앞의 Chapter 3 에서는 ‘개체 간’ 비교로부터 도출되는 함수관계와 ‘개체 내’ 비교로부터 도출되는 함수관계가 동일하여 이 둘을 굳이 구별할 수가 없는 경우에 한정하여 살펴보았다. 이 장에서는 이 둘이 상이한 정보를 제공하는 경우에 대해서 살펴본다.
모형 \(y_{it} = X_{it}\beta + u_{it}\)에서 오차(\(u_{it}\))를 개별효과(\(\mu_i\))와 고유효과(\(\varepsilon_{it}\))로 구분하고 \(X_{it}\)가 \(\varepsilon_{it}\)에 대하여 강외생적이라고 가정할 경우1, ‘개체 간’ 함수관계와 ‘개체 내’ 함수관계를 다르게 만들어주는 것은 \(\mu_i\)의 역할이다.2 변수들 간에 \(y_{it} = X_{it}\beta + \mu_i + \varepsilon_{it}\) 관계가 성립하고, \(X_{it}\)가 \(\varepsilon_{it}\)에 대하여 강외생적이지만 \(\mu_i\)와는 아무렇게나 상관(횡단면 상관)될 수 있는 모형을 고정효과(fixed effects) 모형이라고 한다. 고정효과 모형에서 \(\beta\)는 설명변수가 고유오차에 대하여 강외생적이라는 가정에 의해서만 정의된다.
개체 간, 즉 집단간(between-group) 비교를 위하여, 우선 패널 데이터를 개체별 평균들의 횡단면 데이터로 축약하고, 이 축약한 횡단면 데이터를 이용하여 OLS를 하는 것을 집단간(between effect, BE) 회귀라고 한다.
집단내(within-group) 비교로부터 도출되는 함수관계도 존재한다.
고정효과 모형 \(y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}\)에서 이 함수관계를 표현하는 한 가지 방법은 \(E(y_{it}|X_{i1}, \dots, X_{iT}, \mu_i) = \alpha + X_{it}\beta + \mu_i\)이다.
즉, \(\mu_i\) 값이 동일하고 \(X_{it}\) 값에 차이가 있으면, \(X_{it}\times \beta\) 만큼 종속변수에 차이가 있을 것으로 기대된다.
\(\mu_i\) 값이 동일하게 고정된다는 의미는 동일한 집단에 속한 개체(고정효과를 공유하는)라는 의미로, 이 경우 종속변수의 차이는 집단내의 비교라고 할 수 있다.
이 모형이 Chapter 3 의 임의효과(random effects) 모형과 다른 점은, 설명변수들과 \(\mu_i\) 간의 상관관계에 대해 어떠한 제약도 가하지 않는다는 점이다.
Note
임의효과 모형에서는 \(X_{it}\)와 \(\mu_i\)가 서로 비상관이라는 가정한다. 고정효과 모형에서는 \(E(\mu_{i}|X_{i1}, \dots, X_{iT})\)가 \(X_{i1},\dots X_{iT}\)의 함수일 수 있기 때문에 \(E(y_{it}|X_{i1}, \dots, X_{iT}) = \alpha + X_{it}\beta\)라고 표현할 수 없다 (한치록 2021: 66).
고정효과 모형에서 계수의 추정을 위해서는 POLS나 RE 추정의 방법을 사용할 수 없다. 왜냐하면 설면변수가 개별효과를 통하여 오차항과 상관되기 때문이다(♔). 즉, 내생성의 문제가 제기된다.
한 가지 해결 방법은 모델을 바꾸어 문제가 되는 \(\mu_i\)를 제거하는 것이다. 간단한 방법으로는 모델을 1계차분(first difference)하는 것이다 (3.3절).
1계차분보다 더 자주 사용되는 방법은 집단내(within-group) 편차를 구하는 변환을 한 것이다 (3.4절).
한편, 고정효과 모형 \(y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}\)에서 \(\mu_i\)들을 고정된 모수로 취급하고 우변에 개체 더미변수들을 모조리 추정하는 방법이 있다.3 이를 더미변수 최소제곱(least squares dummy variables, LSDV) 회귀라고 한다 (3.5절).
3.6절에서는 BE 추정값과 FE 추정값을 정확하게 해석하는 방법에 대하여 살펴본다. 한치록 (2021, 67)은 특히 이 3.6절을 주의하여 살펴볼 것을 주문하고 있다. 3.7절에서는 상관된 임의효과 접근법을 강외생성 하 선형 패널모형에 적용할 때 발생하는 일에 대하여 설명한다.
FE 회귀는 변수들의 집단간 수준 차이를 무시하므로, 집단간 차이를 이용하는 RE 추정량보다 효율성이 떨어지는 경우가 많다. 만약 개별효과 \(\mu_i\)가 임의효과이면 RE 추정량과 FE 추정량 간 체계적인 차이가 없으므로, RE 회귀를 하여 FE 모형의 계수들을 추정할 수 있다. 3.8절에서는 개별효과가 고정효과인지 임의효과인지를 검정하는 방법을 설명한다.
마지막으로 3.9절에서는 Hausman and Taylor (1981) 가 제시한 일반적인 모형을 살펴본다. 이 모형에는 시간에 따라 변화하는(time-varying) 설명변수 (\(X_{it}\))와 시간불변(time-invariant)의 설명변수 (\(Z_{i}\))가 모두 존재하고, \(X_{it}\)와 \(Z_{i}\)의 일부는 \(\mu_i\)와 상관되고 나머지는 상관되지 않는다. 이 모델에서는 \(\mu_i\)와 상관되지 않은 변수들을 적절히 도구변수로 활용하게 된다.
3.1 집단간 회귀
패널 데이터의 분석에서 개체들 간의 횡단면 함수관계를 측정하기 위해서는 집단간(between effect, BE) 회귀를 사용한다.
패널 데이터에서 시간에 걸친 변동으로부터 오는 정보는 무시하고 개체 간 차이로부터 오는 정보만 이용한다.
연도의 효과는 무시하고 국가 간 차이로부터 오는 정보만 이용한다는 것이다.
R에서 BE 회귀는 다음과 같이 한다: plm::plm(y ~ x1 + x2, data = sample, model = "between", index = c("id", "year"))
model = "between 옵션이 BE 회귀를 하도록 해준다. \(\bar{y_i} = \bar{X}_i\beta + \bar{u}_i\)이므로, BE 회귀에서 얻는 오차 분산 추정량은 \(\bar{u}_i\)의 분산 추정량이다.
패널 데이터 \(y_{it}\)와 \(X_{it}\)가 있을 때, BE 회귀는 \(\bar{y}_i\)를 \(\bar{X}_i\)에 대하여 OLS 회귀를 하는 것이다.
패널 데이터 내 개체들이 서로 간에(\(i\) 간에) 독립인 상황에서, \(\mathrm{E}(\bar{y}_i|\bar{X}_i)=\bar{X}_i\beta_{be}\)가 어떤 \(\beta_{be}\)에 대하여 성립한다고 하자.
“{X}_i가 \(\Delta x\)만큼 높은 개체의 경우, \(\bar{y}_i\)가 (\(\Delta x\))\(\beta_{be}\)만큼 높을 것으로 기대된다”고 횡단면 분석결과와 같이 해석할 수 있다.
즉, plm::plm(y ~ x1 + x2, data = sample, model = "between", index = c("id", "year"))라고 하면, “(x2를 통제한 후) x1의 전체 기간 평균값이 한 단위 더 큰 개체의 y값이 \(\hat{\beta}_{be}\) 정도만큼 더 큰 것으로 나타난다”고 해석할 수 있는 것이다.
BE 회귀는 개체 간 비교를 하는 것이기 때문에 BE 회귀 결과로부터 한 개체 내에서의 변화를 언급할 수는 없다.
Note
예제 3.1. 정규적과 비정규직의 임금 비교 (BE 추정)
예제 2.1의 임금방정식 예제에 대하여 연도별 더미 as.factor(year)를 제거하고 BE 회귀를 하면 다음과 같은 결과를 얻게 된다.
pacman::p_load(tidyverse, ezpickr, texreg)klipsbal<-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/klipsbal.dta")panel_be<-plm::plm(lwage~educ+tenure+I(tenure^2)+isregul+female+age05+I(age05^2), data =klipsbal, model ="between", index =c("pid", "year"))summary(panel_be)
Oneway (individual) effect Between Model
Call:
plm::plm(formula = lwage ~ educ + tenure + I(tenure^2) + isregul +
female + age05 + I(age05^2), data = klipsbal, model = "between",
index = c("pid", "year"))
Balanced Panel: n = 836, T = 11, N = 9196
Observations used in estimation: 836
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-1.3900530 -0.1889443 0.0090814 0.1973073 0.9757359
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 3.20116276 0.19035071 16.8172 < 2.2e-16 ***
educ 0.05226946 0.00427051 12.2396 < 2.2e-16 ***
tenure 0.04039986 0.00485983 8.3130 3.807e-16 ***
I(tenure^2) -0.00062317 0.00015474 -4.0273 6.160e-05 ***
isregul 0.33152974 0.03450828 9.6073 < 2.2e-16 ***
female -0.38241096 0.02348276 -16.2848 < 2.2e-16 ***
age05 0.06151601 0.00884234 6.9570 7.064e-12 ***
I(age05^2) -0.00083734 0.00010509 -7.9676 5.343e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Total Sum of Squares: 225.39
Residual Sum of Squares: 74.813
R-Squared: 0.66807
Adj. R-Squared: 0.66527
F-statistic: 238.074 on 7 and 828 DF, p-value: < 2.22e-16
정규직 여부를 나타내는 isregul의 계수 추정값은 0.332으로, Chapter 2 에서의 POLS 추정값 (약 0.272)이나 RE 추정값 (약 0.146) 보다 훨씬 크다. 다른 요인들을 통제한 후, 전체 기간 정규직이었던 노동자(isregul = 1)와 전체 기간 비정규직이었던 노동자(isregul = 0)를 비교하면, 전체 기간 정규직이었던 노동자의 임금이 전체 기간 비정규직이었던 비교 대상 노동자에 비해 평균 약 39.3% 높았다.
예제 3.1의 회귀식은 기간별 더미변수를 포함하지 않는다.
왜냐하면 시간을 무시하고 개체 단위로 평균을 구해서 횡단면 분석과 같이 취급하기 때문이다.
균형패널일 경우 모든 \(i\)에서 각각의 시간더미가 딱 한 번 1의 값을 가지므로 모든 시간더미들의 \(t\)에 걸친 평균은 \(1/T\)로 동일하고, 이는 시간더미들의 개체별 표본평균이 상수항과 완전한 공선성(collinearity)을 가지기 때문이다.
Note
연습 3.1. 예제 3.1의 모형에 시간더미 변수들(as.factor(year))을 추가하고 BE 회귀를 하여, 시간더미 변수들이 어떻게 되는지 확인하라.
Ans: 시간 더미들이 분석 결과에서 모두 제외되는 것을 확인할 수 있다.
panel_be_time<-plm::plm(lwage~educ+tenure+I(tenure^2)+isregul+female+age05+I(age05^2)+as.factor(year), data =klipsbal, model ="between", index =c("pid", "year"))summary(panel_be_time)
Oneway (individual) effect Between Model
Call:
plm::plm(formula = lwage ~ educ + tenure + I(tenure^2) + isregul +
female + age05 + I(age05^2) + as.factor(year), data = klipsbal,
model = "between", index = c("pid", "year"))
Balanced Panel: n = 836, T = 11, N = 9196
Observations used in estimation: 836
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-1.3900530 -0.1889443 0.0090814 0.1973073 0.9757359
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 3.20116276 0.19035071 16.8172 < 2.2e-16 ***
educ 0.05226946 0.00427051 12.2396 < 2.2e-16 ***
tenure 0.04039986 0.00485983 8.3130 3.807e-16 ***
I(tenure^2) -0.00062317 0.00015474 -4.0273 6.160e-05 ***
isregul 0.33152974 0.03450828 9.6073 < 2.2e-16 ***
female -0.38241096 0.02348276 -16.2848 < 2.2e-16 ***
age05 0.06151601 0.00884234 6.9570 7.064e-12 ***
I(age05^2) -0.00083734 0.00010509 -7.9676 5.343e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Total Sum of Squares: 225.39
Residual Sum of Squares: 74.813
R-Squared: 0.66807
Adj. R-Squared: 0.66527
F-statistic: 238.074 on 7 and 828 DF, p-value: < 2.22e-16
한치록 (2021, 69–73)에서는 BE 회귀를 수동으로 구해보는데, 이 부분은 굳이 해보지 않아도 될 것 같다. 앞에서 균형패널의 경우 BE 회귀에 시간더미들을 포함시키면 공선성으로 인해 시간더미들이 제외된다고 하였다. 불균형패널의 경우에는 이와 달리 완전한 공선성이 일어나지 않아, 살아남은 시간더미에 대해서는 추정값이 계쇤단다.
BE 추정 자체가 패널 데이터에 개체별 평균을 취함으로써 횡단면 데이터를 만들어 분석하는 것이기는 하지만, 변수들에 시간 추세가 존재하는 경우에는 관측 시점이 상이함으로 인해 절편이 상이해지는 일이 발생하고, 우변에 시간더미들(as.factor(year))을 포함시키면 이 문제가 해결된다.
Tip
불균형패널 데이터가 있을 때 BE 회귀 시 시간더미들을 우변에 포함시킨다는 것은 개체별로 관측시점이 상이함으로 인한 차이를 해당 시간더미들로 통제한다는 것을 의미한다.
5년 시차, 10년 시차 간격으로 평균을 구해서 회귀분석을 수행하는 것처럼, BE 회귀를 하는 것은 각 개체의 특성이 시간에 걸친 평균에 의하여 좀 더 정확히 계측된다는 믿음 때문으로 보인다 (한치록 2021: 74).
3.1.1 BE 회귀와 POLS 회귀의 비교
모형 \(y_{it}=X_{it}\beta + u_{it}\)에서 BE 회귀와 POLS 간의 관계를 살펴보자. \(X_{it}\)가 \(u_{it}\)에 대하여 강외생적이면 양자 모두 \(\beta\)를 일관되게 추정한다. \(X_{it}\)와 \(u_{it}\)가 상관되는 경우에는 두 모델의 추정량이 \(\beta\)와 다른 모수를 추정한다.
BE 회귀: \(\bar{y}_i\)와 \(\bar{X}_i\)의 평균적인 함수관계를 추정
독립변수의 전체 기간 표본평균 수준에 차이가 있는 개체들 간에 종속변수의 전체 기간 표본평균 수준에 평균 얼마나 차이가 있는지를 나타낸다.
POLS 회귀: 각 \(t\)에서 \(\mathrm{E}(y_{it}|X_{it})=X_{it}\beta_{pols}\)가 성립한다고 할 때의 계수를 추정
각 시점에서 개체 간 독립변수의 차이가 종속변수에 평균 어느 정도의 차이를 야기하는지 나타낸다.
만약 그 정도가 \(t\)마다 다르다면 각 \(t\)에서의 계수들을 가중평균한 값이 POLS에 의해 추정된다.
이 두 회귀가 추정하는 모수들은 같을 수도 있지만, 다를 수도 있다.
심지어 각각의 \(t\)에서 OLS가 추정하는 모든 횡단면 함수관계가 동일한 경우에도 \(X_{it}\)가 \(u_{it}\)에 대하여 강외생적이지 않을 때, POLS와 BE 회귀가 서로 다른 모수를 추정할 수 있다.
Tip
BE와 POLS 중 무엇이 집단간 차이에 기반한 횡단면 함수관계를 더 잘 표현하는가에 대해 한치록 (2021, 76)은 BE 추정량의 손을 들고 있다. 하지만 이 결과는 선택의 문제이며 해석의 문제라고 언급하고 있다.
Note
연습 3.4 \(y_{it}=X_{it}\beta + \mu_i + \varepsilon_{it}\)라는 모형에서 \(X_{it}\)가 고유오차(\(\varepsilon_{it}\))에 대해서 강외생적이라고 하자. \(T>1\)이면 어느 경우에 BE 추정량과 POLS 추정량의 확률극한이 동일한가?
Ans: 모든 시점(\(t\))에서 \(X_{it}\)가 고유오차(\(\varepsilon_{it}\))에 대해 강외생적일 경우, 두 모델의 추정량의 확률극한이 동일하다고 할 수 있다.
3.1.2 가중 BE 회귀
BE 회귀는 \(i\)마다 변수당 하나의 관측치를 만들어 횡단면 OLS 추정을 하는 것이다. 그런데 불균형패널의 경우 관측이 이루어진 기간 수가 \(i\) 별로 상이할 수 있다(불균형 패널). 이때, 관측 연도의 길이(\(T_i\))에 따라 가중치를 주고 BE 회귀를 하는 방법이 있다. 이를 가중 BE 회귀라고 한다.
STATA에서는 별도의 옵션으로 쉽게 구할 수 있는 듯 한데, R의 plm에서는 해당 옵션을 찾기가 어려워서 그냥 클러스터 가중치로 estimatr의 lm_robust 함수로 구했다. 단 이 경우, 견고한(클러스터) 표준오차를 구하기 때문에 STATA에서의 xtreg y x1 x2, be wls 신택스로 구한 결과와 표준오차에서 차이가 있다.
모형 \(\ref{eq-ch3-4}\)의 \(X_{it}\)에는 통상적으로 시간더미들이 포함되지만 연구자의 재량에 의해 제외될 수 있다. 고유오차 \(\varepsilon_{it}\)는 설명변수와 전적으로 무관하다(강외생적)고 하였으므로 무시하고, 개별효과 \(\mu_i\)가 고정효과라는 점에 집중해보자.
\(\mu_i\)와 설명변수가 상관될 수 있으므로, \(\mu_i\)를 오차의 일부로 간주한다면 설명변수와 오차항이 상관되어 \(\beta\)에 대한 비편향 추정량을 구하기 어렵다(♔).
특히, POLS나 RE 추정량은 모두 편향된다.
위의 식에서 \(alpha + \mu_i\)가 개체별 절편이므로 \(n-1\)개의 개체별 더미변수를 포함시켜 추정하는 것을 생각해볼 수 있지만, \(\mu_i\)가 따름모수이므로 그 통계적 특성을 알기 위해서는 수식을 모두 뜯어 살펴보아야 한다. 따라서 여기서는 1차적으로 따름모수들을 제거하고 나서 추정을 하는 방법을 생각해본다.
논의의 진행을 위해서 모델 \(\ref{eq-ch3-4}\)에서 \(Z_i \gamma\) 부분을 제거한 모형을 살펴볼 것이다.
\(Z_i \gamma\) 부분을 제거한 것은 \(\mu_i\)에 아무런 제약도 없을 때, 둘 사이를 서로 구별할 수 없기 때문이다. \(T\)가 짦은 상황을 고려하므로 시간더미들이 \(X_{it}\)에 포함되어 있다고 해도 좋다. 중요한 것은 \(X_{it}\)에 시간에 따라 변화하는 변수들만 존재한다는 것이다.
\(\alpha\)인 절편, 상수항은 시간에 걸쳐 불변이다.
관측불가능한 \(\mu_i\)는 설명변수들과 상관될 수 있다는 점에서 골칫거리이다. 고정효과 추정의 핵심은\(\mu_i\)를 모형으로부터 제거하여 따름모수와 내생성 문제를 해결하고 \(\beta\)에 대한 일관된 추정을 하는 것이다.
\(\mu_i\)를 소거할 때, 모든 시간불변 변수들도 함께 소거되므로, 추가적인 가정 없이는 성별 더미나 인종 더미와 같은 시간불변 설명변수들(\(Z_i\))의 계수를 추정할 수 없다.
개별효과 \(\mu_i\)가 독립변수 \(X_{it}\)와 상관된다고 할 때, 변수들의 시간에 걸친 차이를 보면 \(\mu_i\)가 시간에 따라 변화하지 않으므로, 동일한 \(i\) 내에서 특정 시점에 \(X_{it}\)의 값이 상대적으로 크다고 해도 해당 시점의 \(\mu_i\)의 값은 다른 시점에 비하여 클 수 없다. 따라서 동일 개체 내에서 시간에 걸친 변동의 측면을 고려하면 개별효과는 독립변수와 상관관계를 가질 수 없다. 그러므로 \(\mu_i\)와 \(X_{it}\) 간 양의 상관이 있다는 것은 \(\mu_i\)가 큰 개체에서 \(X_{it}\) 값의 수준도 대체로 크다는 의미를 갖는다. 그래서 \(\mu_i\)가 고정효과라고 하면 보통 \(\mu_i\)와 \(X_{it}\) 수준 간 횡단면 상관관계를 갖는다는 것으로 해석할 수 있다.
고정효과 모형에서 상이항 개체들 간 종속변수(\(y_{it}\))에 수준 차이가 있으면 이것이 독립변수(\(X_{it}\)) 수준 차이로 인한 것인지 개별효과(\(\mu_i\))로 인한 것인지 알 수 없다. 반면, 동일한 개체 내에서 종속변수 값이 시간에 따라 다르면 이로부터 독립변수와 종속변수의 관계에 대해서 유추할 수 있다. 따라서 상이한 시점 간 차이로부터 독립변수 차이로 인한 효과를 식별해 내는 것이 고정효과 모형의 분석에서 중요하다.
3.2.1 고정효과 모형에서 계수의 해석
고정효과 모형에서는 설명변수와 \(mu_i\)가 상관될 수 있다. 이때, \(\beta\)는 \(\mu_i\)가 동일한 상태에서 설명변수 값에 차이가 있을 경우, 종속변수에 평균적으로 어떠한 차이가 있는지를 나타낸다.
모든 개체들이 서로 독립일 때, \(\mathrm{E}(y_{it}|X_{i1},\dots,X_{iT}, \mu_i) = \alpha + X_{it}\beta + \mu_i\)
이는 모집단의 평균에 관한(PA) 모형이 아니라 개별 주체에 관한(SS) 모형의 일종이다.
\(j\)번째 설명변수의 계수 \(\beta_j\)는 “다른 설명변수 값들과 \(\mu_i\)가 동일하고 \(j\)번째 설명변수 값에만 한 단위 차이가 있을 때 종속변수 값에 존재할 것으로 기대되는 차이”를 의미한다.
중요한 것은 \(\mu_i\)가 통제된다는 것이다.
동일 개체 내에서 시간에 걸친 비교가 이루어질 때에는 \(\mu_i\)가 고정된다. \(\mu_i\)는 개체에 따라서만 변화하지 시간에 따라서는 변화하지 않기 때문이다.
상이한 개체에서 \(\mu_i\)가 동일한 경우를 상상하기는 어려우므로, 설명변수 값에 \(\Delta x\)만큼의 차이가 있을 때, \((\Delta x)\beta\)는 보통 “동일한 개체 내에서 상이한 시점 간에 독립변수들이 \(\Delta x\)의 차이가 있을 때 종속변수 값에 있을 것으로 기대되는 차이”로 해석한다.
고정효과를 갖는 모형에서는 고정효과를 명시적으로 통제한다.
모수는 집단내(within) 비교를 통하여 측정하는 효과와 동의어로 간주된다.
3.3 1계차분 회귀
고정효과를 갖는 모형 \(\ref{eq-ch3-5}\)의 \(\beta\) 계수를 추정하는 가장 간단한 방법은 모형 \(\ref{eq-ch3-5}\)의 양변에 \(t-1\) 시점으로부터 \(t\) 시점으로의 증가분을 구하는 것이다. 시차에 따른 증가분을 살펴보게 되면, 시간에 따라 변화하지 않는 요인들은 0으로 상쇄되어 사라지게 된다.
여기서 \(\Delta\)는 \(\Delta y_{it} = y_{it} - y_{it-1}\) 등 시차에 따른 증가분을 의미한다.
식 \(\ref{eq-ch3-5}\)와 \(\ref{eq-ch3-6}\)을 비교해보면 \(\alpha, \mu_i\)가 소거된 것을 확인할 수 있다. 이들은 시간에 따라 변화하는 요인이 아니기 때문이다.
모형 \(\ref{eq-ch3-5}\)에서 \(X_{it}\)가 \(\varepsilon_{it}\)에 대해서 강외생적이라고 하였으므로, 식 \(\ref{eq-ch3-6}\)의 \(\Delta X_{it}\beta, \Delta\varepsilon_{it}\)도 서로 독립적이다.
또 \(\ref{eq-ch3-6}\)의 모수로는 \(\beta\)만 존재하며, 따름모수(incidental parameters)가 존재하지 않는다.
그러므로 설명변수가 고유오차에 대해 강외생적일 때, \(\Delta y_{it}\)를 \(\Delta X_{it}\)에 대하여 POLS 회귀하면, \(\beta\)가 일관되게 추정될 것이라 기대할 수 있다(♔). 식 \(\ref{eq-ch3-6}\)에 대한 POLS 회귀를 1계차분(first difference, FD) 회귀라고 한다.
FD 추정값을 \(\hat{\beta}_{fd}\)라고 하자. FD 추정량은 차분방정식 \(\ref{eq-ch3-6}\)을 추정한 것이므로 있는 그대로 해석하면 “\(X_{it}\)의 증가폭이 d만큼 더 크면 \(y_{it}\)의 증가폭은 \(d\hat{\beta}_{fd}\)만큼 더 클 것이다”라고 할 수 있고, 이때 ’증가폭의 차이’로 해석되지만 \(\ref{eq-ch3-6}\)에 근거할 필요 없이 원래의 모형 \(\ref{eq-ch3-5}\)에 의거해 “동일 개체 내에서 설명변수 값에 \(\Delta x\)만큼의 차이가 있으면 종속변수 값에 \((\Delta x)\hat{\beta}_{fd}\)”만큼의 평균적인 차이가 있는 것으로 추정된다”고 해석해도 좋다.
설명변수가 고유오차에 대하여 강외생적이면 설명변수의 시간에 따른 변화분(\(\Delta X_{it}\))과 고유오차의 시간에 따른 변화분(\(\Delta\varepsilon_{it}\))이 비상관이므로 FD 추정량은 일관적(consistent)이다(♔). 하지만 \(\Delta\varepsilon_{it}\)에 시간에 걸친 상관이 존재하는 것이 일반적이므로 견고한 표준오차를 사용할 필요가 있다(♖). 간단한 방법은 클러스터 표준오차를 사용하는 것이다. R에서는 dplyr 패키지에서 lag 함수를 이용해서 차분을 한 뒤 개체에 따른 클러스터 표준오차를 계산하면 된다.
먼저 id 단위로 묶어준 다음에 각 변수의 시간변수에 따른 차분 변수를 만들어주는 것이다. 예를 들어, 종속변수의 차분변수를 만들어준다면 다음과 같이 만들 수 있다: data |> group_by(id) |> mutate(d_y = y - lag(y, n = 1, order_by = year) -> data. 모든 변수에 차분을 수행한 다음, 그 변수들을 이용해서 estimatr 패키지의 lm_robust 함수를 이용해 로버트스 회귀분석을 통해 클러스터 표준오차를 구할 수 있다. model <- lm_robust(d_y ~ d_x1 + d_x2 + as.factor(year), data = data, clusters = id).
POLS에서 클러스터 표준오차를 사용한 것처럼 id를 기준으로 클러스터 표준오차를 사용하는 것이 중요하다. 이 경우에도 클러스터의 개수가 어느 정도 커야만 클러스터 표준오차의 사용이 정당화된다.
Tip
시간더미들이 없는 모형에서는 1계차분에 의하여 절편이 소거된다(시간에 따라 변화하지 않으니까). 1계차분했을 때 절편이 존재하는 모형은 시간더미들이 있거나 아니면 \(y_{it} = \alpha + X_{it}\beta + \gamma_t + \mu_i + \varepsilon_{it}\)처럼 선형추세가 있는 모형이다 (한치록 2021: 82).
고정효과를 갖는 패널 모형에서 개체 간 차이를 단순비교하면 종속변수 값의 차이가 독립변수 값의 차이에 기인하는지 아니면 개별효과의 차이로 인한 것인지 불분명하다. FD회귀에서는 1계차분을 이용하여 개체별 특수성을 제거해버리므로 종속변수 값의 평균적인 차이는 오로지 독립변수 값의 차이에 기인한다고 할 수 있다. 이로써 독립변수가 종속변수에 미치는 영향을 식별할 수 있다.
Note
예제 3.4 인구구조와 총저축률(FD 추정)
예제 2.5의 데이터와 모형에 대하여 FD 추정을 한 결과는 다음과 같다.
pacman::p_load(plm, texreg, estimatr, ezpickr, tidyverse)wdi5bal<-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/wdi5bal.dta")wdi5bal|>group_by(id)|>mutate( d_sav =sav-dplyr::lag(sav, n =1, order_by =year), d_age0_19 =age0_19-dplyr::lag(age0_19, n =1, order_by =year), d_age20_29 =age20_29-dplyr::lag(age20_29, n =1, order_by =year), d_age65over =age65over-dplyr::lag(age65over, n =1, order_by =year), d_lifeexp =lifeexp-dplyr::lag(lifeexp, n =1, order_by =year))|>dplyr::select(id, year, contains("d_"))->d_wdi5balpanel_fd<-lm_robust(d_sav~d_age0_19+d_age20_29+d_age65over+d_lifeexp+as.factor(year), data =d_wdi5bal|>drop_na(), clusters =id)panel_fd|>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)
클러스터 표준오차를 사용함에 유의하라. RE 회귀와 비교하면, 우선 계수들에 약간씩 차이가 있고, lifeexp 변수의 \(p\)-값이 증가하여 통계적 유의성이 낮아졌다. FD 회귀의 \(R^2\)는 0.06 로 모형의 설명력이 매우 낮다(\(\Delta y_{it}\)의 변화량을 \(\Delta X_{it}\)가 설명하는 정도를 나타내는 것으로 약 5.6% 만의 변동을 설명한다는 것이다). lifeexp 변수의 계수추정값인 0.435은 한 나라의 인구구조(설명변수로 포함된 다른 변수들)이 일정할 때, 기대수명이 1세 차이나는 시기들 간 저축률에 약 0.4% 포인트 차이가 있다고 해석된다.
고정효과 모형에서 시간불변 변수들의 효과는 고정효과와 구별되지 않는다. 때문에 고정효과 모형에서는 시간에 따라 변화하는 설명변수들만 우변에 포함된다. 만약 시간불변 설명변수들을 우변에 포함시키고 FD 추정을 하면, 시간에 따른 변화가 존재하지 않기 때문에 증가분이 0이므로 해당 변수들은 모두 소거되고 추정값이 계산되지 않는다. 다음의 예제를 보자.
Note
예제 3.5 정규적 전환 효과의 FD 추정
임금방정식 모형에 시간더미를 포함시키고 FD 추정을 하자.
klipsbal<-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/klipsbal.dta")klipsbal|>group_by(pid)|>mutate( d_lwage =lwage-dplyr::lag(lwage, n =1, order_by =year), d_educ =educ-dplyr::lag(educ, n =1, order_by =year), d_tenure =tenure-dplyr::lag(tenure, n =1, order_by =year), d_isregul =isregul-dplyr::lag(isregul, n =1, order_by =year), d_female =female-dplyr::lag(female, n =1, order_by =year), d_age05 =age05-dplyr::lag(age05, n =1, order_by =year),)|>dplyr::select(pid, year, contains("d_"))->d_klipsbalpanel_fd_klipsbal<-lm_robust(d_lwage~d_educ+d_tenure+I(d_tenure^2)+d_isregul+d_female+d_age05+I(d_age05^2)+as.factor(year), data =d_klipsbal|>drop_na(), clusters =pid)summary(panel_fd_klipsbal)
Call:
lm_robust(formula = d_lwage ~ d_educ + d_tenure + I(d_tenure^2) +
d_isregul + d_female + d_age05 + I(d_age05^2) + as.factor(year),
data = drop_na(d_klipsbal), clusters = pid)
Standard error type: CR2
Coefficients: (3 not defined because the design matrix is rank deficient)
Estimate Std. Error t value Pr(>|t|) CI Lower
(Intercept) 0.0673433 0.0099318 6.78057 2.380e-11 0.0478467
d_educ 0.0483303 0.0225190 2.14620 7.401e-02 -0.0063365
d_tenure 0.0016742 0.0038224 0.43799 6.651e-01 -0.0061958
I(d_tenure^2) -0.0002138 0.0001843 -1.15962 2.651e-01 -0.0006081
d_isregul 0.0863623 0.0238849 3.61577 3.961e-04 0.0392074
d_female NA NA NA NA NA
d_age05 NA NA NA NA NA
I(d_age05^2) NA NA NA NA NA
as.factor(year)2007 -0.0012059 0.0168117 -0.07173 9.428e-01 -0.0342042
as.factor(year)2008 -0.0029468 0.0130056 -0.22658 8.208e-01 -0.0284743
as.factor(year)2009 -0.0503641 0.0132687 -3.79571 1.579e-04 -0.0764080
as.factor(year)2010 -0.0122221 0.0122891 -0.99454 3.202e-01 -0.0363434
as.factor(year)2011 -0.0083206 0.0123358 -0.67451 5.002e-01 -0.0325334
as.factor(year)2012 -0.0204074 0.0116567 -1.75071 8.036e-02 -0.0432872
as.factor(year)2013 -0.0150590 0.0123299 -1.22134 2.223e-01 -0.0392603
as.factor(year)2014 -0.0450831 0.0116767 -3.86094 1.217e-04 -0.0680023
as.factor(year)2015 -0.0319196 0.0127893 -2.49581 1.276e-02 -0.0570225
CI Upper DF
(Intercept) 0.0868398 771.833
d_educ 0.1029972 6.203
d_tenure 0.0095441 25.154
I(d_tenure^2) 0.0001806 14.410
d_isregul 0.1335172 167.205
d_female NA NA
d_age05 NA NA
I(d_age05^2) NA NA
as.factor(year)2007 0.0317923 834.342
as.factor(year)2008 0.0225808 833.911
as.factor(year)2009 -0.0243202 834.191
as.factor(year)2010 0.0118992 834.584
as.factor(year)2011 0.0158923 834.714
as.factor(year)2012 0.0024724 834.187
as.factor(year)2013 0.0091423 834.476
as.factor(year)2014 -0.0221640 834.483
as.factor(year)2015 -0.0068167 834.348
Multiple R-squared: 0.0134 , Adjusted R-squared: 0.01186
F-statistic: NA on 13 and 835 DF, p-value: NA
2005년도 당시의 연령 age05와 여성 더미변수 female은 시간에 따라 변화하지 않으므로 모두 회귀에서 제외된다. 정규적 여부를 나타내는 isregul 변수의 계수 추정값은 예제 3.1의 BE 추정값(0.332)보다 훨씬 작은 0.086이다. 이는 여타 요소 통제 시 정규직 노동자와 비정규직 노동자 간에는 상당한 임금 격차가 존재하지만, 동일 노동자의 상태가 비정규직에서 정규직으로 바뀔 때의 임금 변화는 그보다 훨씬 작음을 나타낸다.
d_educ의 계수가 추정된 것은 educ 내 집단내 변동이 약간이라도 존재하는 것을 의미한다. 총 11명에서 educ 변수의 값이 변하는 것을 확인할 수 있다.
결과에 따르면, 2명은 고졸 \(\rightarrow\) 전문대졸, 3명은 고졸 \(\rightarrow\) (4년제) 대졸, 1명은 전문대졸 \(\rightarrow\) 대졸, 나머지 5명은 대졸 \(\rightarrow\) 석사로 표본기간 도중에 변경되었다. 모델에서 d_educ의 계수값은 이 11명의 변동 내역에 따라 추정된 값이다. 만약 이 11명을 분석에서 제외하면 d_educ는 소거되고 isregul의 계수 추정값은 0.088로 약간 바뀐다.
Note
연습 3.5. 표본기간 내에 educ 값이 변하지 않은 개인들만을 대상으로 본 예제의 모형을 추정하여 isregul 변수의 계수 추정값이 0.875957임을 확인하라.
panel_fd_klipsbal_noeduc<-lm_robust(d_lwage~d_educ+d_tenure+I(d_tenure^2)+d_isregul+d_female+d_age05+I(d_age05^2)+as.factor(year), data =d_klipsbal|>drop_na()|>dplyr::filter(!pid%in%unique_pid), # unique_pid 는 변동값을 가지는 11명의 id이다. clusters =pid)summary(panel_fd_klipsbal_noeduc)
Call:
lm_robust(formula = d_lwage ~ d_educ + d_tenure + I(d_tenure^2) +
d_isregul + d_female + d_age05 + I(d_age05^2) + as.factor(year),
data = dplyr::filter(drop_na(d_klipsbal), !pid %in% unique_pid),
clusters = pid)
Standard error type: CR2
Coefficients: (4 not defined because the design matrix is rank deficient)
Estimate Std. Error t value Pr(>|t|) CI Lower
(Intercept) 0.0678753 0.0100051 6.7840 2.345e-11 0.0482344
d_educ NA NA NA NA NA
d_tenure 0.0014468 0.0038408 0.3767 7.096e-01 -0.0064653
I(d_tenure^2) -0.0002205 0.0001844 -1.1959 2.511e-01 -0.0006149
d_isregul 0.0875057 0.0240077 3.6449 3.577e-04 0.0401053
d_female NA NA NA NA NA
d_age05 NA NA NA NA NA
I(d_age05^2) NA NA NA NA NA
as.factor(year)2007 -0.0028908 0.0169698 -0.1704 8.648e-01 -0.0361999
as.factor(year)2008 -0.0036123 0.0131308 -0.2751 7.833e-01 -0.0293861
as.factor(year)2009 -0.0509532 0.0134192 -3.7970 1.572e-04 -0.0772931
as.factor(year)2010 -0.0121408 0.0123953 -0.9795 3.276e-01 -0.0364708
as.factor(year)2011 -0.0077587 0.0124314 -0.6241 5.327e-01 -0.0321597
as.factor(year)2012 -0.0192678 0.0117460 -1.6404 1.013e-01 -0.0423234
as.factor(year)2013 -0.0167098 0.0123746 -1.3503 1.773e-01 -0.0409992
as.factor(year)2014 -0.0460006 0.0117593 -3.9118 9.915e-05 -0.0690824
as.factor(year)2015 -0.0319134 0.0128800 -2.4777 1.342e-02 -0.0571949
CI Upper DF
(Intercept) 0.087516 762.96
d_educ NA NA
d_tenure 0.009359 24.88
I(d_tenure^2) 0.000174 14.36
d_isregul 0.134906 165.72
d_female NA NA
d_age05 NA NA
I(d_age05^2) NA NA
as.factor(year)2007 0.030418 823.57
as.factor(year)2008 0.022162 823.16
as.factor(year)2009 -0.024613 823.54
as.factor(year)2010 0.012189 823.93
as.factor(year)2011 0.016642 823.87
as.factor(year)2012 0.003788 823.52
as.factor(year)2013 0.007580 823.77
as.factor(year)2014 -0.022919 823.84
as.factor(year)2015 -0.006632 823.70
Multiple R-squared: 0.0131 , Adjusted R-squared: 0.01166
F-statistic: NA on 12 and 824 DF, p-value: NA
FD 회귀에서 2중 클러스터 분산추정은 1계차분한 오차항 \(\Delta u_{it} = \Delta\varepsilon_{it}\)에 임의의 시계열 상관과 임의의 동시기 횡단면 상관(동시상관)을 허용하는 분산추정 방법이다. R 에서는 {AER}의 ivreg 함수에서 type = "HC0", vcov. = sandwich::vcovHC, cluster = id 옵션을 부여하여 이를 수행할 수 있다. 그런데 이 경우는 소표본 자유도 조정을 하지 않은 결과라서, 소표본 자유도 조정한 FD 회귀 2중 클러스터 분산추정을 하고 싶다면 fixest 패키지의 feols 함수의 ssc = ssc(fixef.K = "full") 옵션을 이용하여 추정할 수 있다.
twowaycl<-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/twowaycl.dta")twowaycl|>group_by(id)|>mutate( d_y =y-dplyr::lag(y, n =1, order_by =year), d_x1 =x1-dplyr::lag(x1, n =1, order_by =year), d_x2 =x2-dplyr::lag(x2, n =1, order_by =year), d_after =after-dplyr::lag(after, n =1, order_by =year))|>dplyr::select(id, year, contains("d_"))->d_twowaycllibrary(lmtest)twoway_fdcl<-coeftest(AER::ivreg(d_y~d_x1+d_x2+d_after, data=d_twowaycl), type ="HC0", vcov. =sandwich::vcovHC, cluster =id)twoway_fdcl|>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)
================================
Model 1
--------------------------------
(Intercept) 0.1065 (0.0550)
d_x1 0.5860 (0.0808) ***
d_x2 0.9362 (0.3680) *
d_after 1.4256 (0.1619) ***
================================
*** p < 0.001; ** p < 0.01; * p < 0.05
원래의 고유오차 \(\varepsilon_{it}\) 가 IID인 상황에서도 식 \(\ref{eq-ch3-6}\)의 오차항 \(\Delta \varepsilon_{it}\)는 시계열 상관을 보이므로 FD 추정량은 BLUE가 아니다(♖). 이 경우, \(\varepsilon_{it}\)가 IID라는 특정한 가정하에서 GLS를 할 수 있다. 그 가정하에서 공분산의 구조는
여기서 \(\bar{y}_i = T^{-1}\sum^T_{t=1}y_{it}\)이고 \(\bar{X}_i\)와 \(\varepsilon_i\)도 이와 마찬가지로 정의된다. 불균형패널일 경우에는 \(T\)를 \(T_i\)로 바꾸면 된다(개체별로 시계열의 종료 시점이 다를테니까). 첫 번째 식에서 두 번째 식을 빼면 다음의 식을 얻는다.
여기서도 \(\mu_i\)가 소거된다. 식 \(\ref{eq-ch3-10}\) 을 POLS하는 것을 집단내(within-group, WG) 회귀 또는 고정효과(fixed effects, FE) 회귀라고 한다. ’집단내’라는 수식어가 붙는 것은 식 \(\ref{eq-ch3-10}\) 에서 \(y_{it}-\bar{y}_i\)와 \(X_{it}-\bar{X}_i\)를 해당 변수들의 집단내(within-group) 편차라고 하는 것과도 관련된다. ’고정효과 회귀’라는 이름은 원래 \(\mu_i\)들을 고정된 모수로 간주한다는 것으로부터 유래하였으나, 이보다는 ’집단내 편차들을 이용한 OLS’라고 받아들이는 편이 혼동을 줄일 수 있을 것이다.
Note
수학적 증명을 요구하는 연습문제 3.6과 3.7을 여기서 따로 풀이하지 않는다.
FE 회귀가 식 \(\ref{eq-ch3-10}\) 에 대하여 POLS를 하는 것이기는 하지만 식 \(\ref{eq-ch3-10}\) 에 맞추어 결과를 해석할 필요는 없다. FD 추정값의 경우처럼 FE 추정값 \(\hat{\beta}_{fe}\)을 해석하기 위해서는 원래 FE 모형으로 돌아가서 “동일 개체 내에서 설명변수 값에 \(\Delta x\)만큼의 차이가 있으면 종속변수 값에 평균 \((\Delta x)\hat{\beta}_{fe}\)만큼의 차이가 있는 것으로 추정된다”고 해석하면 된다.
독립변수가 x1, x2이고 종속변수가 y일 때, R에서 시간더미들을 포함하여 FE 추정을 하려면 plm 패키지의 함수에서 model = "within 옵션을 사용한다.
plm(y ~ x1 + x2 + as.factor(year), data = data, model = "within", index = c("id", "year")
연구자의 재량에 따라 시간더미가 필요없다고 판단되면 as.factor(year)를 삭제하면 되지만 그 이유를 잘 성명하여야 한다.
x1, x2는 시간에 따라 변화하는 변수들이다. 시간에 걸쳐 변하지 않는 변수의 경우에는 그 개체별 평균을 빼면 모든 \(i\)와 \(t\)에서 0이 되므로 모형으로부터 소거되어 버린다. 이 때문에 \(X_{it}\)에는 시간에 따라 변화하는 설명변수들만 있어야 한다.
앞에서 설명하였듯이, FE 회귀는 회귀식을 \(\ref{eq-ch3-10}\) 으로 변형하여 POLS를 하는 것이다. 그런데 \(\ref{eq-ch3-10}\)의 오차항에는 \(\bar{\varepsilon}_i\)가 포함되어 있으므로, 고유오차 \(\varepsilon_{it}\)가 IID이건 아니건 간에 상관없이 최종 회귀식 오차항인 \(\varepsilon_{it} - \bar{\varepsilon}_i\)는 시계열 상관을 갖는다. OLS로 추정할 회귀식의 오차항에 시계열 상관이 있을 대에는 견고한 표준오차를 사용하여야 한다(♖). FE 회귀에서 집단내 편차들로 표현된 회귀식의 오차항 \(\varepsilon_{it}-\bar{\varepsilon}_i\)도 시계열 상관을 갖기 때문에 표준오차 계산 시 이를 고려하여야 한다.
Note
연습 3.8. \(T=3\)이라 하자. \(\varepsilon_{i1}, \varepsilon_{i2}, \varepsilon_{i3}\)이 IID이고 평균이 0, 분산이 1이라면 \(\varepsilon_{it}-\bar{\varepsilon}_i\)의 분산은 무엇인가? 그 경우 \(\varepsilon_{i1}-\bar{\varepsilon}_i\)와 \(\varepsilon_{i2}-\bar{\varepsilon}_i\)의 공분산은 무엇인가? 단, \(\bar{\varepsilon}_t = \frac{1}{3}(\varepsilon_{i1}+\varepsilon_{i2}+\varepsilon_{i3})\).
이므로 \(\varepsilon_{i1}-\bar{\varepsilon_i}\)의 분산은 \(\frac{4}{9} + \frac{1}{9} + \frac{1}{9} + \frac{6}{9} = \frac{2}{3}\)이고, 나머지 두 개의 분산도 이와 동일하다. 따라서 \(\mathrm{cov}(\varepsilon_{i1}-\bar{\varepsilon}_i, \varepsilon_{i2}-\bar{\varepsilon}_i) = -\frac{2}{9} - \frac{2}{9} + \frac{1}{9} = -\frac{1}{3}\)이 된다.
고유오차항 \(\varepsilon_{it}\)가 IID인 경우 FE 추정량의 분산은 특수한 형태를 갖는다. 한치록 (2021, 91–92)는 \(\varepsilon_{it}\)가 IID일 때, FE 추정량의 표준오차를 구하기 위한 자유도 조정을 수학적으로 도출하는 방법을 보여주고 있다.
Note
예제 3.7 인구구조와 총저축률 (FE 회귀)
다음 결과는 예제 2.5의 저축률 모형을 FE 회귀로 추정한 것이다.
wdi5bal_fe<-plm::plm(sav~age0_19+age20_29+age65over+lifeexp+as.factor(year), model ="within", index =c("id", "year"), data =wdi5bal)summary(wdi5bal_fe)
Oneway (individual) effect Within Model
Call:
plm::plm(formula = sav ~ age0_19 + age20_29 + age65over + lifeexp +
as.factor(year), data = wdi5bal, model = "within", index = c("id",
"year"))
Balanced Panel: n = 96, T = 6, N = 576
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-19.6311 -2.5381 -0.1014 2.5932 23.0287
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
age0_19 -0.18741 0.13773 -1.3608 0.174241
age20_29 -0.28544 0.20285 -1.4072 0.160034
age65over -1.21748 0.32082 -3.7948 0.000167 ***
lifeexp 0.74314 0.10969 6.7751 3.722e-11 ***
as.factor(year)1990 0.21553 0.81747 0.2637 0.792160
as.factor(year)1995 -0.30662 0.90338 -0.3394 0.734452
as.factor(year)2000 -1.39911 1.03425 -1.3528 0.176774
as.factor(year)2005 -0.87692 1.23344 -0.7110 0.477461
as.factor(year)2010 -2.99587 1.47392 -2.0326 0.042655 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Total Sum of Squares: 15942
Residual Sum of Squares: 13929
R-Squared: 0.12627
Adj. R-Squared: -0.066658
F-statistic: 7.563 on 9 and 471 DF, p-value: 2.2144e-10
lifeexp의 계수 추정값인 0.743은 “동일 국가 내에서 시간에 걸쳐 age0_19, age20_29, age65over가 일정하고 기대수명에 1년 차이가 있으면 총저축률에 평균적으로 약 0.74% 포인트의 차이가 있는 것으로 추정된다”고 해석된다. 개별효과와 설명변수 간에 상관관계(횡단면 상관관계)가 있으면 FE 추정값과 RE 추정값 사이에 상당한 차이가 있는 것이 당연하고, FE 추정값과 FD 추정값은 모두 고정효과 모형의 모수 추정값이므로 유사하여야 한다.
그런데 이 결과를 예제 2.5(RE 회귀) 및 예제 3.4(FD 회귀)의 결과와 비교하면 lifeexp의 FE 계수 추정값(.743)은 FD 추정값(435)보다 오히려 RE 추정값(.554)에 가깝다.
FD 회귀와 FE 회귀가 모두 고정효과 모형을 일관되게 추정하므로 FE 회귀 결과가 FD 회귀 결과보다 RE 회귀 결과와 유사한 것이 약간 당혹스러우나, 적어도 추정값들의 부호가 동일하고 또 RE 추정값이 FE 추정값과 유사한 경우도 있으므로 완전히 잘못된 결과라고 보기는 어렵다 (한치록 2021: 94) .
FE 회귀에서, 만약 \(\varepsilon_{it}\)에 이분산이나 시계열 상관이 있으면 FE 추정량은 여전히 일관적이지만(♔) 통상적인 표준오차들은 타당하지 않다(♖). 이 경우에도 가장 손쉬운 방법은 클러스터 표준오차를 사용하는 것이다.
클러스터 표준오차는 동일한 \(i\)로 이루어진 관측치들을 하나의 클러스터로 는 것으로써, 클러스터 개수인 \(n\)이 (충분히) 크기만 하다면 \(\varepsilon_{it}\)에 임의의 이분산이 있고 \(t\)에 걸쳐 어떤 상관이 있어도 사용할 수 있는 편리한 것이다. 다음의 예제를 보라.
Note
예제 3.8 인구구조와 총저축률(FE 회귀, 견고한 표준오차)
예제 3.7의 추정량에 대하여 견고한(클러스터) 표준오차를 계산하도록 하면 다음 결과를 얻는다.
wdi5bal_fe_robust<-plm::plm(sav~age0_19+age20_29+age65over+lifeexp+as.factor(year), model ="within", index =c("id", "year"), data =wdi5bal)coeftest(wdi5bal_fe_robust, vcov. =vcovHC, type="HC1")|>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)
통상적인 표준오차를 사용하는 경우와 비교하면 계수 추정값은 동일하나 표준오차가 변경되었다. 이 예제에서는 클러스터 표준오차를 사용하여도 시간더미들을 제외하면 유의성면에서 결과를 바꿀만한 차이가 없다. 다른 분석에서는 통계적 유의성이 달라질 수도 있다.
FE 회귀를 견고한 표준오차(robust standard errors)로 추정했을 경우, STATA의 xtreg y x1 x2, fe vce(robust) 결과와 소수점 단위에서 살짝 다른 것을 확인할 수 있다. 크게 두 가지 이슈를 생각해볼 수 있다.
클러스터-견고한 공분산 추정방법의 문제이다. STATA에서 vce(cluster <groupvar>) 또는 vce(robust)로 추정하는 것은 R에서는 위에서의 재현 코드와 같이 vcovHC의 오차 유형 중 method = "arellano", type = "HC1"로 재현할 수 있다.
소표본 조정(small sample correction)의 문제인데, 이 부분은 STATA와 R이 조금 다르다.
STATA에서는 \(G\)가 클러스터의 수이고 \(N\)이 관측치의 수라고 할 때, 소표본 조정을 위해 잔차에 가중치를 \(\sqrt{G/(G-1)\times(N-1)/(N-K))}\)로 부여한다 (Cameron, Gelbach, and Miller, n.d.: 8). 한편, R의 plm의 오차유형 HC0부터 HC4는 클러스터를 고려하지 않은 소표본 조정 방식을 취한다 (Zeileis 2004).
따라서 현재로 R과 STATA 간의 호환을 고려해볼 때, type = "HC1"가 가장 유사한 결과를 얻을 수 있는 옵션이라고 할 수 있다.
FD 회귀처럼, 시간에 따라 변하지 않는 설명변수들은 FE 회귀 시 소거된다. 이는 FE 회귀가 동일 개체 내에서 시간에 따른 변화만을 고려하기 때문이다. 다음 예제에서는 정규직 전환의 효과를 FE 회귀로써 추정한다. 결과가 깔끔한 모양을 갖도록 하기 위하여 시간불변 설명변수들은 모형에서 미리 제외시킨다.
Note
예제 3.9 정규직 전환 효과의 FE 회귀
임금방정식 모형에서 시간불변 설명변수들을 제외시킨 다음 시간더미들을 포함시키고 FE 회귀를 하자. 견고한 표준오차를 사용한다.
klipsbal<-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/klipsbal.dta")klipsbal_fe_robust<-plm::plm(lwage~educ+tenure+I(tenure^2)+isregul+as.factor(year), model ="within", index =c("pid", "year"), data =klipsbal)coeftest(klipsbal_fe_robust, vcov. =vcovHC, type="HC1")|>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)
2005년도 당시의 연령 age05와 여성 더미변수 female은 시간에 따라 변하지 않으므로 회귀에서 제외되었다. 정규직 여부를 나타내는 isregul 변수의 계수 추정값은 예제 3.1의 BE 추정값(0.3315)나 예제 2.1의 POLS 추정값(.2717)보다 훨씬 작은 .1247로, FD 추정값(.0864)보다 약간 더 크다. 이 또한 여타 요소 통제 시 정규직 노동자와 비정규직 노동자 간에는 상당한 임금 격차가 있으나, 동일 노동자의 상태가 비정규직인 시기와 정규직인 시기 간 임금차이는 그보다 훨씬 작음을 나타낸다.
FE 회귀에서도 2중 클러스터 분산추정이 가능하다.
1단계: model_fecl <- plm(y ~ x1 + x2, data = data, index = c("id", "year"), model = "within", effect = "individual")
STATA와 R로 계산한 표준오차 결과가 소수점 셋째 자리에서 약간 다르게 나타나는 것은 알 수 있으나, 이 차이는 사소하다고 할 수 있다.
Note
예제 3.10 FE 회귀에서 2중 클러스터 분산추정
FE 회귀에서 2중 클러스터 분산추정을 연습하자.
library(lmtest)twoway_fecl<-plm::plm(y~x1+x2+after, data=twowaycl, index =c("id", "year"), model ="within", effect ="individual")coeftest(twoway_fecl, vcov =vcovHC(twoway_fecl, type ="HC0", cluster ="time"))|>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)
======================
Model 1
----------------------
x1 0.4533 (0.2408)
x2 0.2406 (1.1329)
after 0.6235 (0.9061)
======================
*** p < 0.001; ** p < 0.01; * p < 0.05
앞서 언급한 바와 같이 소표본 조정 방식의 차이로 인해 표준오차의 결과가 미세하게 다르다고 이해할 수 있다.
한편, \(\varepsilon_{it}\)에 이분산이나 시계열 상관이 있을 때에는 FE 추정량보다 더 나은 선형 비편향 추정량이 존재한다(♖). \(n\)이 크고 \(T\)가 작으면 FGLS 추정량(“고정효과 FGLS”이라 하며 WG 변환 후 FGLS를 하면 된다)을 어렵지 않게 구할 수 있으나, \(T\)가 크면 계산이 불가능하거나 그 성질이 매우 나쁠 수 있고, FE 회귀가 일종의 표준적인 방법으로 간주되어 실제 연구에서 고정효과 FGLS가 많이 사용되지는 않는다.
3.4.1 FE 회귀와 관련된 잔차들
FE 추정으로부터 여러 종류의 잔차들(residuals)을 구할 수 있으며, 아무 설명 없이 그냥 “잔차”라고만 하면 무엇을 의미하는지 알아듣지 못할 수 있다. 잔차의 종류에 대해 구체적으로 살펴보자.
잔차의 집단내 편차(집단내 잔차)
식 \(\ref{eq-ch3-10}\) 에 따라 \(y_{it}-\bar{y}_i\)를 \(X_{it}-\bar{X}_i\)에 대하여 회귀하여 구하는 잔차
\(\hat{\beta}\)이 FE 추정량이라 할 때, 이 잔차는 \((y_{it}-\bar{y}_i)-(X_{it}-\bar{X}_i)\hat{\beta}\)이다.
이 잔차는 \(u_{it}\)에도, \(\varepsilon_{it}\)에도 정확히 해당되지 않는다.
잔차 공식에서 \(\hat{\beta}\)를 \(\beta\)로 치환하고 식을 재정렬해보면, 이 잔차는 \((y_{it}-X_{it}\beta) - (\bar{y}_i-\bar{X}_i)\beta\)를 추정한 것에 해당된다.
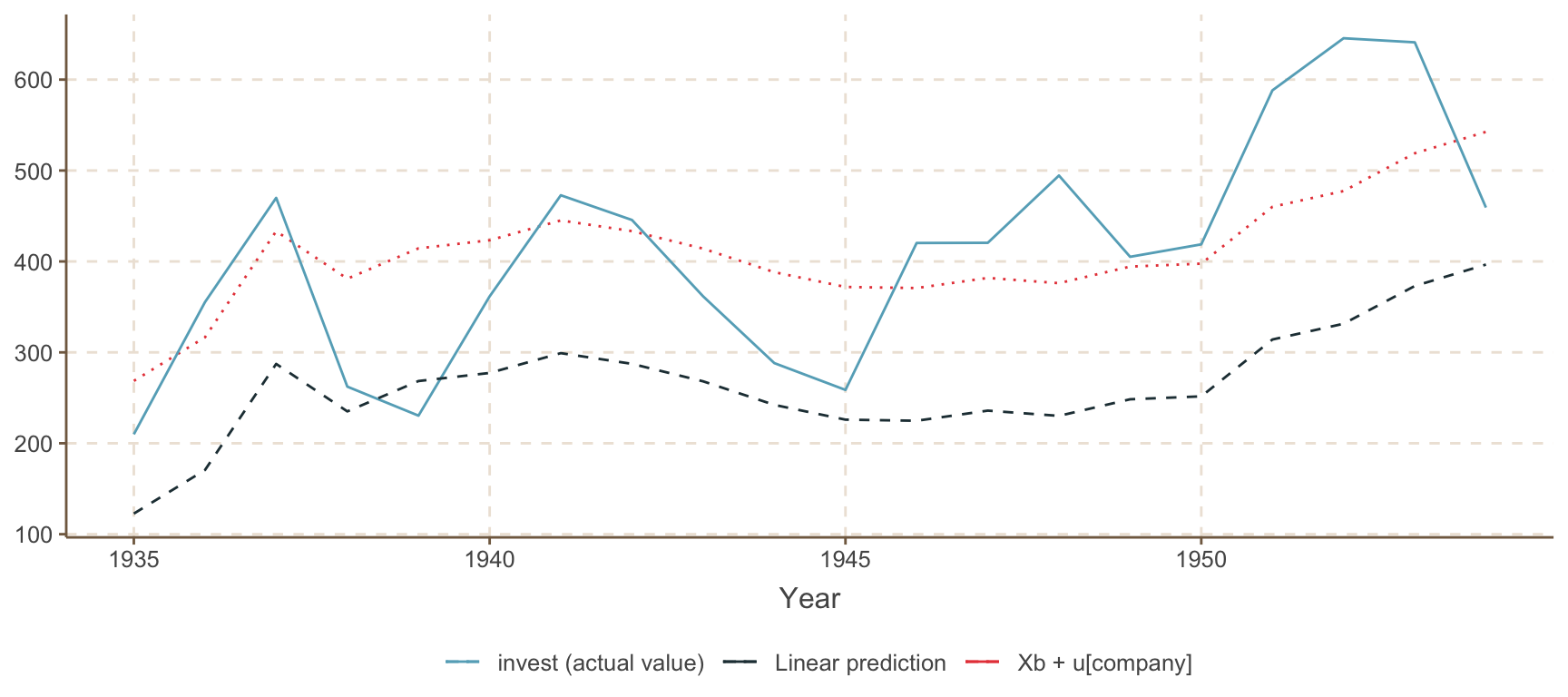
다음 예를 보자. Grunfeld (1958) 의 원래 데이터를 가공한 10개 회사의 20년 패널데이터(grunfeld.dta)를 이용하여 FE 회귀를 하고 Xb예측값과 Xbu예측값을 구한다. 종속변수는 기업의 투자(invest), 독립변수는 해당 기업의 시장가치(mvalue)와 자본스톡(kstock)이다. 변수들에 로그값을 취하는 것이 좋겠지만 여기서는 분석을 용이하게 하기 위하여 원변수로 모델에 퉁칩한다.
================================
Model 1
--------------------------------
mvalue 0.1101 (0.0119) ***
kstock 0.3101 (0.0174) ***
--------------------------------
R^2 0.7668
Adj. R^2 0.7531
Num. obs. 200
================================
*** p < 0.001; ** p < 0.01; * p < 0.05
Figure 3.1: Grunfeld (1958) 자료에서 Xb예측값과 Xbu예측값
Figure 3.1 에서 나타난 Xbu예측값과 Xb예측값의 차이가 해당 회사(2번 회사)의 개별 효과 추정값인 \(\hat{\mu}_2\)이다. 그림에서 2번 회사의 개별효과 추정값은 0보다 크다( \(\hat{\mu}_2 > 0\))
3.4.3 개체 수가 적은 패널에서 FE 추정량의 성질
\(n\)이 작고 \(T\)가 큰 경우 FE 추정량은 어떤 성질을 갖는가? POLS와는 달리 FD나 FE 회귀에서는 \(\mu_i\)가 애초에 소거되기 때문에 추정값의 불확실성으로 인한 비일관성의 문제가 없다. 설명변수 \(X_{it}\)에 시간에 따른 변화가 충분히 존재하기만 한다면, 고정효과 추정량들은 \(n\)이 증가하든 \(T\)가 증가하든 관계없이 모수의 참값으로 수렴할 것이라고 기대할 수 있다. 단, 이 경우 설명변수에 집단간 차이만 크고 집단내 변동이 작으면 FD나 FE 추정량의 분산은 클 수 있다.
3.4.4 시기별 효과
시기별 효과는 시간더미로 처리할 수 있다. \(n\)이 크고 \(T\)가 작은 패널 데이터의 경우 시간더미의 개수도 적으므로 문제가 되지 않는다. 반면에 \(n\)이 작고 \(T\)가 큰 경우에는 시간더미의 개수가 많아 그 계수들이 따름모수가 되어 주의하여야 한다.
이 2원(two-way) 고정효과 모형에서 \(\mu_i\)와 \(\delta_t\)를 동시에 소거하려면 개체별 평균을 빼는 변환(within-group 변환)을 한 후 시간대별 평균을 빼는 변환(within-period 변환)을 재차 해주면 될 것이다. 구체적으로, 개체별 평균을 빼면 다음의 식을 얻는다.
여기서 \(\bar{y}_{\cdot t} = \frac{1}{n}\sum^n_{i=1}y_{it}\)이고 \(\bar{\bar{y}}=\frac{1}{nT}\sum^{T}_{t=1}y_{it}\)이며, 나머지 \(\bar{X}_{\cdot t}\) 등의 기호도 이와 동일한 방식으로 정의된다. 이렇게 개별효과와 시간대별 효과를 모두 소거한 다음 POLS를 하면 되는데, 이 추정법은 시간더미를 우변에 포함시키고 FE 추정을 하는 것과 완전히 동일하다. \(T\)가 크더라도 시간더미들을 우변에 포함시키는 것이 문제를 야기하지 않는다.
3.4.5 집단내 변동이 작은 경우
\(X_{it}\)에 시간에 걸친 변동이 별로 없다면 FD와 FE 추정량의 분산은 매우 클 수 있다.
극단적으로 만약 \(X_{it}\)가 시간에 걸쳐 변하지 않는다면 시간에 따른 변화량이나 평균 모두 0으로 소거되어 버리므로 \(\beta\)의 추정이 불가능하다.
극단적인 경우는 아니더라도 만약 \(X_{it}\)가 개체 간 상당한 차이가 있지만 동일 개체 내에서 변하는 정도가 매우 작다면, FE 추정값이나 FE 추정값이 계산될지라도, 설명변수의 집단내 변동이 제한되어 추정량의 정확성은 현저히 떨어질 수 있다.
이런 경우 흔히 표준오차가 매우 크고 \(t\)-값이 작으며 \(p\)-값이 커서 변수들이 유의하지 않는 일이 발생한다. 이는 FD나 FE 추정의 불가피한 비용이다.
POLS와 RE 회귀는 \(i\)에 걸친 변동도 이용하므로 이러한 문제가 없었다. 반면 POLS 추정량과 RE 추정량은 개별효과가 고정효과일 때 일관적이지 않다는 더 심각한 문제가 있다.
Note
예제 3.12 집단내 변동과 집단간 차이
wdi5bal.dta 데이터에서 lifeexp 변수는 집단간 차이에 비하여 집단내 변동이 작다.
re<-plm::plm(sav~age0_19+age20_29+age65over+lifeexp+as.factor(year), data =wdi5bal, model ="random", index =c("id", "year"))re_robust<-coeftest(re, vcovHC(re, type ="HC1", cluster ="group"))fe<-plm::plm(sav~age0_19+age20_29+age65over+lifeexp+as.factor(year), data =wdi5bal, model ="within", index =c("id", "year"))fe_robust<-coeftest(fe, vcovHC(fe, type ="HC1", cluster ="group"))screenreg(list(re_robust, fe_robust), custom.model.names =c("RE", "FE"), custom.coef.map =list("lifeexp"="lifeexp"), digits =4, include.ci =FALSE, single.row =FALSE, include.rsquared =TRUE, include.adjrs =TRUE)
================================
RE FE
--------------------------------
lifeexp 0.5536 *** 0.7431 **
(0.1145) (0.2421)
================================
*** p < 0.001; ** p < 0.01; * p < 0.05
lifeexp에 대한 RE 모델과 FE 모델 간의 추정값과 클러스터 표준오차를 비교하였다. lifeexp 계수의 RE 추정량의 표준오차는 약 0.1145임에 비하여, 동일 모델에 대한 FE 추정량이 클러스터 표준오차는 0.2421로 두 배 이상이다.
3.4.6 표준오차에 관한 부연설명
3.4.7 집단내 FGLS 추정
3.5 더미변수 회귀
3.6 LSDV와 FE 회귀의 관계
3.7 계수의 해석과 모형 비교
3.7.1 추정량들 간의 수학적 관계
3.7.2 그림을 이용한 추정량들의 비교
3.8 상관된 임의효과
3.9 고정효과 대 임의효과 검정
3.9.1 회귀를 이용한 방법
3.9.2 하우스만 검정
3.9.3 고정효과 대 임의효과 검정에 관한 추가 주제들
3.10 Hausman과 Taylor의 모형
3.10.1 HT의 상세한 추정 절차
3.10.2 특수 경우들
Cameron, A. Colin, Jonah B. Gelbach, and Douglas L. Miller. n.d. “Robust Inference with Multi-Way Clustering.”https://doi.org/10.3386/t0327.
Hausman, Jerry A., and William E. Taylor. 1981. “Panel Data and Unobservable Individual Effects.”Econometrica 49 (6): 1377–98. https://doi.org/10.2307/1911406.
Zeileis, Achim. 2004. “Econometric Computing with HC and HAC Covariance Matrix Estimators.”Journal of Statistical Software 11 (November): 1–17. https://doi.org/10.18637/jss.v011.i10.
오차 내의 고유오차(백색잡음)은 확률적이다. 따라서 체계적 오차라고 할 수 있는 고정효과가 서로 다른 개체 간 또는 개체 내부의 함수관계의 차이를 만들어준다. 비교정치적 맥락에서 보자면 개별 국가의 고유한 특성이 다른 국가와의 차이를 보여주는 근거가 되며, 그러한 고유한 특성은 해당 국가에 속한 개체들에 걸쳐서 다른 국가에 속한 개체들과는 차별적이라고 할 수 있다.↩︎
---bibliography: biblio.bib---# 고정효과 모형 {#sec-ch3}앞의 @sec-ch3 에서는 '개체 간' 비교로부터 도출되는 함수관계와 '개체 내'비교로부터 도출되는 함수관계가 동일하여 이 둘을 굳이 구별할 수가 없는 경우에한정하여 살펴보았다. 이 장에서는 이 둘이 상이한 정보를 제공하는 경우에 대해서살펴본다.모형 $y_{it} = X_{it}\beta + u_{it}$에서 오차($u_{it}$)를 개별효과($\mu_i$)와고유효과($\varepsilon_{it}$)로 구분하고 $X_{it}$가 $\varepsilon_{it}$에 대하여강외생적이라고 가정할 경우[^chapter3-1], '개체 간' 함수관계와 '개체 내'함수관계를 다르게 만들어주는 것은 $\mu_i$의 역할이다.[^chapter3-2] 변수들 간에$y_{it} = X_{it}\beta + \mu_i + \varepsilon_{it}$ 관계가 성립하고, $X_{it}$가$\varepsilon_{it}$에 대하여 강외생적이지만 $\mu_i$와는 아무렇게나 상관(횡단면상관)될 수 있는 모형을 **고정효과(fixed effects)** 모형이라고 한다. 고정효과모형에서 $\beta$는 설명변수가 고유오차에 대하여 강외생적이라는 가정에 의해서만정의된다.[^chapter3-1]: 즉, 오차 중에서 고유오차(백색잡음)은 설명변수와 독립적이라고 가정할 경우.[^chapter3-2]: 오차 내의 고유오차(백색잡음)은 확률적이다. 따라서 체계적 오차라고 할 수 있는 고정효과가 서로 다른 개체 간 또는 개체 내부의 함수관계의 차이를 만들어준다. 비교정치적 맥락에서 보자면 개별 국가의 고유한 특성이 다른 국가와의 차이를 보여주는 근거가 되며, 그러한 고유한 특성은 해당 국가에 속한 개체들에 걸쳐서 다른 국가에 속한 개체들과는 차별적이라고 할 수 있다.- 개체 간, 즉 집단간(between-group) 비교를 위하여, 우선 패널 데이터를 개체별 평균들의 횡단면 데이터로 축약하고, 이 축약한 횡단면 데이터를 이용하여 OLS를 하는 것을 집단간(between effect, BE) 회귀라고 한다.- 집단내(within-group) 비교로부터 도출되는 함수관계도 존재한다. - 고정효과 모형 $y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}$에서 이 함수관계를 표현하는 한 가지 방법은 $E(y_{it}|X_{i1}, \dots, X_{iT}, \mu_i) = \alpha + X_{it}\beta + \mu_i$이다. - 즉, $\mu_i$ 값이 동일하고 $X_{it}$ 값에 차이가 있으면, $X_{it}\times \beta$ 만큼 종속변수에 차이가 있을 것으로 기대된다. - $\mu_i$ 값이 동일하게 고정된다는 의미는 동일한 집단에 속한 개체(고정효과를 공유하는)라는 의미로, 이 경우 종속변수의 차이는 집단내의 비교라고 할 수 있다.- 이 모형이 @sec-ch3 의 임의효과(random effects) 모형과 다른 점은, 설명변수들과 $\mu_i$ 간의 상관관계에 대해 어떠한 제약도 가하지 않는다는 점이다.::: callout-note임의효과 모형에서는 $X_{it}$와 $\mu_i$가 서로 비상관이라는 가정한다. 고정효과모형에서는 $E(\mu_{i}|X_{i1}, \dots, X_{iT})$가 $X_{i1},\dots X_{iT}$의 함수일수 있기 때문에 $E(y_{it}|X_{i1}, \dots, X_{iT}) = \alpha + X_{it}\beta$라고표현할 수 없다 [@hancirog2021: 66].:::고정효과 모형에서 계수의 추정을 위해서는 POLS나 RE 추정의 방법을 사용할 수 없다.왜냐하면 설면변수가 개별효과를 통하여 오차항과 상관되기 때문이다(♔). 즉,내생성의 문제가 제기된다.- 한 가지 해결 방법은 모델을 바꾸어 문제가 되는 $\mu_i$를 제거하는 것이다. 간단한 방법으로는 모델을 1계차분(first difference)하는 것이다 (3.3절).- 1계차분보다 더 자주 사용되는 방법은 집단내(within-group) 편차를 구하는 변환을 한 것이다 (3.4절).한편, 고정효과 모형$y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}$에서 $\mu_i$들을고정된 모수로 취급하고 우변에 개체 더미변수들을 모조리 추정하는 방법이있다.[^chapter3-3] 이를 **더미변수 최소제곱(least squares dummy variables,LSDV)** 회귀라고 한다 (3.5절).[^chapter3-3]: 통상적으로 정치학과에서 국가 더미나 연도 더미를 포함하는 방법이다.3.6절에서는 BE 추정값과 FE 추정값을 정확하게 해석하는 방법에 대하여 살펴본다.@hancirog2021 [67]은 특히 이 3.6절을 주의하여 살펴볼 것을 주문하고 있다.3.7절에서는 상관된 임의효과 접근법을 강외생성 하 선형 패널모형에 적용할 때발생하는 일에 대하여 설명한다.FE 회귀는 변수들의 집단간 수준 차이를 무시하므로, 집단간 차이를 이용하는 RE추정량보다 효율성이 떨어지는 경우가 많다. 만약 개별효과 $\mu_i$가 임의효과이면RE 추정량과 FE 추정량 간 체계적인 차이가 없으므로, RE 회귀를 하여 FE 모형의계수들을 추정할 수 있다. 3.8절에서는 개별효과가 고정효과인지 임의효과인지를검정하는 방법을 설명한다.마지막으로 3.9절에서는 @hausman1981 가 제시한 일반적인 모형을 살펴본다. 이모형에는 시간에 따라 변화하는(time-varying) 설명변수 ($X_{it}$)와시간불변(time-invariant)의 설명변수 ($Z_{i}$)가 모두 존재하고, $X_{it}$와$Z_{i}$의 일부는 $\mu_i$와 상관되고 나머지는 상관되지 않는다. 이 모델에서는$\mu_i$와 상관되지 않은 변수들을 적절히 도구변수로 활용하게 된다.## 집단간 회귀패널 데이터의 분석에서 개체들 간의 횡단면 함수관계를 측정하기 위해서는집단간(between effect, BE) 회귀를 사용한다.- 패널 데이터에서 시간에 걸친 변동으로부터 오는 정보는 무시하고 개체 간 차이로부터 오는 정보만 이용한다. - 연도의 효과는 무시하고 국가 간 차이로부터 오는 정보만 이용한다는 것이다.- R에서 BE 회귀는 다음과 같이 한다:`plm::plm(y ~ x1 + x2, data = sample, model = "between", index = c("id", "year"))``model = "between` 옵션이 BE 회귀를 하도록 해준다.$\bar{y_i} = \bar{X}_i\beta + \bar{u}_i$이므로, BE 회귀에서 얻는 오차 분산추정량은 $\bar{u}_i$의 분산 추정량이다.패널 데이터 $y_{it}$와 $X_{it}$가 있을 때, BE 회귀는 $\bar{y}_i$를 $\bar{X}_i$에대하여 OLS 회귀를 하는 것이다.- 패널 데이터 내 개체들이 서로 간에($i$ 간에) 독립인 상황에서, $\mathrm{E}(\bar{y}_i|\bar{X}_i)=\bar{X}_i\beta_{be}$가 어떤 $\beta_{be}$에 대하여 성립한다고 하자.- BE의 추정량 $\hat{\beta}_{be}$은 $\beta_{be}$를 일관되게 추정한다. - "\bar{X}\_i가 $\Delta x$만큼 높은 개체의 경우, $\bar{y}_i$가 ($\Delta x$)$\beta_{be}$만큼 높을 것으로 기대된다"고 횡단면 분석결과와 같이 해석할 수 있다. - 즉,`plm::plm(y ~ x1 + x2, data = sample, model = "between", index = c("id", "year"))`라고 하면, "(`x2`를 통제한 후) `x1`의 전체 기간 평균값이 한 단위 더 큰 개체의`y`값이 $\hat{\beta}_{be}$ 정도만큼 더 큰 것으로 나타난다"고 해석할 수 있는 것이다. - BE 회귀는 개체 간 비교를 하는 것이기 때문에 BE 회귀 결과로부터 한 개체 내에서의 변화를 언급할 수는 없다.::: callout-note예제 3.1. 정규적과 비정규직의 임금 비교 (BE 추정)예제 2.1의 임금방정식 예제에 대하여 연도별 더미 `as.factor(year)`를 제거하고 BE회귀를 하면 다음과 같은 결과를 얻게 된다.```{r}#| echo: true#| warning: false#| message: falsepacman::p_load(tidyverse, ezpickr, texreg)klipsbal <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/klipsbal.dta")panel_be <- plm::plm(lwage ~ educ + tenure +I(tenure^2) + isregul + female + age05 +I(age05^2), data = klipsbal, model ="between",index =c("pid", "year"))summary(panel_be)panel_be |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```정규직 여부를 나타내는 `isregul`의 계수 추정값은`r round(panel_be$coefficients[5], 3)`으로, @sec-ch2 에서의 POLS 추정값 (약0.272)이나 RE 추정값 (약 0.146) 보다 훨씬 크다. 다른 요인들을 통제한 후, 전체기간 정규직이었던 노동자(`isregul = 1`)와 전체 기간 비정규직이었던노동자(`isregul = 0`)를 비교하면, 전체 기간 정규직이었던 노동자의 임금이 전체기간 비정규직이었던 비교 대상 노동자에 비해 평균 약`r round(exp(panel_be$coefficients[5])-1, 3)*100`% 높았다.:::예제 3.1의 회귀식은 기간별 더미변수를 포함하지 않는다.- 왜냐하면 시간을 무시하고 개체 단위로 평균을 구해서 횡단면 분석과 같이 취급하기 때문이다.- 균형패널일 경우 모든 $i$에서 각각의 시간더미가 딱 한 번 1의 값을 가지므로 모든 시간더미들의 $t$에 걸친 평균은 $1/T$로 동일하고, 이는 시간더미들의 개체별 표본평균이 상수항과 완전한 공선성(collinearity)을 가지기 때문이다.::: callout-note연습 3.1. 예제 3.1의 모형에 시간더미 변수들(`as.factor(year)`)을 추가하고 BE회귀를 하여, 시간더미 변수들이 어떻게 되는지 확인하라.Ans: 시간 더미들이 분석 결과에서 모두 제외되는 것을 확인할 수 있다.```{r}#| echo: true#| warning: false#| message: falsepanel_be_time <- plm::plm(lwage ~ educ + tenure +I(tenure^2) + isregul + female + age05 +I(age05^2) +as.factor(year), data = klipsbal, model ="between",index =c("pid", "year"))summary(panel_be_time)panel_be_time |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```:::@hancirog2021 [69-73]에서는 BE 회귀를 수동으로 구해보는데, 이 부분은 굳이 해보지않아도 될 것 같다. 앞에서 균형패널의 경우 BE 회귀에 시간더미들을 포함시키면공선성으로 인해 시간더미들이 제외된다고 하였다. 불균형패널의 경우에는 이와 달리완전한 공선성이 일어나지 않아, 살아남은 시간더미에 대해서는 추정값이 계쇤단다.- BE 추정 자체가 패널 데이터에 개체별 평균을 취함으로써 횡단면 데이터를 만들어 분석하는 것이기는 하지만, 변수들에 시간 추세가 존재하는 경우에는 관측 시점이 상이함으로 인해 절편이 상이해지는 일이 발생하고, 우변에 시간더미들(`as.factor(year)`)을 포함시키면 이 문제가 해결된다.::: callout-tip불균형패널 데이터가 있을 때 BE 회귀 시 시간더미들을 우변에 포함시킨다는 것은개체별로 관측시점이 상이함으로 인한 차이를 해당 시간더미들로 통제한다는 것을의미한다.:::5년 시차, 10년 시차 간격으로 평균을 구해서 회귀분석을 수행하는 것처럼, BE 회귀를하는 것은 각 개체의 특성이 시간에 걸친 평균에 의하여 좀 더 정확히 계측된다는믿음 때문으로 보인다 [@hancirog2021: 74].### BE 회귀와 POLS 회귀의 비교모형 $y_{it}=X_{it}\beta + u_{it}$에서 BE 회귀와 POLS 간의 관계를 살펴보자.$X_{it}$가 $u_{it}$에 대하여 강외생적이면 양자 모두 $\beta$를 일관되게 추정한다.$X_{it}$와 $u_{it}$가 상관되는 경우에는 두 모델의 추정량이 $\beta$와 다른 모수를추정한다.- BE 회귀: $\bar{y}_i$와 $\bar{X}_i$의 평균적인 함수관계를 추정 - 독립변수의 전체 기간 표본평균 수준에 차이가 있는 개체들 간에 종속변수의 전체 기간 표본평균 수준에 평균 얼마나 차이가 있는지를 나타낸다.- POLS 회귀: 각 $t$에서 $\mathrm{E}(y_{it}|X_{it})=X_{it}\beta_{pols}$가 성립한다고 할 때의 계수를 추정 - 각 시점에서 개체 간 독립변수의 차이가 종속변수에 평균 어느 정도의 차이를 야기하는지 나타낸다. - 만약 그 정도가 $t$마다 다르다면 각 $t$에서의 계수들을 가중평균한 값이 POLS에 의해 추정된다.이 두 회귀가 추정하는 모수들은 같을 수도 있지만, 다를 수도 있다.- 심지어 각각의 $t$에서 OLS가 추정하는 모든 횡단면 함수관계가 동일한 경우에도 $X_{it}$가 $u_{it}$에 대하여 강외생적이지 않을 때, POLS와 BE 회귀가 서로 다른 모수를 추정할 수 있다.::: callout-tipBE와 POLS 중 무엇이 집단간 차이에 기반한 횡단면 함수관계를 더 잘 표현하는가에대해 @hancirog2021 [76]은 BE 추정량의 손을 들고 있다. 하지만 이 결과는 선택의문제이며 해석의 문제라고 언급하고 있다.:::::: callout-note연습 3.4 $y_{it}=X_{it}\beta + \mu_i + \varepsilon_{it}$라는 모형에서 $X_{it}$가고유오차($\varepsilon_{it}$)에 대해서 강외생적이라고 하자. $T>1$이면 어느 경우에BE 추정량과 POLS 추정량의 확률극한이 동일한가?Ans: 모든 시점($t$)에서 $X_{it}$가 고유오차($\varepsilon_{it}$)에 대해강외생적일 경우, 두 모델의 추정량의 확률극한이 동일하다고 할 수 있다.:::### 가중 BE 회귀BE 회귀는 $i$마다 변수당 하나의 관측치를 만들어 횡단면 OLS 추정을 하는 것이다.그런데 불균형패널의 경우 관측이 이루어진 기간 수가 $i$ 별로 상이할 수있다(불균형 패널). 이때, 관측 연도의 길이($T_i$)에 따라 가중치를 주고 BE 회귀를하는 방법이 있다. 이를 가중 BE 회귀라고 한다.STATA에서는 별도의 옵션으로 쉽게 구할 수 있는 듯 한데, R의 `{plm}`에서는 해당옵션을 찾기가 어려워서 그냥 클러스터 가중치로 `{estimatr}`의 `lm_robust` 함수로구했다. 단 이 경우, 견고한(클러스터) 표준오차를 구하기 때문에 STATA에서의`xtreg y x1 x2, be wls` 신택스로 구한 결과와 표준오차에서 차이가 있다.```{r}#| echo: true#| warning: false#| message: falsewdi5data <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/wdi5data.dta")wdi5data |>group_by(id) |> dplyr::select(sav, age65over, lifeexp) |>drop_na() |>mutate(sav_bar =mean(sav, na.rm = T),age65over_bar =mean(age65over, na.rm = T),lifeexp_bar =mean(lifeexp, na.rm = T)) -> wdi5datalibrary(estimatr)panel_bewt <-lm_robust(sav_bar ~ age65over_bar + lifeexp_bar, data = wdi5data,clusters = id)summary(panel_bewt)panel_bewt |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```## 고정효과 모형설명변수와 상관된 효과를 고정효과(fixed effects)라 한다.- $\mu_i$가 설명변수와 상관되면 $\mu_i$는 개별 고정효과이다.- 오차항을 구성하는 시간대별 효과 $f_t$가 설명변수와 상관되면 $f_t$는 시간별 고정효과이다.$n$이 크고 $T$가 작을 때, $f_t$는 $X_{it}$에 시간더미를 포함시킴으로써 처리할 수있으므로 우선은 $f_t$에 주의를 기울이지 않고 논의를 진행한다. $n$이 클 때,$\mu_i$를 처리하는 방법을 살펴보자.**선형 고정효과 모형**이란$y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}$에서 $X_{it}$는고유오차 $\varepsilon_{it}$에 대해서는 강외생적이지만 $\mu_i$와는 아무렇게나상관될 수 있는 모형이다.- **1원 고정효과 모형(one-way fixed effect model)**: $X_{it}$에 시간더미들이 포함되어 있지 않은 경우- **2원 고정효과 모형(two-way fixed effect model)**: $X_{it}$에 시간더미들이 포함되어 있는 경우보통은 시간더미들을 포함한 2원 고정효과 모형을 주로 사용한다. 고정효과 모형에서$\beta$는 $\mu_i$가 통제될 때, $X_{it}$의 차이로 인한 $y_{it}$의 평균적인 차이를말한다.- 즉, $\beta$는 $\mu_i$가 통제될 때의 효과를 나타내므로 고정효과 모형은 기본적으로 집단내 차이로부터 도출되는 함수관계를 정의한다.$X_{it}$가 상수항을 포함하지 않는다고 하고, 절편을 명시적으로 $\alpha$라고표현해보자. 또한, $X_{it}$의 모든 설명변수들이 시간에 따라변한다(time-varying)한다고 하자. 이에 고정효과 모형은 다음과 같이 나타낼 수있다.```{=tex}\begin{equation}\label{eq-ch3-4}\tag{3.4} y_{it} = \alpha + X_{it}\beta + Z_i \gamma + \mu_i \varepsilon_{it}\end{equation}```모형 \ref{eq-ch3-4}의 $X_{it}$에는 통상적으로 시간더미들이 포함되지만 연구자의재량에 의해 제외될 수 있다. 고유오차 $\varepsilon_{it}$는 설명변수와 전적으로무관하다(강외생적)고 하였으므로 무시하고, 개별효과 $\mu_i$가 고정효과라는 점에집중해보자.- $\mu_i$와 설명변수가 상관될 수 있으므로, $\mu_i$를 오차의 일부로 간주한다면 설명변수와 오차항이 상관되어 $\beta$에 대한 비편향 추정량을 구하기 어렵다(♔). - 특히, POLS나 RE 추정량은 모두 편향된다.- 위의 식에서 $alpha + \mu_i$가 개체별 절편이므로 $n-1$개의 개체별 더미변수를 포함시켜 추정하는 것을 생각해볼 수 있지만, $\mu_i$가 따름모수이므로 그 통계적 특성을 알기 위해서는 수식을 모두 뜯어 살펴보아야 한다. 따라서 여기서는 1차적으로 따름모수들을 제거하고 나서 추정을 하는 방법을 생각해본다.논의의 진행을 위해서 모델 \ref{eq-ch3-4}에서 $Z_i \gamma$ 부분을 제거한 모형을살펴볼 것이다.```{=tex}\begin{equation}\label{eq-ch3-5}\tag{3.5} y_{it} = \alpha + X_{it}\beta + \mu_i \varepsilon_{it}\end{equation}```$Z_i \gamma$ 부분을 제거한 것은 $\mu_i$에 아무런 제약도 없을 때, 둘 사이를 서로구별할 수 없기 때문이다. $T$가 짦은 상황을 고려하므로 시간더미들이 $X_{it}$에포함되어 있다고 해도 좋다. 중요한 것은 $X_{it}$에 시간에 따라 변화하는 변수들만존재한다는 것이다.- $\alpha$인 절편, 상수항은 시간에 걸쳐 불변이다.- 관측불가능한 $\mu_i$는 설명변수들과 상관될 수 있다는 점에서 골칫거리이다. **고정효과 추정의 핵심은** $\mu_i$를 모형으로부터 제거하여 따름모수와 내생성 문제를 해결하고 $\beta$에 대한 일관된 추정을 하는 것이다.- $\mu_i$를 소거할 때, 모든 시간불변 변수들도 함께 소거되므로, 추가적인 가정 없이는 성별 더미나 인종 더미와 같은 시간불변 설명변수들($Z_i$)의 계수를 추정할 수 없다.개별효과 $\mu_i$가 독립변수 $X_{it}$와 상관된다고 할 때, 변수들의 **시간에 걸친차이**를 보면 $\mu_i$가 시간에 따라 변화하지 않으므로, 동일한 $i$ 내에서 특정시점에 $X_{it}$의 값이 상대적으로 크다고 해도 해당 시점의 $\mu_i$의 값은 다른시점에 비하여 클 수 없다. 따라서 동일 개체 내에서 시간에 걸친 변동의 측면을고려하면 개별효과는 독립변수와 상관관계를 가질 수 없다. 그러므로 $\mu_i$와$X_{it}$ 간 양의 상관이 있다는 것은 $\mu_i$가 큰 **개체**에서 $X_{it}$ 값의수준도 대체로 크다는 의미를 갖는다. 그래서 $\mu_i$가 고정효과라고 하면 보통$\mu_i$와 $X_{it}$ 수준 간 **횡단면 상관관계**를 갖는다는 것으로 해석할 수 있다.고정효과 모형에서 상이항 개체들 간 종속변수($y_{it}$)에 수준 차이가 있으면이것이 독립변수($X_{it}$) 수준 차이로 인한 것인지 개별효과($\mu_i$)로 인한것인지 알 수 없다. 반면, 동일한 개체 **내**에서 종속변수 값이 시간에 따라 다르면이로부터 독립변수와 종속변수의 관계에 대해서 유추할 수 있다. **따라서 상이한시점 간 차이로부터 독립변수 차이로 인한 효과를 식별해 내는 것**이 고정효과모형의 분석에서 중요하다.### 고정효과 모형에서 계수의 해석고정효과 모형에서는 설명변수와 $mu_i$가 상관될 수 있다. 이때, $\beta$는$\mu_i$가 동일한 상태에서 설명변수 값에 차이가 있을 경우, 종속변수에 평균적으로어떠한 차이가 있는지를 나타낸다.- 모든 개체들이 서로 독립일 때, $\mathrm{E}(y_{it}|X_{i1},\dots,X_{iT}, \mu_i) = \alpha + X_{it}\beta + \mu_i$- 이는 모집단의 평균에 관한(PA) 모형이 아니라 개별 주체에 관한(SS) 모형의 일종이다.- $j$번째 설명변수의 계수 $\beta_j$는 "다른 설명변수 값들과 $\mu_i$가 동일하고 $j$번째 설명변수 값에만 한 단위 차이가 있을 때 종속변수 값에 존재할 것으로 기대되는 차이"를 의미한다. - 중요한 것은 $\mu_i$가 통제된다는 것이다. - 동일 개체 내에서 시간에 걸친 비교가 이루어질 때에는 $\mu_i$가 고정된다. $\mu_i$는 개체에 따라서만 변화하지 시간에 따라서는 변화하지 않기 때문이다. - 상이한 개체에서 $\mu_i$가 동일한 경우를 상상하기는 어려우므로, 설명변수 값에 $\Delta x$만큼의 차이가 있을 때, $(\Delta x)\beta$는 보통 "**동일한 개체 내에서** 상이한 시점 간에 독립변수들이 $\Delta x$의 차이가 있을 때 종속변수 값에 있을 것으로 기대되는 차이"로 해석한다. - 고정효과를 갖는 모형에서는 고정효과를 명시적으로 통제한다. - 모수는 집단내(within) 비교를 통하여 측정하는 효과와 동의어로 간주된다.## 1계차분 회귀고정효과를 갖는 모형 \ref{eq-ch3-5}의 $\beta$ 계수를 추정하는 가장 간단한 방법은모형 \ref{eq-ch3-5}의 양변에 $t-1$ 시점으로부터 $t$ 시점으로의 증가분을 구하는것이다. 시차에 따른 증가분을 살펴보게 되면, 시간에 따라 변화하지 않는 요인들은0으로 상쇄되어 사라지게 된다.```{=tex}\begin{equation}\label{eq-ch3-6}\tag{3.6} \Delta y_{it} = \Delta X_{it}\beta + \Delta\varepsilon_{it}\end{equation}```여기서 $\Delta$는 $\Delta y_{it} = y_{it} - y_{it-1}$ 등 시차에 따른 증가분을의미한다.- 식 \ref{eq-ch3-5}와 \ref{eq-ch3-6}을 비교해보면 $\alpha, \mu_i$가 소거된 것을 확인할 수 있다. 이들은 시간에 따라 변화하는 요인이 아니기 때문이다.- 모형 \ref{eq-ch3-5}에서 $X_{it}$가 $\varepsilon_{it}$에 대해서 강외생적이라고 하였으므로, 식 \ref{eq-ch3-6}의 $\Delta X_{it}\beta, \Delta\varepsilon_{it}$도 서로 독립적이다.- 또 \ref{eq-ch3-6}의 모수로는 $\beta$만 존재하며, 따름모수(incidental parameters)가 존재하지 않는다.그러므로 설명변수가 고유오차에 대해 강외생적일 때, $\Delta y_{it}$를$\Delta X_{it}$에 대하여 POLS 회귀하면, $\beta$가 일관되게 추정될 것이라 기대할수 있다(♔). 식 \ref{eq-ch3-6}에 대한 POLS 회귀를 1계차분(first difference, FD)회귀라고 한다.FD 추정값을 $\hat{\beta}_{fd}$라고 하자. FD 추정량은 차분방정식 \ref{eq-ch3-6}을추정한 것이므로 있는 그대로 해석하면 "$X_{it}$의 증가폭이 d만큼 더 크면$y_{it}$의 증가폭은 $d\hat{\beta}_{fd}$만큼 더 클 것이다"라고 할 수 있고, 이때'증가폭의 차이'로 해석되지만 \ref{eq-ch3-6}에 근거할 필요 없이 원래의 모형\ref{eq-ch3-5}에 의거해 "동일 개체 내에서 설명변수 값에 $\Delta x$만큼의 차이가있으면 종속변수 값에 $(\Delta x)\hat{\beta}_{fd}$"만큼의 평균적인 차이가 있는것으로 추정된다"고 해석해도 좋다.설명변수가 고유오차에 대하여 강외생적이면 설명변수의 시간에 따른변화분($\Delta X_{it}$)과 고유오차의 시간에 따른변화분($\Delta\varepsilon_{it}$)이 비상관이므로 FD 추정량은일관적(consistent)이다(♔). 하지만 $\Delta\varepsilon_{it}$에 시간에 걸친 상관이존재하는 것이 일반적이므로 견고한 표준오차를 사용할 필요가 있다(♖). 간단한방법은 클러스터 표준오차를 사용하는 것이다. R에서는 `{dplyr}` 패키지에서 `lag`함수를 이용해서 차분을 한 뒤 개체에 따른 클러스터 표준오차를 계산하면 된다.먼저 `id` 단위로 묶어준 다음에 각 변수의 시간변수에 따른 차분 변수를 만들어주는것이다. 예를 들어, 종속변수의 차분변수를 만들어준다면 다음과 같이 만들 수 있다:`data |> group_by(id) |> mutate(d_y = y - lag(y, n = 1, order_by = year) -> data`.모든 변수에 차분을 수행한 다음, 그 변수들을 이용해서 `{estimatr}` 패키지의`lm_robust` 함수를 이용해 로버트스 회귀분석을 통해 클러스터 표준오차를 구할 수있다.`model <- lm_robust(d_y ~ d_x1 + d_x2 + as.factor(year), data = data, clusters = id)`.POLS에서 클러스터 표준오차를 사용한 것처럼 `id`를 기준으로 클러스터 표준오차를사용하는 것이 중요하다. 이 경우에도 클러스터의 개수가 어느 정도 커야만 클러스터표준오차의 사용이 정당화된다.::: callout-tip시간더미들이 없는 모형에서는 1계차분에 의하여 절편이 소거된다(시간에 따라변화하지 않으니까). 1계차분했을 때 절편이 존재하는 모형은 시간더미들이 있거나아니면 $y_{it} = \alpha + X_{it}\beta + \gamma_t + \mu_i + \varepsilon_{it}$처럼선형추세가 있는 모형이다 [@hancirog2021: 82].:::고정효과를 갖는 패널 모형에서 개체 간 차이를 단순비교하면 종속변수 값의 차이가독립변수 값의 차이에 기인하는지 아니면 개별효과의 차이로 인한 것인지 불분명하다.FD회귀에서는 1계차분을 이용하여 개체별 특수성을 제거해버리므로 종속변수 값의평균적인 차이는 오로지 독립변수 값의 차이에 기인한다고 할 수 있다. 이로써독립변수가 종속변수에 미치는 영향을 식별할 수 있다.::: callout-note예제 3.4 인구구조와 총저축률(FD 추정)예제 2.5의 데이터와 모형에 대하여 FD 추정을 한 결과는 다음과 같다.```{r}#| echo: true#| warning: false#| message: falsepacman::p_load(plm, texreg, estimatr, ezpickr, tidyverse)wdi5bal <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/wdi5bal.dta")wdi5bal |>group_by(id) |>mutate(d_sav = sav - dplyr::lag(sav, n =1, order_by = year),d_age0_19 = age0_19 - dplyr::lag(age0_19, n =1, order_by = year),d_age20_29 = age20_29 - dplyr::lag(age20_29, n =1, order_by = year),d_age65over = age65over - dplyr::lag(age65over, n =1, order_by = year),d_lifeexp = lifeexp - dplyr::lag(lifeexp, n =1, order_by = year) ) |> dplyr::select(id, year, contains("d_")) -> d_wdi5balpanel_fd <-lm_robust(d_sav ~ d_age0_19 + d_age20_29 + d_age65over + d_lifeexp +as.factor(year), data = d_wdi5bal |>drop_na(),clusters = id)panel_fd |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```클러스터 표준오차를 사용함에 유의하라. RE 회귀와 비교하면, 우선 계수들에 약간씩차이가 있고, `lifeexp` 변수의 $p$-값이 증가하여 통계적 유의성이 낮아졌다. FD회귀의 $R^2$는 `r round(panel_fd$r.squared, 2)` 로 모형의 설명력이 매우낮다($\Delta y_{it}$의 변화량을 $\Delta X_{it}$가 설명하는 정도를 나타내는것으로 약 5.6% 만의 변동을 설명한다는 것이다). `lifeexp` 변수의 계수추정값인`r round(coef(panel_fd)[5], 3)`은 한 나라의 인구구조(설명변수로 포함된 다른변수들)이 일정할 때, 기대수명이 1세 차이나는 시기들 간 저축률에 약 0.4% 포인트차이가 있다고 해석된다.:::고정효과 모형에서 시간불변 변수들의 효과는 고정효과와 구별되지 않는다. 때문에고정효과 모형에서는 시간에 따라 변화하는 설명변수들만 우변에 포함된다. 만약시간불변 설명변수들을 우변에 포함시키고 FD 추정을 하면, 시간에 따른 변화가존재하지 않기 때문에 증가분이 0이므로 해당 변수들은 모두 소거되고 추정값이계산되지 않는다. 다음의 예제를 보자.::: callout-note예제 3.5 정규적 전환 효과의 FD 추정임금방정식 모형에 시간더미를 포함시키고 FD 추정을 하자.```{r}#| echo: true#| warning: false#| message: falseklipsbal <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/klipsbal.dta")klipsbal |>group_by(pid) |>mutate(d_lwage = lwage - dplyr::lag(lwage, n =1, order_by = year),d_educ = educ - dplyr::lag(educ, n =1, order_by = year),d_tenure = tenure - dplyr::lag(tenure, n =1, order_by = year),d_isregul = isregul - dplyr::lag(isregul, n =1, order_by = year),d_female = female - dplyr::lag(female, n =1, order_by = year),d_age05 = age05 - dplyr::lag(age05, n =1, order_by = year), ) |> dplyr::select(pid, year, contains("d_")) -> d_klipsbalpanel_fd_klipsbal <-lm_robust( d_lwage ~ d_educ + d_tenure +I(d_tenure^2) + d_isregul + d_female + d_age05 +I(d_age05^2) +as.factor(year), data = d_klipsbal |>drop_na(),clusters = pid)summary(panel_fd_klipsbal)panel_fd_klipsbal |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```2005년도 당시의 연령 `age05`와 여성 더미변수 `female`은 시간에 따라 변화하지않으므로 모두 회귀에서 제외된다. 정규적 여부를 나타내는 `isregul` 변수의 계수추정값은 예제 3.1의 BE 추정값(`r round(coef(panel_be)[5], 3)`)보다 훨씬 작은`r round(coef(panel_fd_klipsbal)[5], 3)`이다. 이는 여타 요소 통제 시 정규직노동자와 비정규직 노동자 간에는 상당한 임금 격차가 존재하지만, 동일 노동자의상태가 비정규직에서 정규직으로 바뀔 때의 임금 변화는 그보다 훨씬 작음을나타낸다.`d_educ`의 계수가 추정된 것은 `educ` 내 집단내 변동이 약간이라도 존재하는 것을의미한다. 총 11명에서 `educ` 변수의 값이 변하는 것을 확인할 수 있다.```{r}#| echo: true#| warning: false#| message: false#| results: asisklipsbal |>group_by(pid) |>mutate(sd_educ =sd(educ, na.rm = T)) |> dplyr::filter(sd_educ >0) |> dplyr::select(pid, year, educ) |>distinct() |> DT::datatable()``````{r}#| echo: false#| eval: true#| warning: false#| message: falseklipsbal |>group_by(pid) |>mutate(sd_educ =sd(educ, na.rm = T)) |> dplyr::filter(sd_educ >0) |> dplyr::select(pid, year, educ) |>distinct() |>pull(pid) |>unique() -> unique_pidpanel_fd_klipsbal_noeduc <-lm_robust( d_lwage ~ d_educ + d_tenure +I(d_tenure^2) + d_isregul + d_female + d_age05 +I(d_age05^2) +as.factor(year), data = d_klipsbal |>drop_na() |> dplyr::filter(!pid %in% unique_pid),clusters = pid)```결과에 따르면, 2명은 고졸 $\rightarrow$ 전문대졸, 3명은 고졸 $\rightarrow$(4년제) 대졸, 1명은 전문대졸 $\rightarrow$ 대졸, 나머지 5명은 대졸 $\rightarrow$석사로 표본기간 도중에 변경되었다. 모델에서 `d_educ`의 계수값은 이 11명의 변동내역에 따라 추정된 값이다. 만약 이 11명을 분석에서 제외하면 `d_educ`는 소거되고`isregul`의 계수 추정값은 `r round(coef(panel_fd_klipsbal_noeduc)[5], 3)`로 약간바뀐다.:::::: callout-note연습 3.5. 표본기간 내에 `educ` 값이 변하지 않은 개인들만을 대상으로 본 예제의모형을 추정하여 `isregul` 변수의 계수 추정값이 `0.875957`임을 확인하라.```{r}#| echo: false#| warning: false#| message: falseklipsbal |>group_by(pid) |>mutate(sd_educ =sd(educ, na.rm = T)) |> dplyr::filter(sd_educ >0) |> dplyr::select(pid, year, educ) |>distinct() |>pull(pid) |>unique() -> unique_pid``````{r}#| echo: true#| eval: true#| warning: false#| message: falsepanel_fd_klipsbal_noeduc <-lm_robust( d_lwage ~ d_educ + d_tenure +I(d_tenure^2) + d_isregul + d_female + d_age05 +I(d_age05^2) +as.factor(year), data = d_klipsbal |>drop_na() |> dplyr::filter(!pid %in% unique_pid), # unique_pid 는 변동값을 가지는 11명의 id이다.clusters = pid)summary(panel_fd_klipsbal_noeduc)panel_fd_klipsbal_noeduc |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```:::FD 회귀에서 2중 클러스터 분산추정은 1계차분한 오차항$\Delta u_{it} = \Delta\varepsilon_{it}$에 임의의 시계열 상관과 임의의 동시기횡단면 상관(동시상관)을 허용하는 분산추정 방법이다. R 에서는 `{AER}`의 `ivreg`함수에서 `type = "HC0", vcov. = sandwich::vcovHC, cluster = id` 옵션을 부여하여이를 수행할 수 있다. 그런데 이 경우는 소표본 자유도 조정을 하지 않은 결과라서,소표본 자유도 조정한 FD 회귀 2중 클러스터 분산추정을 하고 싶다면 `{fixest}`패키지의 `feols` 함수의 `ssc = ssc(fixef.K = "full")` 옵션을 이용하여 추정할 수있다.```{r}#| echo: true#| warning: false#| message: falsetwowaycl <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/twowaycl.dta")twowaycl |>group_by(id) |>mutate(d_y = y - dplyr::lag(y, n =1, order_by = year),d_x1 = x1 - dplyr::lag(x1, n =1, order_by = year),d_x2 = x2 - dplyr::lag(x2, n =1, order_by = year),d_after = after - dplyr::lag(after, n =1, order_by = year) ) |> dplyr::select(id, year, contains("d_")) -> d_twowaycllibrary(lmtest)twoway_fdcl <-coeftest( AER::ivreg(d_y ~ d_x1 + d_x2 + d_after, data= d_twowaycl),type ="HC0", vcov. = sandwich::vcovHC, cluster = id)twoway_fdcl |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)library(fixest)twoway_fdest <-feols(d_y ~ d_x1 + d_x2 + d_after, d_twowaycl, ~id + year, ssc =ssc(fixef.K ="full"))summary(twoway_fdest)twoway_fdest |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```원래의 고유오차 $\varepsilon_{it}$ 가 IID인 상황에서도 식 \ref{eq-ch3-6}의오차항 $\Delta \varepsilon_{it}$는 시계열 상관을 보이므로 FD 추정량은 BLUE가아니다(♖). 이 경우, $\varepsilon_{it}$가 IID라는 **특정한 가정하에서** GLS를 할수 있다. 그 가정하에서 공분산의 구조는$$\mathrm{E}[(\Delta \varepsilon_{it})^2] = 2\sigma^2_\varepsilon, \:\: \mathrm{E}[(\Delta \varepsilon_{it})(\Delta \varepsilon_{it-1})]=-\sigma^2_\varepsilon$$이고 그 밖의 공분산은 모두 0이다. 여기서 $\sigma^2_\varepsilon$은 공통의스칼라이므로 무시할 수 있고, 따라서 FGLS가 아니라 GLS를 할 수 있는데, 그 결과는다음 3.4절의 고정효과(FE) 회귀와 동일하다.## 고정효과 회귀앞에서는 1계차분을 이용해 개별효과를 제거하는 방법을 살펴보았다. 이제는 각개체별로 평균값을 빼서 개별효과를 제거하는 방법을 생각해 보자. 다음의 첫 번째식에서 각 $i$별로 평균($t$에 걸친 표본평균)을 구하면 두 번째 식이 된다.$$y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}\\\bar{y}_i = \alpha + \bar{X}_i\beta + \mu_i + \bar{\varepsilon}_i$$여기서 $\bar{y}_i = T^{-1}\sum^T_{t=1}y_{it}$이고 $\bar{X}_i$와$\varepsilon_i$도 이와 마찬가지로 정의된다. 불균형패널일 경우에는 $T$를 $T_i$로바꾸면 된다(개체별로 시계열의 종료 시점이 다를테니까). 첫 번째 식에서 두 번째식을 빼면 다음의 식을 얻는다.```{=tex}\begin{equation}\label{eq-ch3-10}\tag{3.10} y_{it} - \bar{y}_i = (X_{it}-\bar{x}_i)\beta + (\varepsilon_{it}-\bar{\varepsilon}_i)\end{equation}```여기서도 $\mu_i$가 소거된다. 식 \ref{eq-ch3-10} 을 POLS하는 것을집단내(within-group, WG) 회귀 또는 고정효과(fixed effects, FE) 회귀라고 한다.'집단내'라는 수식어가 붙는 것은 식 \ref{eq-ch3-10} 에서 $y_{it}-\bar{y}_i$와$X_{it}-\bar{X}_i$를 해당 변수들의 집단내(within-group) 편차라고 하는 것과도관련된다. '고정효과 회귀'라는 이름은 원래 $\mu_i$들을 고정된 모수로 간주한다는것으로부터 유래하였으나, 이보다는 '집단내 편차들을 이용한 OLS'라고 받아들이는편이 혼동을 줄일 수 있을 것이다.::: callout-note수학적 증명을 요구하는 연습문제 3.6과 3.7을 여기서 따로 풀이하지 않는다.:::FE 회귀가 식 \ref{eq-ch3-10} 에 대하여 POLS를 하는 것이기는 하지만 식\ref{eq-ch3-10} 에 맞추어 결과를 해석할 필요는 없다. FD 추정값의 경우처럼 FE추정값 $\hat{\beta}_{fe}$을 해석하기 위해서는 원래 FE 모형으로 돌아가서 "동일개체 내에서 설명변수 값에 $\Delta x$만큼의 차이가 있으면 종속변수 값에 평균$(\Delta x)\hat{\beta}_{fe}$만큼의 차이가 있는 것으로 추정된다"고 해석하면 된다.독립변수가 `x1, x2`이고 종속변수가 `y`일 때, R에서 시간더미들을 포함하여 FE추정을 하려면 `{plm}` 패키지의 함수에서 `model = "within` 옵션을 사용한다.`plm(y ~ x1 + x2 + as.factor(year), data = data, model = "within", index = c("id", "year")`- 연구자의 재량에 따라 시간더미가 필요없다고 판단되면 `as.factor(year)`를 삭제하면 되지만 그 이유를 잘 성명하여야 한다.- `x1, x2`는 시간에 따라 변화하는 변수들이다. 시간에 걸쳐 변하지 않는 변수의 경우에는 그 개체별 평균을 빼면 모든 $i$와 $t$에서 0이 되므로 모형으로부터 소거되어 버린다. 이 때문에 $X_{it}$에는 시간에 따라 변화하는 설명변수들만 있어야 한다.앞에서 설명하였듯이, FE 회귀는 회귀식을 \ref{eq-ch3-10} 으로 변형하여 POLS를하는 것이다. 그런데 \ref{eq-ch3-10}의 오차항에는 $\bar{\varepsilon}_i$가포함되어 있으므로, 고유오차 $\varepsilon_{it}$가 IID이건 아니건 간에 상관없이최종 회귀식 오차항인 $\varepsilon_{it} - \bar{\varepsilon}_i$는 시계열 상관을갖는다. OLS로 추정할 회귀식의 오차항에 시계열 상관이 있을 대에는 견고한표준오차를 사용하여야 한다(♖). FE 회귀에서 집단내 편차들로 표현된 회귀식의오차항 $\varepsilon_{it}-\bar{\varepsilon}_i$도 시계열 상관을 갖기 때문에표준오차 계산 시 이를 고려하여야 한다.::: callout-note연습 3.8. $T=3$이라 하자.$\varepsilon_{i1}, \varepsilon_{i2}, \varepsilon_{i3}$이 IID이고 평균이 0,분산이 1이라면 $\varepsilon_{it}-\bar{\varepsilon}_i$의 분산은 무엇인가? 그 경우$\varepsilon_{i1}-\bar{\varepsilon}_i$와$\varepsilon_{i2}-\bar{\varepsilon}_i$의 공분산은 무엇인가? 단,$\bar{\varepsilon}_t = \frac{1}{3}(\varepsilon_{i1}+\varepsilon_{i2}+\varepsilon_{i3})$.Ans:```{=tex}\begin{equation}\begin{aligned} \varepsilon_{i1}-\bar{\varepsilon}_i & = \varepsilon_{i1} - \frac{1}{3}(\varepsilon_{i1}+\varepsilon_{i2}+\varepsilon_{i3})\\ & = \frac{2}{3}(\varepsilon_{i2}-\frac{1}{3}\varepsilon_{i1}-\frac{1}{3}\varepsilon_{i3})\end{aligned}\end{equation}``````{=tex}\begin{equation}\begin{aligned} \varepsilon_{i2}-\bar{\varepsilon}_i & = \frac{2}{3}(\varepsilon_{i2}-\frac{1}{3}\varepsilon_{i1}-\frac{1}{3}\varepsilon_{i3})\end{aligned}\end{equation}``````{=tex}\begin{equation}\begin{aligned} \varepsilon_{i3}-\bar{\varepsilon}_i & = \frac{2}{3}(\varepsilon_{i3}-\frac{1}{3}\varepsilon_{i1}-\frac{1}{3}\varepsilon_{i2})\end{aligned}\end{equation}```이므로 $\varepsilon_{i1}-\bar{\varepsilon_i}$의 분산은$\frac{4}{9} + \frac{1}{9} + \frac{1}{9} + \frac{6}{9} = \frac{2}{3}$이고,나머지 두 개의 분산도 이와 동일하다. 따라서$\mathrm{cov}(\varepsilon_{i1}-\bar{\varepsilon}_i, \varepsilon_{i2}-\bar{\varepsilon}_i) = -\frac{2}{9} - \frac{2}{9} + \frac{1}{9} = -\frac{1}{3}$이된다.:::고유오차항 $\varepsilon_{it}$가 IID인 경우 FE 추정량의 분산은 특수한 형태를갖는다. @hancirog2021 [91-92]는 $\varepsilon_{it}$가 IID일 때, FE 추정량의표준오차를 구하기 위한 자유도 조정을 수학적으로 도출하는 방법을 보여주고 있다.::: callout-note예제 3.7 인구구조와 총저축률 (FE 회귀)다음 결과는 예제 2.5의 저축률 모형을 FE 회귀로 추정한 것이다.```{r}#| echo: true#| warning: false#| message: falsewdi5bal_fe <- plm::plm(sav ~ age0_19 + age20_29 + age65over + lifeexp +as.factor(year),model ="within", index =c("id", "year"),data = wdi5bal)summary(wdi5bal_fe)wdi5bal_fe |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)````lifeexp`의 계수 추정값인 `r round(coef(wdi5bal_fe)[4], 3)`은 "동일 국가 내에서시간에 걸쳐 `age0_19`, `age20_29`, `age65over`가 일정하고 기대수명에 1년 차이가있으면 총저축률에 평균적으로 약 0.74% 포인트의 차이가 있는 것으로 추정된다"고해석된다. 개별효과와 설명변수 간에 상관관계(횡단면 상관관계)가 있으면 FE추정값과 RE 추정값 사이에 상당한 차이가 있는 것이 당연하고, FE 추정값과 FD추정값은 모두 고정효과 모형의 모수 추정값이므로 유사하여야 한다.- 그런데 이 결과를 예제 2.5(RE 회귀) 및 예제 3.4(FD 회귀)의 결과와 비교하면`lifeexp`의 FE 계수 추정값(`.743`)은 FD 추정값(`435`)보다 오히려 RE 추정값(`.554`)에 가깝다.- FD 회귀와 FE 회귀가 모두 고정효과 모형을 일관되게 추정하므로 FE 회귀 결과가 FD 회귀 결과보다 RE 회귀 결과와 유사한 것이 약간 당혹스러우나, 적어도 추정값들의 부호가 동일하고 또 RE 추정값이 FE 추정값과 유사한 경우도 있으므로 완전히 잘못된 결과라고 보기는 어렵다 [@hancirog2021: 94] .:::FE 회귀에서, 만약 $\varepsilon_{it}$에 이분산이나 시계열 상관이 있으면 FE추정량은 여전히 일관적이지만(♔) 통상적인 표준오차들은 타당하지 않다(♖). 이경우에도 가장 손쉬운 방법은 **클러스터 표준오차**를 사용하는 것이다.- 클러스터 표준오차는 동일한 $i$로 이루어진 관측치들을 하나의 클러스터로 는 것으로써, 클러스터 개수인 $n$이 (충분히) 크기만 하다면 $\varepsilon_{it}$에 임의의 이분산이 있고 $t$에 걸쳐 어떤 상관이 있어도 사용할 수 있는 편리한 것이다. 다음의 예제를 보라.::: callout-note예제 3.8 인구구조와 총저축률(FE 회귀, 견고한 표준오차)예제 3.7의 추정량에 대하여 견고한(클러스터) 표준오차를 계산하도록 하면 다음결과를 얻는다.```{r}#| echo: true#| warning: false#| message: falsewdi5bal_fe_robust <- plm::plm(sav ~ age0_19 + age20_29 + age65over + lifeexp +as.factor(year),model ="within", index =c("id", "year"),data = wdi5bal)coeftest(wdi5bal_fe_robust, vcov. = vcovHC, type="HC1") |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```통상적인 표준오차를 사용하는 경우와 비교하면 계수 추정값은 동일하나 표준오차가변경되었다. 이 예제에서는 클러스터 표준오차를 사용하여도 시간더미들을 제외하면유의성면에서 결과를 바꿀만한 차이가 없다. 다른 분석에서는 통계적 유의성이 달라질수도 있다.FE 회귀를 견고한 표준오차(robust standard errors)로 추정했을 경우, STATA의`xtreg y x1 x2, fe vce(robust)` 결과와 소수점 단위에서 살짝 다른 것을 확인할 수있다. 크게 두 가지 이슈를 생각해볼 수 있다.1. 클러스터-견고한 공분산 추정방법의 문제이다. STATA에서`vce(cluster <groupvar>)` 또는 `vce(robust)`로 추정하는 것은 R에서는 위에서의 재현 코드와 같이 `vcovHC`의 오차 유형 중`method = "arellano", type = "HC1"`로 재현할 수 있다.2. 소표본 조정(small sample correction)의 문제인데, 이 부분은 STATA와 R이 조금 다르다.STATA에서는 $G$가 클러스터의 수이고 $N$이 관측치의 수라고 할 때, 소표본 조정을위해 잔차에 가중치를 $\sqrt{G/(G-1)\times(N-1)/(N-K))}$로 부여한다[@cameron2006: 8]. 한편, R의 `{plm}`의 오차유형 HC0부터 HC4는 클러스터를고려하지 않은 소표본 조정 방식을 취한다 [@zeileis2004].따라서 현재로 R과 STATA 간의 호환을 고려해볼 때, `type = "HC1"`가 가장 유사한결과를 얻을 수 있는 옵션이라고 할 수 있다.:::FD 회귀처럼, 시간에 따라 변하지 않는 설명변수들은 FE 회귀 시 소거된다. 이는 FE회귀가 동일 개체 내에서 시간에 따른 변화만을 고려하기 때문이다. 다음 예제에서는정규직 전환의 효과를 FE 회귀로써 추정한다. 결과가 깔끔한 모양을 갖도록 하기위하여 시간불변 설명변수들은 모형에서 미리 제외시킨다.::: callout-note예제 3.9 정규직 전환 효과의 FE 회귀임금방정식 모형에서 시간불변 설명변수들을 제외시킨 다음 시간더미들을 포함시키고FE 회귀를 하자. 견고한 표준오차를 사용한다.```{r}#| echo: true#| warning: false#| message: falseklipsbal <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/klipsbal.dta")klipsbal_fe_robust <- plm::plm(lwage ~ educ + tenure +I(tenure^2) + isregul +as.factor(year),model ="within", index =c("pid", "year"),data = klipsbal)coeftest(klipsbal_fe_robust, vcov. = vcovHC, type="HC1") |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```2005년도 당시의 연령 `age05`와 여성 더미변수 `female`은 시간에 따라 변하지않으므로 회귀에서 제외되었다. 정규직 여부를 나타내는 `isregul` 변수의 계수추정값은 예제 3.1의 BE 추정값(`0.3315`)나 예제 2.1의 POLS 추정값(`.2717`)보다훨씬 작은 `.1247`로, FD 추정값(`.0864`)보다 약간 더 크다. 이 또한 여타 요소 통제시 정규직 노동자와 비정규직 노동자 간에는 상당한 임금 격차가 있으나, 동일노동자의 상태가 비정규직인 시기와 정규직인 시기 간 임금차이는 그보다 훨씬 작음을나타낸다.:::FE 회귀에서도 2중 클러스터 분산추정이 가능하다.- 1단계:`model_fecl <- plm(y ~ x1 + x2, data = data, index = c("id", "year"), model = "within", effect = "individual")`- 2단계:`coeftest(model_fecl, vcov = vcovHC(model_fecl, type = "HC0", cluster = "time"))`STATA와 R로 계산한 표준오차 결과가 소수점 셋째 자리에서 약간 다르게 나타나는것은 알 수 있으나, 이 차이는 사소하다고 할 수 있다.::: callout-note예제 3.10 FE 회귀에서 2중 클러스터 분산추정FE 회귀에서 2중 클러스터 분산추정을 연습하자.```{r}#| echo: true#| warning: false#| message: falselibrary(lmtest)twoway_fecl <- plm::plm(y ~ x1 + x2 + after, data= twowaycl,index =c("id", "year"),model ="within", effect ="individual")coeftest(twoway_fecl, vcov =vcovHC(twoway_fecl, type ="HC0", cluster ="time")) |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)```앞서 언급한 바와 같이 소표본 조정 방식의 차이로 인해 표준오차의 결과가 미세하게다르다고 이해할 수 있다.:::한편, $\varepsilon_{it}$에 이분산이나 시계열 상관이 있을 때에는 FE 추정량보다 더나은 선형 비편향 추정량이 존재한다(♖). $n$이 크고 $T$가 작으면 FGLS추정량("고정효과 FGLS"이라 하며 WG 변환 후 FGLS를 하면 된다)을 어렵지 않게 구할수 있으나, $T$가 크면 계산이 불가능하거나 그 성질이 매우 나쁠 수 있고, FE 회귀가일종의 표준적인 방법으로 간주되어 실제 연구에서 고정효과 FGLS가 많이 사용되지는않는다.### FE 회귀와 관련된 잔차들FE 추정으로부터 여러 종류의 잔차들(residuals)을 구할 수 있으며, 아무 설명 없이그냥 "잔차"라고만 하면 무엇을 의미하는지 알아듣지 못할 수 있다. 잔차의 종류에대해 구체적으로 살펴보자.- **잔차의 집단내 편차(집단내 잔차)** - 식 \ref{eq-ch3-10} 에 따라 $y_{it}-\bar{y}_i$를 $X_{it}-\bar{X}_i$에 대하여 회귀하여 구하는 잔차 - $\hat{\beta}$이 FE 추정량이라 할 때, 이 잔차는 $(y_{it}-\bar{y}_i)-(X_{it}-\bar{X}_i)\hat{\beta}$이다. - 이 잔차는 $u_{it}$에도, $\varepsilon_{it}$에도 정확히 해당되지 않는다. - 잔차 공식에서 $\hat{\beta}$를 $\beta$로 치환하고 식을 재정렬해보면, 이 잔차는 $(y_{it}-X_{it}\beta) - (\bar{y}_i-\bar{X}_i)\beta$를 추정한 것에 해당된다. - $y_{it} = \alpha + X_{it}\beta + \mu_i + \varepsilon_{it}$와 $\bar{y}_{i} = \alpha + \bar{X}_i\beta + \mu_i + \bar{\varepsilon}_i$에 의하여, 이는 $(\alpha + \mu_i + \varepsilon_{it}) - (\alpha + \mu_i + \bar{\varepsilon_i}) = \varepsilon_{it} - \bar{\varepsilon}_i$가 된다. - **즉, FE 회귀로부터의 잔차(집단내 편차들의 OLS 잔차)가 추정하는 대상은** $\varepsilon_{it} - \bar{\varepsilon}_i$로 고유오차의 집단내 편차이다. - 이 고유효과의 집단내 편차는 총오차 $u_{it}$의 집단내 편차($u_{it}-\bar{u}_i$)와도 같다. - 집단내 편차들을 집단내에서 합산하면 반드시 0이 되므로, 각각의 개체($i$)에서 집단내 잔차들의 집단내 합은 반드시 0이다. - $\text{각 }i\text{마다}\sum^{T}_{t=1}\text{(집단내 잔차)}_{it} = 0$- **총잔차:** $u_{it} = \mu_i + \varepsilon_{it}$- **개별 평균 잔차** - $\mu_i$에 해당하는 잔차로 총잔차의 개체별 평균 - $\hat{u}_{it}$를 총잔차 라고 할 때, $T^{-1}\sum^T_{t=1}\hat{u}_{it}$를 $\mu_i$의 추정값으로 간주. - 엄밀하게는 $\mu_i + \bar{\varepsilon}_i$많은 논문들에서 변수의 집단내 편차에 대해서는 "틸드($\sim$)" 부호를 붙여서표기한다.- 예를 들어, $y_{it}-\bar{y}_i = \tilde{y}_{it}$, $X_{it}-\bar{X}_i = \tilde{X}_{it}$로 표기한다.- $\bar{u}_{it}$ 또는 $\bar{\varepsilon}_{it}$에 대한 잔차는 $\hat{\bar{u}}_{it}$나 $\hat{\bar{\varepsilon}}_{it}$로 나타내기도 한다.고정효과 추정 시 나타날 수 있는 잔차들은 다음과 같다.| 이름 | 정의 ||----------------|------------------------------------------------------------------------------|| 총잔차 | $\bar{u}_{it} = y_{it} - \hat{\alpha} - X_{it}\hat{\beta}$ || 개별 평균 잔차 | $\hat{\bar{u}}_{i} = \bar{y}_{i} - \hat{\alpha} - \bar{X}_{i}\hat{\beta}$ || 집단내 잔차 | $\hat{\bar{u}}_{it} = \bar{y}_{it} - \hat{\alpha} - \bar{X}_{it}\hat{\beta}$ |: 고정효과 추정 시 잔차들이 중 집단내 잔차는 R에서 `residuals(model)`로 구할 수 있지만 나머지 잔차는손으로 직접 구해야 한다. 아래는 저축 예제에 대한 고정효과 모델의 잔차들을 구해본것이다.```{r}#| echo: true#| warning: false#| message: falsewdi5bal_fe <- plm::plm(sav ~1+ age0_19 + age20_29 + age65over + lifeexp,model ="within", index =c("id", "year"),data = wdi5bal)broom::augment(wdi5bal_fe) |>bind_cols(wdi5bal |> dplyr::select(ccode, id, year)) |> dplyr::select(ccode, id, year, everything()) -> id_year_wdi5balwdi5bal |>summarize(m_age0_19 =mean(age0_19),m_age20_29 =mean(wdi5bal$age20_29),m_age65over =mean(wdi5bal$age65over), m_lifeexp =mean(wdi5bal$lifeexp)) -> sum_wdi5balbar_x <-rbind( sum_wdi5bal$m_age0_19, sum_wdi5bal$m_age20_29, sum_wdi5bal$m_age65over, sum_wdi5bal$m_lifeexp)id_year_wdi5bal |>left_join( plm::fixef(wdi5bal_fe) |>data.frame() |>rownames_to_column() |>rename(id = rowname, intercept ="plm..fixef.wdi5bal_fe.") |>mutate(id =as.numeric(id))) -> id_year_wdi5balid_year_wdi5bal |>mutate(m_sav =mean(sav),barXbeta =coef(wdi5bal_fe)%*%bar_x,uhat = intercept + barXbeta - m_sav,ehat = .resid,uehat = uhat + ehat ) |> dplyr::select(uehat, ehat, uhat) |>mutate_if(is.numeric, round, 3) |> DT::datatable()```### FE 회귀 시 예측값집단내 회귀를 할 때 $y_{it}$의 예측값(fitted values)[^chapter3-4]이라고 하면 두가지 의미가 있을 수 있다.[^chapter3-4]: @hancirog2021 은 맞춘값이라고 명기하고 있으나, 여기서는 예측값으로 적었다.1. $\hat{\alpha}+X_{it}\hat{\beta}$으로 계산되는 예측값 (`Xb예측값`) - 각 개체별 수준 차이를 고려하지 않는다.2. $\hat{\alpha}+X_{it}\hat{\beta}+\hat{u}_i$로 계산되는 예측값 (`Xbu예측값`) - 개체별로 예측값의 수준을 조정하여 실제값과 예측값의 평균적인 수준 차이가 없도록 만든 것`Xbu예측값` - `Xb예측값` = $\hat{\mu}_i$가 된다.::: callout-note예제 3.11 다양한 예측값다음 예를 보자. @grunfeld1958 의 원래 데이터를 가공한 10개 회사의 20년패널데이터(`grunfeld.dta`)를 이용하여 FE 회귀를 하고 `Xb예측값`과 `Xbu예측값`을구한다. 종속변수는 기업의 투자(`invest`), 독립변수는 해당 기업의시장가치(`mvalue`)와 자본스톡(`kstock`)이다. 변수들에 로그값을 취하는 것이좋겠지만 여기서는 분석을 용이하게 하기 위하여 원변수로 모델에 퉁칩한다.```{r}#| echo: false#| warning: false#| message: false#| fig-width: 9#| fig-height: 4#| label: fig-ch3-1#| fig-cap: "Grunfeld (1958) 자료에서 Xb예측값과 Xbu예측값"grunfeld <-pick("http://econ.korea.ac.kr/~chirokhan/panelbook/data/grunfeld.dta")grunfeld_fe <- plm::plm(invest ~ mvalue + kstock,model ="within", data = grunfeld,index =c("company", "year"))grunfeld_fe |>screenreg(digits =4, include.ci =FALSE, single.row =TRUE, include.rsquared =TRUE, include.adjrs =TRUE)ggthemr::ggthemr("fresh")grunfeld |>bind_cols( broom::augment(grunfeld_fe) |> dplyr::select(.fitted, .resid)) |>mutate(lp = plm::fixef(grunfeld_fe)[2] +t(coef(grunfeld_fe)%*%rbind(grunfeld$mvalue,grunfeld$kstock)) -mean(invest)) |> dplyr::filter(company %in% 2L) |>ggplot(aes(x = year)) +geom_path(aes(y = .fitted, color ="Xb + u[company]"), linetype ="dotted") +geom_path(aes(y = invest, color ="invest (actual value)")) +geom_path(aes(y = lp, color ="Linear prediction"), linetype ="dashed") +labs(x ="Year", y =NULL) +theme(legend.position ="bottom",legend.background =element_blank(),legend.title =element_blank())```@fig-ch3-1 에서 나타난 `Xbu예측값`과 `Xb예측값`의 차이가 해당 회사(2번 회사)의개별 효과 추정값인 $\hat{\mu}_2$이다. 그림에서 2번 회사의 개별효과 추정값은0보다 크다( $\hat{\mu}_2 > 0$):::### 개체 수가 적은 패널에서 FE 추정량의 성질$n$이 작고 $T$가 큰 경우 FE 추정량은 어떤 성질을 갖는가? POLS와는 달리 FD나 FE회귀에서는 $\mu_i$가 애초에 소거되기 때문에 추정값의 불확실성으로 인한비일관성의 문제가 없다. 설명변수 $X_{it}$에 시간에 따른 변화가 충분히 존재하기만한다면, 고정효과 추정량들은 $n$이 증가하든 $T$가 증가하든 관계없이 모수의참값으로 수렴할 것이라고 기대할 수 있다. 단, 이 경우 설명변수에 집단간 차이만크고 집단내 변동이 작으면 FD나 FE 추정량의 분산은 클 수 있다.### 시기별 효과시기별 효과는 시간더미로 처리할 수 있다. $n$이 크고 $T$가 작은 패널 데이터의경우 시간더미의 개수도 적으므로 문제가 되지 않는다. 반면에 $n$이 작고 $T$가 큰경우에는 시간더미의 개수가 많아 그 계수들이 따름모수가 되어 주의하여야 한다.$$y_{it} = \alpha + X_{it}\beta + \mu_i + \delta_t + \varepsilon_{it}$$이 2원(two-way) 고정효과 모형에서 $\mu_i$와 $\delta_t$를 동시에 소거하려면개체별 평균을 빼는 변환(within-group 변환)을 한 후 시간대별 평균을 빼는변환(within-period 변환)을 재차 해주면 될 것이다. 구체적으로, 개체별 평균을 빼면다음의 식을 얻는다.$$y_{it} - \bar{y}_i = (X_{it}-\bar{X}_i)\beta + (\delta_t - \bar{\delta}) + (\varepsilon_{it}-\bar{\varepsilon}_i)$$이 식의 양 변에서 각 시간대($t$)별로 $i$에 걸친 평균을 빼면 다음을 얻는다.$$(y_{it} - \bar{y}_i)-(y_{\cdot t} - \bar{\bar{y}}) =[(X_{it}-\bar{X}_i)-(X_{\cdot t}-\bar{\bar{X}})]\beta + [(\varepsilon_{it}-\bar{\varepsilon}_i)-(\varepsilon_{\cdot t}-\bar{\bar{\varepsilon}})]$$여기서 $\bar{y}_{\cdot t} = \frac{1}{n}\sum^n_{i=1}y_{it}$이고$\bar{\bar{y}}=\frac{1}{nT}\sum^{T}_{t=1}y_{it}$이며, 나머지 $\bar{X}_{\cdot t}$등의 기호도 이와 동일한 방식으로 정의된다. 이렇게 개별효과와 시간대별 효과를모두 소거한 다음 POLS를 하면 되는데, 이 추정법은 시간더미를 우변에 포함시키고 FE추정을 하는 것과 완전히 동일하다. $T$가 크더라도 시간더미들을 우변에 포함시키는것이 문제를 야기하지 않는다.### 집단내 변동이 작은 경우$X_{it}$에 시간에 걸친 변동이 별로 없다면 FD와 FE 추정량의 분산은 매우 클 수있다.- 극단적으로 만약 $X_{it}$가 시간에 걸쳐 변하지 않는다면 시간에 따른 변화량이나 평균 모두 0으로 소거되어 버리므로 $\beta$의 추정이 불가능하다.- 극단적인 경우는 아니더라도 만약 $X_{it}$가 개체 간 상당한 차이가 있지만 동일 개체 내에서 변하는 정도가 매우 작다면, FE 추정값이나 FE 추정값이 계산될지라도, 설명변수의 집단내 변동이 제한되어 추정량의 정확성은 현저히 떨어질 수 있다. - 이런 경우 흔히 표준오차가 매우 크고 $t$-값이 작으며 $p$-값이 커서 변수들이 유의하지 않는 일이 발생한다. 이는 FD나 FE 추정의 불가피한 비용이다. - POLS와 RE 회귀는 $i$에 걸친 변동도 이용하므로 이러한 문제가 없었다. 반면 POLS 추정량과 RE 추정량은 개별효과가 고정효과일 때 일관적이지 않다는 더 심각한 문제가 있다.::: callout-note예제 3.12 집단내 변동과 집단간 차이`wdi5bal.dta` 데이터에서 `lifeexp` 변수는 집단간 차이에 비하여 집단내 변동이작다.```{r}#| echo: false#| warning: false#| message: false#| results: asisXTSUM <-function(data, varname, unit) { varname <-enquo(varname) loc.unit <-enquo(unit) ores <- data |>summarise(Mean=mean(!! varname, na.rm=TRUE), sd=sd(!! varname, na.rm=TRUE), min =min(!! varname, na.rm=TRUE), max=max(!! varname, na.rm=TRUE), N=sum(as.numeric((!is.na(!! varname))))) bmeans <- data |>group_by(!! loc.unit) |>summarise(meanx=mean(!! varname, na.rm=T), t.count=sum(as.numeric(!is.na(!! varname)))) bres <- bmeans |>ungroup() |>summarise(sd =sd(meanx, na.rm=TRUE), min =min(meanx, na.rm=TRUE), max=max(meanx, na.rm=TRUE),n=sum(as.numeric(!is.na(t.count))),`T-bar`=mean(t.count, na.rm=TRUE)) wdat <- data |>group_by(!! loc.unit) |>mutate(W.x =scale(!! varname, center=TRUE, scale=FALSE)) wres <- wdat |>ungroup() |>summarise(sd=sd(W.x, na.rm=TRUE), min=min(W.x, na.rm=TRUE), max=max(W.x, na.rm=TRUE))# Loop to adjust the scales within group outputs against the overall meanfor(i in2:3) { wres[i] <-sum(ores[1], wres[i]) }# Table OutputVariable <-matrix(c(varname, "", ""), ncol=1)Comparison <-matrix(c("Overall", "Between", "Within"), ncol=1)Mean <-matrix(c(ores[1], "", ""), ncol=1)Observations <-matrix(c(paste0("N = ", ores[5]), paste0("n = ", bres[4]), paste0("T-bar = ", round(bres[5], 4))), ncol=1)Tab <-rbind(ores[2:4], bres[1:3], wres[1:3])Tab <-cbind(Tab, Observations)Tab <-cbind(Mean, Tab)Tab <-cbind(Comparison, Tab)Tab <-cbind(Variable, Tab)# Outputreturn(Tab)}XTSUM(wdi5bal, lifeexp, id) |>mutate_if(is.numeric, round, 2) -> xtsumxtsum$Mean[[1]] <-round(xtsum$Mean[[1]], 2)DT::datatable(xtsum)``````{r}#| echo: true#| warning: false#| message: falsere <- plm::plm(sav ~ age0_19 + age20_29 + age65over + lifeexp +as.factor(year), data = wdi5bal, model ="random",index =c("id", "year"))re_robust <-coeftest(re, vcovHC(re, type ="HC1", cluster ="group"))fe <- plm::plm(sav ~ age0_19 + age20_29 + age65over + lifeexp +as.factor(year), data = wdi5bal, model ="within",index =c("id", "year"))fe_robust <-coeftest(fe, vcovHC(fe, type ="HC1", cluster ="group"))screenreg(list(re_robust, fe_robust), custom.model.names =c("RE", "FE"),custom.coef.map =list("lifeexp"="lifeexp"),digits =4, include.ci =FALSE, single.row =FALSE, include.rsquared =TRUE, include.adjrs =TRUE)````lifeexp`에 대한 RE 모델과 FE 모델 간의 추정값과 클러스터 표준오차를 비교하였다.`lifeexp` 계수의 RE 추정량의 표준오차는 약 0.1145임에 비하여, 동일 모델에 대한FE 추정량이 클러스터 표준오차는 0.2421로 두 배 이상이다.:::### 표준오차에 관한 부연설명### 집단내 FGLS 추정## 더미변수 회귀## LSDV와 FE 회귀의 관계## 계수의 해석과 모형 비교### 추정량들 간의 수학적 관계### 그림을 이용한 추정량들의 비교## 상관된 임의효과## 고정효과 대 임의효과 검정### 회귀를 이용한 방법### 하우스만 검정### 고정효과 대 임의효과 검정에 관한 추가 주제들## Hausman과 Taylor의 모형### HT의 상세한 추정 절차### 특수 경우들