미치는 효과가 어떻게 조건적으로 변화하는지를 살펴보고자 합니다.
분석을 위해서 변수 \(x\)와 \(z\)가 높은 수준의 값을 지니는 경우를 \(\bar{x}\)와 \(\bar{z}\)라고 하겠습니다.
반대로 \(x\)와 \(z\)가 낮은 수준의 값을 지닐 때를 \(\underline{x}\), \(\underline{z}\)라고 표현하도록 하겠습니다.
그리고 위와 같은 분석적 프레임 하에서 다음과 같은 경우를 실제 모델과 데이터를 통해 살펴보도록 하겠습니다.
\[ \begin{aligned} E(y|x = \underline{x}, z = \underline{z}) - E(y|x = \bar{x}, z = \underline{z})\\ E(y|x = \underline{x}, z = \bar{z}) - E(y|x = \bar{x}, z = \bar{z}) \end{aligned} \]
\(x\)와 \(z\)에 관한 위의 두 표현이 과연 모델과 데이터와 관련해서 우리에게 어떤 실질적 함의를 제공해줄까요?
먼저 QOG 데이터셋에서 2014년도의 국가코드, 국가명, 연도, 해외직접투자 유입, 노동가능 인구, 무역 개방성, 1인당 GDP에 해당하는 변수들을 따로 선별하여 서브셋을 만들고, 결측치를 제외하였습니다. 그리고 1인당 GDP를 해외직접투자 유입, 무역 개방성, 그리고 해외직접투자 유입과 무역 개방성의 상호작용항과 노동가능 인구로 설명할 수 있다는 모델을 만들었습니다.
interactions <- lm(wdi_gdpcapcon2010 ~ wdi_trade + wdi_fdiin +
wdi_trade*wdi_fdiin + wdi_pop1564, data=QOG.s)원래는 모델에서 얻은 추정치(estimates)를 별도의 객체(objects)로 저장하여 작업하는 것을 선호하지는 않습니다. 하지만 여기서는 직관적으로 위에 써 놓은 두 모델과 연관지어 이해하기 위해서 각 변수와 계수를 별도의 객체로 저장한 뒤에 위의 두 식과 동일한 R 코드를 이용해 분석해보도록 하겠습니다.
먼저 모델에서 얻은 각 계수값을 위의 식에 상응하는 객체로 저장하여 줍니다.
그리고 각 변수들도 별도의 객체로 저장해보도록 하겠습니다.
이제 첫 번째 수식에 대응하는 계산을 수행합니다.
두 번째 수식에 대응하는 계산을 수행합니다.
# Step 1
b0 <- interactions$coefficients[1]
b1 <- interactions$coefficients[2]
b2 <- interactions$coefficients[3]
b3 <- interactions$coefficients[4]
b4 <- interactions$coefficients[5]
# Step 2
y <- QOG.s$wdi_gdpcapcon2010; x <- QOG.s$wdi_trade;
z <- QOG.s$wdi_fdiin; w <- QOG.s$wdi_pop1564
# Step 3
y1 <- b0 + (b1 * min(x)) + (b2 * min(z)) +
(b3 * min(x) * min(z)) + (b4 * w)
y2 <- b0 + (b1 * max(x)) + (b2 * min(z)) +
(b3 * max(x) * min(z)) + (b4 * w)
A1 <- y1 - y2
unique(A1)[1] 13888646 13888646# Step 4
y3 <- b0 + (b1 * min(x)) + (b2 * max(z)) +
(b3 * min(x) * max(z)) + (b4 * w)
y4 <- b0 + (b1 * max(x)) + (b2 * max(z)) +
(b3 * max(x) * max(z)) + (b4 * w)
A2 <- y3 - y4
unique(A2)[1] -20253324 -20253324위에서 만든 모델은 \(x\)와 \(z\), 즉 해외직접투자 유입과 무역 개방성 간의 상호작용항을 포함하고 있습니다. 그리고 이 두 변수는 ’서로에 대해 조건적’입니다. 따라서 두 변수가 모두 그 값이 변화한다고 할 때, 우리는 각 변수의 높은 값과 낮은 값을 최대값, 최소값으로 생각하여 다음과 같은 네 가지 시나리오를 생각해볼 수 있습니다.
\[ \begin{aligned} &\hat{y_1} = \gamma + \eta \underline{x} + \alpha \underline{z} + \mu \underline{x}\underline{z} + \beta w\\ &\hat{y_2} = \gamma + \eta \bar{x} + \alpha \underline{z} + \mu \bar{x}\underline{z} + \beta w\\ &\hat{y_3} = \gamma + \eta \underline{x} + \alpha \bar{z} + \mu \underline{x}\bar{z} + \beta w\\ &\hat{y_4} = \gamma + \eta \bar{x} + \alpha \bar{z} + \mu \bar{x}\bar{z} + \beta w\\ \end{aligned} \]
위의 네 시나리오에 따라서 우리는 \(\hat{y_1} - \hat{y_2}\)과 \(\hat{y_3}-\hat{y_4}\)를 계산해볼 수 있습니다.
\[ \begin{aligned} \hat{y_1} - \hat{y_2}& = (\hat{\gamma} + \hat{\eta} \underline{x} + \hat{\alpha} \underline{z} + \hat{\mu} \underline{x}\underline{z} + \hat{\beta} w) - (\hat{\gamma} + \hat{\eta} \bar{x} + \hat{\alpha} \underline{z} + \hat{\mu} \bar{x}\underline{z} + \hat{\beta} w)\\ & = \hat{\eta}(\underline{x} - \bar{x}) + \hat{\mu}(\underline{x}\underline{z} - \bar{x}\underline{z}) = \hat{\eta}(\underline{x} - \bar{x}) + \hat{\mu}\underline{z}(\underline{x} - \bar{x})\\ \hat{y_3} - \hat{y_4}& = (\hat{\gamma} + \hat{\eta} \underline{x} + \hat{\alpha} \bar{z} + \hat{\mu} \underline{x}\bar{z} + \hat{\beta} w) - (\hat{\gamma} + \hat{\eta} \bar{x} + \hat{\alpha} \bar{z} + \hat{\mu} \bar{x}\bar{z} + \hat{\beta} w)\\ & = \hat{\eta}(\underline{x} - \bar{x}) + \hat{\mu}(\underline{x}\bar{z} - \bar{x}\bar{z}) = \hat{\eta}(\underline{x} - \bar{x}) + \hat{\mu}\bar{z}(\underline{x} - \bar{x}) \end{aligned} \]
복잡해 보이지만 위의 식은 서로 상쇄되는 항들을 정리하면 다음과 같은 두 개의 식으로 다시 쓸 수 있습니다.
\[ \begin{aligned} \frac{\partial y}{\partial x} & \text{Given} \underline{z} = \hat{\eta} + \hat{\mu} \underline{z} \\ \frac{\partial y}{\partial x} & \text{Given} \bar{z} = \hat{\eta} + \hat{\mu} \bar{z} \end{aligned} \]
첫 번째 식, \(\hat{y}_1 - \hat{y}_2\)을 통해 우리는 \(z\)가 낮은 값으로 고정(통제)되어 있을 때의 \(y\)에 대한 \(x\)의 효과, 기울기를 구할 수 있습니다. 반대로 두 번째 식, \(\hat{y}_3 - \hat{y}_4\)를 이용해서 \(z\)가 높은 값으로 일정할 때, \(y\)에 대한 \(x\)의 효과를 추정할 수 있습니다. 실질적으로 데이터를 통해 구성한 위의 모델은
\[ \begin{aligned} \text{한 국가의 경제수준}&= \gamma + \eta \text{무역 개방성} + \alpha \text{해외직접투자 유입}\\ &+ \mu \text{무역 개방성}\times\text{해외직접투자 유입} + \beta \text{노동 가능인구} \end{aligned} \]
로 다시 쓸 수 있습니다. 따라서 위의 모델을 통해 저는 무역 개방성이 경제수준에 미치는 효과는 해외직접투자 유입 수준에 따라 조건적일 것이라고 기대한 모델을 구축한 것입니다.
하지만 해외직접투자 유입이 연속형 변수이기 때문에, 해외직접투자 유입이라는 조건 하에서 무역 개방성이 경제 수준에 미치는 한계효과를 포착하기란 쉽지 않습니다. 해외직접투자 유입이라는 변수의 값이 고정되어 있는 것이 아니라 변화하니까요. 그러므로 위에서는 해외직접투자의 유입에 관해 임의의 두 값, 최대값과 최소값을 설정함으로써 무역 개방성이 한 단위 증가할 때, 해외직접투자 유입의 최대값, 또는 최소값 하에서 경제수준에 미치는 한계효과를 계산하고자 한 것입니다. 만약 해외직접투자 유입의 최대-최소값으로 고정된 무역 개방성의 한계효과의 차이가 확실하게 보인다면, 이 모델을 통해 \(x\)와 \(z\), 무역 개방성과 해외직접투자 유입 간의 상호작용 효과가 존재한다고 말할 수 있습니다.3
- R에서는 이와 같은 상호작용의 효과를 직관적으로 이해할 수 있도록 그래프를 통해 보여주는 여러 패키지들을 제공합니다. 직접 계산해서
ggplot으로 그려주셔도 좋습니다. 저는 후자를 선호합니다만, 여기서는 간단하게 패키지를 이용하여 위의 분석을 그래프로 재현해보도록 하겠습니다.
library(margins)
library(interplot)
interplot(m = interactions,
var1 = "wdi_fdiin",
var2 = "wdi_trade") +
xlab("The level of FDI Inflow") +
ylab("Estimated Coefficient for Trade Openness") +
ggtitle("Estimated Coefficient of Trade Openness on
the Size of Economy by the Level of FDI Inflow") +
theme(plot.title = element_text(face="bold", size = 10)) +
geom_hline(yintercept = 0, linetype = "dashed")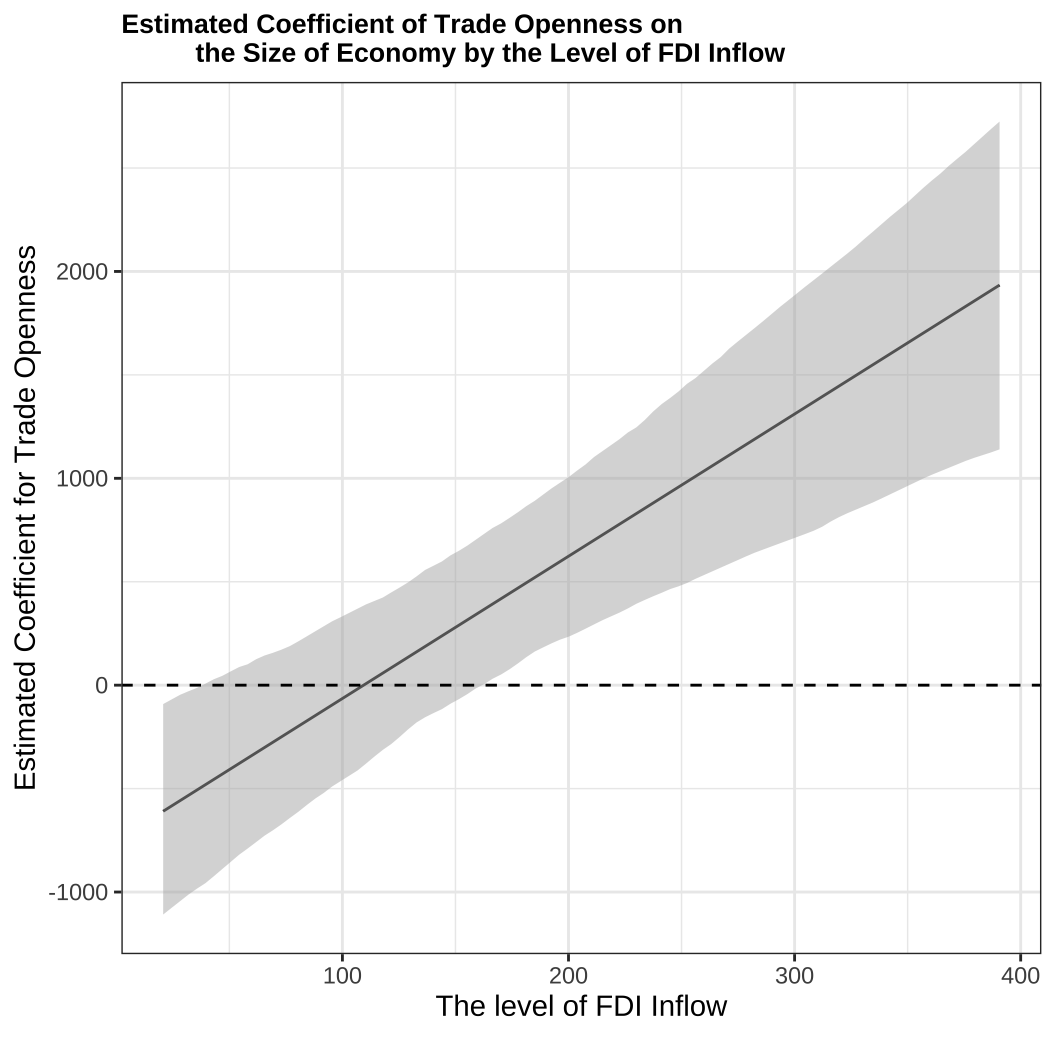
이 그래프는 해외직접투자 유입 수준이 증가할수록 무역 개방성이 경제수준(경제규모)에 미치는 효과가 증가한다는 것을 보여주고 있습니다. 위에서 계산한 것은 해외직접투자 유입이 최소값이었던, 위의 그래프에서 제일 좌측의 값과 해외직접투자 유입이 최대값이없던 최우측의 값이라고 이해할 수 있습니다.
소결: 상호작용과 가설검정
기초 통계학을 공부하셨다면, 선형회귀모델에서 계수값을 통해 우리가 가설을 검정하는 방식에 대해서 이미 알고 계실 것입니다. 우리는 모집단에서의 모수들의 관계를 추론하기 위해 표본의 통계치들 간의 관계를 가지고 그 관계가 확률적으로 얼마나 ‘오류가 날지’ 즉, 유의미하지 않은 관계일지를 통해 가설을 기각 혹은 기각하지 못합니다.
- 간단히 말하자면 표본은 본질적으로 모집단에서 추출해 모집단을 대표적으로 보여줄 것이라 기대되지만 표본추출의 방법 등에 내재된 한계로 인해 표본은 모집단과 동일할 수는 없습니다.
하나의 모집단에서 이론적으로 우리는 수없이 많은 표본들을 뽑아낼 수 있고, 이 표본들은 각각 평균과 같은 통계치를 가집니다. 따라서 우리는 표본들 통계치가 가지는 분포, 포집분포(sampling distribution) 등을 확인하게 되는 것이죠.
- 표본들이 문제없이 잘 뽑혔다면, 그리고 관측치의 수가 충분하다면 우리는 모집단의 기대값(expected value)이 표집분포의 평균에 수렴할 것이라고 기대하게 됩니다(중심극한정리).
하지만 어디까지나 표본은 모집단과 동일하지 않기 때문에 확률적으로 표본을 통해서 관측한 통계치들 간의 관계가 모집단에서 모수의 관계를 보여주지 못할 수도 있습니다. 보여주지 못할 확률이 우리가 설정한 어떠한 기준보다 클 경우 우리는 표본을 통해 분석한 결과가 통계적으로 유의미하지 않다(정확히는 유의미하다고 말하기 어렵다)고 결론을 내리게 됩니다. 이 점에서 선형회귀분석에서 \(x\)의 계수값 \(b_1\)은 모집단에서의 모수가 가지는 \(\beta_1\)를 보여줄 것이라는 기대를 가지고 있는 것입니다.
이때, 우리의 기대를 연구가설이라고 하면 이에 대한 영가설(null hypothesis)는 이러한 관계가 ‘존재하지 않을 것’, 즉 \(\beta_1 = 0\)이라고 할 수 있습니다.
선형회귀분석에서 계수의 효과와 가설검정의 관계는 전체 표본 중에서 얼마나 많은 표본들이 관측된 결과가 0, 즉 “효과 없음”이라고 나타나느냐에 달려있다고 볼 수 있습니다.
그렇다면 상호작용 효과는 어떨까요? \(y = \beta_0 + \beta_1 x + \beta_2 z + \beta_3 xz + \epsilon\)이라는 모형이 있다고 할 때, 과연 상호작용 효과에 관심이 있기 때문에 \(\beta_3\)에만 관심을 가지고 \(\beta3 = 0\)에 대한 영가설을 기각하면 될까요?
이것이 Brambor et al. (2006) 이 유의미한 한계효과와 표준오차를 계산해야 한다고 했던 이유이기도 합니다. 왜냐하면 단지 \(\beta_3 = 0\)에 대한 기각 여부는 상호작용 효과를 이해하는 데 실질적으로 도움이 되지 않기 때문입니다.
상호작용 효과는 편미분을 했을 때, \(\frac{\partial y}{\partial x} = b_1+ b_3 z\)로 나타낼 수 있고 따라서 우리는 \(\beta_3 = 0\)이냐가 아니라 \(b_1+ b_3 z = 0\)인지를 살펴보아야 하기 때문입니다.
\(z\)가 변수이므로 계속 변화하기 때문에 이 변화하는 \(b_1+ b_3 z\), 한계효과와 그 표준오차를 계산해 그것이 얼마나 효과 없음, 0에 수렴하는지 혹은 수렴하지 않는지를 살펴보아야 한다는 것이 Brambor et al. (2006) 의 핵심 주장입니다.
조금 더 나아가기: Hainmueller (2019)
2019년에 Political Analysis에 게재된 Hainmueller, Mummolo, and Xu의 논문, “How Much Should We Trust Estimates from Multiplicative Interaction Models? Simple Tools to Improve Empirical Practice”는 정치학 분야에서 흔히 사용하는 상호작용항을 다루는 방식에 대한 문제를 제시하고 있습니다. 동시에 Brambor et al. (2006) 에 대해서도 일종의 업데이트를 하고 있는 논문입니다. 한번쯤 꼭 읽어보시기를 권하고 여기서는 필요에 따라 간단하게 요약 및 정리하는 정도로 마무리하겠습니다.
Hainmueller et al. (2019)의 주장과 Brambor et al. (2006)에 대한 비판
Hainmueller (2019) 은 Brambor et al. (2006) 가 곱셈을 통해 나타나는 상호작용항을 탐색하고 해석하는데 있어서 일종의 가이드라인을 제공하고는 있지만 몇 가지 중요한 이슈들을 간과하거나 언급조차 하고 있지 않다고 비판합니다. Hainmueller (2019) 에 따르면 그 문제는 크게 두 가지로 대별할 수 있습니다. 첫째, 선형 상호작용(linear interaction effect; LIE)에 대한 가정과 둘째, 충분한 정보량의 결여에 관한 것입니다.
Brambor et al. (2006) 는 편미분을 취하는 방식을 통해서 상호작용항의 한계효과를 살펴보고 있습니다. 아래는 Hainmueller (2019, 166) 가 제시하고 있는 수식들로 고전적 선형회귀분석 모델에 곱셈 형태의 상호작용항이 포함된 모델을 보여줍니다.
\[ Y = \mu + \eta X + \alpha D + \beta(D\cdot X) + Z\gamma + \epsilon \]
이 모델에서 \(Y\)는 종속변수이고, \(D\)는 우리가 관심을 가지고 있는 핵심적인 예측변수, 혹은 처치변수입니다. \(X\)는 일종의 매개변수이고, \((D\cdot X)\)는 상호작용변수, \(Z\)는 일련의 통제변수들이라고 하겠습니다. \(\mu\), \(\epsilon\)은 각각 상수와 오차항을 보여줍니다. 이때, 핵심적인 예측변수 \(D\)의 종속변수 \(Y\)에 대한 한계효과는 다음과 같이 나타낼 수 있습니다.
\[ \text{ME}_\text{D} = \frac{\partial Y}{\partial D} = \alpha + \beta X \]
이 지점에서 Hainmueller (2019) 는 Brambor et al. (2006) 이 간과한 점이 있다고 지적합니다. Brambor et al. (2006) 의 논의에 따르면 우리는 단지 핵심 변수들의 한계효과가 일종의 선형 함수적 형태로 나타나리라고 가정해야 합니다. 그러나 Hainmueller (2019) 는 그 선형상호작용에 대한 가정은 결코 선험적인 것이 아니며 종종 유지되지도 않는다고 주장합니다. 따라서 Hainmueller (2019) 는 연구자들이 그들의 데이터를 한 번 더 살펴보고 한계효과를 진정 선형함수의 형태로 나타낼 수 있는지를 의심해보라고 주문합니다. Brambor et al. (2006) 이 묵시적으로 LIE를 가정하고 많은 학자들이 그 가이드라인을 그저 따른다고 할지라도 Hainmueller (2019) 는 LIE는 결코 선험적으로 정당화될 수 없는 가정이며, 이를 확인하기 위해서는 연구자가 가진 데이터를 더 깊이 들여다보고 이해하는 것이 필요하다고 지적합니다.
이이서 Hainmueller (2019) 는 충분한 정보량의 문제에 대해서 지적합니다. 이 문제는 상호작용항의 효과를 살펴볼 수 있는 데이터의 범주 전반에 걸쳐서 실상 우리가 관측할 수 있는 가용성의 문제와 직결됩니다. 다르게 표현하자면, 만약 우리가 매우 치우친 형태의 분포를 가진 데이터를 가지고 있다면 그 데이터에서 매개변수의 한 값에서 우리는 한계효과가 명확하게 존재한다고 할만한 충분한 정보를 얻지 못할 수도 있기 때문입니다. 수학적, 행렬적 계산으로 도출해서 예측값의 변화를 보여줄 수는 있지만 과연 그것이 실제로는 존재하지 않는 데이터의 구간을 수리적 계산으로 그릴 뿐이라면? 한계효과에 대한 주장의 타당성에 의문을 제기할 수 있다는 것입니다. Hainmueller (2019) 는 논문 165쪽에서 두 가지 조건에 대해 명시하고 있습니다: “(1) 주어진 매개변수의 값에 대해서 \(X\) 값이 충분한 수의 관측치를 가지고 있어야 하며, (2) 그 매개변수의 값에서 핵심적인 예측변수, \(D\)의 변화가 존재해야 한다는 것”입니다. 특히 때로 매우 치우치거나 값이 일정하게 분포되어 있지 않은 자료를 사용하는 사회과학연구에서 이같은 노력을 주문하고 있습니다.
만약 주어진 매개변수의 특정한 값에 실질적으로 핵심적인 예측변수의 관측치들이 없거나, 거의 존재하지 않는다면 우리는 충분한 정보없이 한계효과를 그저 추정하는 것이 되고, 이를 Hainmueller (2019, 165) 는 “함수적 형태의 외삽 또는 내삽의 문제”라고 언급하고 있습니다. 정리하자면, Hainmueller (2019) 의 두 가지 핵심적인 주장은 첫째, Brambor et al. (2006) 이 간과하거나 묵시적으로 가정하는 LIE의 문제를 고려할 것, (2) 상호작용 모델에 관한 이론적 이해와 우리가 사용하는 경험적 데이터 간의 간극을 좁힐 것으로 요약할 수 있습니다.
Hainmueller et al. (2019)의 대안
첫 번째 전략
Hainmueller (2019) 의 첫 번째 전략은 데이터가 LIE 가정을 충족시키는지를 진단해보자는 것입니다. 이들은 원 데이터의 산포도를 그려볼 것을 추천합니다. 그냥 추천하는게 아니라 한계효과의 LIE 가정과 매개변수의 각 데이터 포인트별 핵심 예측변수의 실제 관측치 분포를 살펴볼 수 있는 산포도를 그리는 방법을 제시합니다.
첫째, 핵심 예측변수가 이항변수일 경우, 핵심 예측변수에 따라 그래프를 두 개의 패널로 나눈 뒤 매개변수와 종속변수 간의 관계를 보여주는 산포도를 그려보라고 합니다.
둘째, 두 개의 선을 이 산포도에 더하는데, 하나는 상호작용 효과의 선형성을 가정하는 회귀선이고, 다른 하나는 일종의 가중치를 적용한 국소가중치 회귀선(locally weighted regression; LOESS)입니다.
예측변수의 값에 따라 나뉜 산포도의 각 패널에서 이 두 선을 비교함으로써, 우리는 LIE가 충족되는지 여부를 확인할 수 있습니다.
마지막으로 정보량의 문제에 있어서 Hainmueller (2019) 는 데이터에 충분한 관측치들이 존재하는지를 보여줄 수 있는 박스플롯을 제시하라고 제안합니다. 만약 핵심적인 예측변수가 연속형 변수라면 표본을 대강 비슷한 규모를 가진 세 개의 집단으로 분리하여 매개변수에 따라 낮은 수준의 \(X\) (first tercile), 중간 수준의 \(X\) (second tercile), 그리고 높은 수준의 \(X\) (third tercile)의 패널로 나타내라는 것입니다 (Hainmueller 2019, 170). 이산형 변수일 때와는 달리, 연속형 변수일 경우 우리는 \(Y\)에 대한 \(D\)의 관계가 이 세 집단의 매개변수 패널에서 회귀선과 LOESS곡선에 어떠한 차이를 보이는지를 살펴보라는 것입니다. 이를 통해 우리는 선의 기울기의 변화 또는 차이를 통해 \(Y\)에 대한 \(D\)의 관계가 서로 다른 수준의 \(X\)에 따라서 어떻게 달라지는지를 파악할 수 있게 됩니다.
두 번째 전략
두 번째 전략은 일종의 구간화를 통한 추정치(binning estimator)를 사용하라는 것입니다. 구간화는 매개변수의 특정 값의 구간을 포함하는 일련의 더미변수들을 말하는데, 얘를 들어 매개변수가 1부터 10까지라면 1부터 3까지 하나의 더미변수, 4부터 7까지 또 다른 하나의 더미변수, 그리고 나머지 값들을 마지막 더미변수 등에 담는 방식을 말합니다. 우리가 이항변수인 매개변수를 가지고 있다면, 한계효과를 계산하는 것은 쉽습니다. 0과 1을 각각 집어넣으면 되니까요. 하지만 연속형 매개변수를 가지고 있을 때는 특정한 매개변수의 값을 골라서 한계효과를 살펴보기가 쉽지 않고, 살펴본다 하더라도 정확한 변화를 잡아내기가 쉽지 않습니다. Hainmueller (2019) 는 매개변수를 크게 세 개의 구간으로 나누어서 더미변수의 형태를 취하게 하고 이를 통해 매개변수의 삼분위 범주값들을 보여주라고 제안합니다. 만약 핵심적인 예측변수가 각각의 구간화 변수와 상호작용한다면, 우리는 주어진 매개변수의 삼분위 구간에서 예측변수의 한계효과를 보여줄 수 있을 것입니다.
다음으로 각 구간화 변수를 대표할 수 있는 값을 특정하여 그 특정한 지점에서 예측변수의 효과를 평가하라고 제안합니다. 구간의 평균 혹은 중간값이 될 수 있겠죠? 마지막으로 Hainmueller (2019) 는 핵심 예측변수와 구간화 더미, 그리고 예측값에서 그 평가지점(아까 이야기한 구간화 변수를 대표할 수 있는 평균 혹은 중앙값과 같은 수치) 간 차이 간 상호작용 모델을 추정하라고 제안합니다. 일종의 3개 변수 상호작용인 것이죠: \(D \times X - x_j \times G_j\). 여기서 \(j\)는 각 구간화 변수를 의미합니다. Hainmueller (2019, 171-172) 에 따르면 LIE 가정이 충족되고 충분한 양의 데이터가 상호작용을 지지한다면, 구간화 추정치는 주어진 \(ME_X = \hat{\alpha} + \hat{\beta}X\)라는 한계효과로 나타나는 표준 상호작용 모델의 한계효과 불편추정값으로 수렴할 것입니다. 나아가 구간화 추정치는 매개변수의 값에 기초하여 구축된 것이니만큼 구간화를 이용해 추정된 조건적 한계효과는 외삽과 내삽의 문제에 크게 왜곡될 일이 없습니다. 즉, 가능한 한 많은 데이터를 이용해서 추정을 하게 된다는 것입니다.
구간화 추정치 그 자체는 한계효과가 선형인지에 대한 여부를 알려주지는 못합니다만, 이것을 가지고 우리는 그래프 등을 그려봄으로써 한계효과가 각 구간에서 일관된 선형 관계로 증가하는지 아니면 특정 구간에서 널뛰는지를 살펴볼 수 있습니다. Hainmueller (2019) 는 Figure 2와 Figure 4(b)를 통해 구간화 추정치를 통해 LIE 가정과 정보량의 문제도 함께 살펴볼 수 있다고 주장하고 있습니다.
간단한 정리
개념들의 유기적인 연결
이 통계적인 논리들은 개별적인 것같지만 모두 유기적으로 연결되어 있습니다. 한 가지 예제를 통해 앞서 살펴보았던 내용들을 간단히 정리하는 시간을 가져보고자 합니다. 여러분들이 야구 경기가 시작하기 전에 그 앞에 위치한 식당의 맥주 소비량이 암표 가격(black market tickets prices)에 미치는 영향이 있는지를 연구해본다고 합시다. 그리고 어떤 정보상이 이에 관한 다양한 데이터들을 판매하는데 단 한 가지만 살 수 있습니다.
첫째, 아마도 “영향”을 연구하고자 하기 때문에 우리는 주로 회귀모델에서 기울기 계수값이 얼마나 큰지에 관심을 가질 것입니다. 그렇다면 문제는 정보상에게 어떤 데이터셋을 구매하는 것이 최선인가 하는 것입니다. + 큰 기울기 계수값을 갖기 위해서는 얼마나 많은 설명변수들이 서로를 설명하는지(covary), 그리고 얼마나 각 설명변수가 고유한 종속변수에 대한 설명력을 가지는지를 알아야 합니다. 아무리 설명변수가 많더라도 설명변수들끼리 공분산이 크다면, 정작 종속변수를 설명하는 데 중첩되어 개별 설명변수가 큰 계수값을 가지기 어렵습니다.
둘째, 만약 계수값의 크기보다 작은 표준오차를 더 신경쓴다면 어떤 데이터가 필요할까요?
일단, 표준오차가 무엇인지에 대해서 다시 한 번 생각해봅시다.
이론적으로 우리는 관심을 가지고 있는 하나의 모집단으로부터 무한한 수의 표본들을 추출해낼 수 있습니다.
우리가 관심을 가지고 있는 것은 모집단 수준에서의 계수들, PRF의 계수들이지만 실제로 모집단은 관측할 수 없기에 우리는 관측가능한 표본들을 가지고 PRF에 대응하는 SRF를 구성해 PRF의 계수들을 추론하게 됩니다.
즉, 표본에 따라서 SRF에 따라 도출된 표본 통계치들은 다소 다르게 나타날 수 있습니다. 대표적으로 표집 방법 등과 같은 이유로 추출된 표본들이 완전히 동일할 가능성이 매우 낮기 때문입니다. 따라서 PRF는 특정한 값으로 정해져 있지만, 우리는 그것을 모르고 우리가 구한 SRF의 계수들이 그 PRF의 계수들, 모수(parameters)를 중심으로 분포하고 있다고 생각하게 됩니다.
이때, 서로 다른 표본들로부터 각기 얻은 일련의 계수들(a set of coefficients from different samples)이 분포를 이룬다고 할 때, 그 분포의 표준편차가 표준오차입니다.
표준오차는 우리의 SRF 계수값들이 실제 진실된 PRF의 모수값과 평균적으로 얼마나 떨어져있는지를 보여줍니다.
이 경우에는 표본의 크기에 대해 물어볼 필요가 있습니다. 표본의 크기가 커질수록 표준오차는 필연적으로 작아집니다. 또한 설명변수에 대한 전체 표본의 변화량(total sample variations)을 확인해보아야 합니다. \(x\)의 총 변화량이 커질수록, PRF의 \(x\)에 대한 \(\beta_1\)의 추정치 \(\hat{\beta_1}\)의 표준오차는 더 작아지게 됩니다.
셋째, 누군가가 “다중공선성(mulicollinearity)은 항상 나쁘다”라고 말했다고 합시다. 과연 그럴까요? 앞서 회귀모델의 가우스-마르코프 가정 중 우리는 “완벽한 다중공선성이 없어야 한다”는 내용이 있다는 것은 이미 알고 있습니다. 그렇다면, 우리는 다중공선성을 완벽하게 피할 수 있을까요?
다중공선성은 가급적 적을 수록 좋겠지만, 항상 나쁜 것은 아닙니다. Wooldridge (2016: 84)에 따르면 다중공선성은 “둘 이상의 설명변수들 간 높은(하지만 완벽하지는 않은) 상관관계”라고 정의됩니다. 만약 \(x_1\)과 \(x_2\)가 매우 상관되어 있다면, 이는 \(y\)를 설명하기 위한 \(x_1\)의 고유한 변량과 \(x_2\)의 고유한 변량이 작을 것이라는 점을 시사합니다.
보다 기술적으로 \(\hat{\beta_j}\)의 분산에 대해 생각해보겠습니다. 이후로는 \(VAR(\hat{\beta_j})\)라고 하겠습니다. \(VAR\)(\(\hat{\beta_j}\)는 \(\sigma^2/[SST_j(1-R^2_j)]\)로 나타낼 수 있습니다.
이때 분자는 예측변수들의 영향력을 제외한 \(y\)의 변량입니다. 따라서, 이는 오차의 분산이라고 할 수 있습니다.
분모는 다른 예측변수들의 변량을 포함하지 않은 순수한 각 설명변수의 고유한 분산입니다.
그러나 다중공선성은 항상 나쁘다고 하기에는 어려운 것이 우리는 어디까지나 예측변수들을 이론적 배경에 입각하여 선택하기 때문입니다. 만약 서로 다른 예측변수에 대한 구성개념들이 서로 다른 현상들을 차별적으로 보여준다고 한다면, 우리는 그 변수들이 매우 상관되어 있다고 하더라도 그것들을 제외하기 위해서는 타당한 이유를 갖추어야 합니다.
수적 공변(numerical covariation) 때문에 변수들 간 매우 높은 상관관계를 가질 수 있습니다만 그것이 반드시 나쁘다고 할 수는 없습니다. 단지 그러한 다중공선성이 높은 변수들을 포함한 모델이 설명력에 있어 “덜 유용하다”고 표현할 수 있을 따름입니다.
Goldberger는 이 다중공선성의 문제를 “과소표본크기(micronumerosity)”라는 개념으로 설명하고 있습니다.
우리가 다중공선성을 설명변수들 간 높은 상관성으로 정의한다고 할 때, 그 결과로 우리는 더 큰 표준오차를 가지게 되어 결과적으로 추정치의 편의(bias)를 의심해볼 수 있습니다.
그러나 Goldberger는 예측변수들이 매우 상관되어 있다면 그 표준오차는 반드시 크게 나타날 것이며, 큰 표준오차는 모델의 변수들 간의 관계가 매우 불확실하다는 것을 의미한다고 주장합니다.
즉, 설명변수들 간 상관계수가 높아질수록 우리는 변수들의 변화가 종속변수와 관계된 것인지 아닌지를 구별하기가 어려워집니다. 따라서 Goldberger는 과소표본크기라는 개념을 통해 이 문제가 “작은 표본”에 따른 것으로 봐야 한다고 봅니다.
과소표본크기의 맥락에서 보자면, 우리가 충분한 크기의 데이터를 가지지 않는다면 표준오차가 더 커질 것입니다. 예측변수들의 높은 상관관계는 각 예측변수들의 고유한 변량이 매우 작다는 것을 의미합니다. 이는 곧 종속변수를 설명할 변량—정보가 부족하다는 것과 상통합니다.
Footnotes
상호작용항을 곱셈으로 표현하는 것은 논리적 근거를 가지고 있습니다. 예를 들어, 부울리안(Boolean)은 ‘+’를 OR,’\(\times\)’를 AND로 표현하는데, 곱셈이란 두 조건이 동시에 존재하는 것을 의미합니다. 상호작용항 역시도 두 변수의 효과가 함께 종속변수에 영향을 미친다는 것을 보여주고자 하므로 곱셈의 형태로 나타냅니다.↩︎
다중공선성이라는 것이 변수들 간의 공변 양상(covariances)에 따라 나타나는 것이니만큼, 두 변수의 곱을 통해 만들어낸 상호작용항이 모델 전반의 다중공선성을 높일 것이라 예상하는 것은 어렵지 않습니다. 다만, 과연 다중공선성이 반드시 나쁘냐하는 것에 대해서는 고민해볼 필요가 있습니다.↩︎
여기서 한 가지 생각해보고 넘어가야할 것이 있습니다. 물론 상호작용 모델은 앞선 챕터들에서 보았던 가산적 관계의 선형회귀모델과는 다르게 두 변수 간의 상호작용을 모델에 반영하고 있습니다. 하지만 편미분을 통해 살펴본 결과는 상호작용 모델 역시 그 내부에 선형함수를 포함하고 있다는 것입니다. \(\frac{\partial y}{\partial x} = \beta_1 + \beta_3 z\)라는 결과는 결국 상호작용 관계도 \(z\)에 따라 선형으로 나열된다는 것입니다. 그렇다면 만약 상호작용 효과가 비선형 관계라면 어떻게 될까요? 이에 관한 부분은 뒤에 다루도록 하겠습니다. 상호작용항을 모델에 포함할 경우, 각 변수들의 독립성을 가정한 가산적 모델보다 상대적으로 다양한 분석을 수행할 수 있게 되는 것은 맞지만 어디까지나 상호작용항도 일련의 가정에 기초하고 있기에 만능은 아니라는 점을 알아두어야 합니다.↩︎